Lecture 01 课程概览与介绍
1. 课程介绍
1.1 预备知识
- 本课程要求先修以下两门课程中的任意一门:
- 阅读材料:Natural Language Processing by Jacob Eisenstein
- Probability: Appendix A
- Optimisation: Appendix B
- Linear classifiers: Chapter 2
- Neural networks: Chapter 3
- Python 编程经验
- 不需要具备语言学或者高等数学知识
- 注意:本课程不属于 “普通” 计算机科学
- 涉及一些基本 语言学,例如:句法和词法
- 需要 数学,例如:代数、优化、线性代数、动态规划
1.2 期望与结果
- 期望
- 提高 Python 技能
- 保持阅读进度
- 课堂参与
- 结果
- 从实践中熟悉各种文本分析技术
- 了解这些工具背后的理论模型
- 阅读相关研究文献的能力
1.3 作业与考试
- 作业(占总成绩的 20%,每个作业占 6-7%)
- 基于研讨会的小型作业
- 每隔几周发布一次,每个作业会给 2-3 周时间完成
- 项目(占总成绩的 30%)
- 发布日期:复活节前后
- 截止日期:学期末
- 考试(占总成绩的 50%)
- 两个小时,闭卷考试
- 内容涉及讲义、研讨会和规定的阅读材料
- 通过标准:考试分数 > 50% ;作业 + 项目 > 50%
1.4 教学人员
- 讲师:Jey Han Lau
- 主管助教:Zenan Zhai
- 助教:
- Aili Shen
- Biaoyan Fang
- Dalin Wang
- Fajri
- Haonan Li
- Jun Wang
- Nitika Mathur
1.5 推荐教材
- 教材:
- JM3: Jurafsky and Martin; Speech and Language Processing, 3rd ed., Prentice Hall. draft
- E18: Eisenstein; Natural Language Processing, Draft 15/10/18
- G15: Goldberg; A Primer on Neural Network Models for Natural Language Processing
- 推荐 Python 学习资料:
- Steven Bird, Ewan Klein and Edward Loper; Natural Language Processing with Python, O’Reilly, 2009
- 阅读材料的链接和课程讲义将发布在 Canvas
1.6 进度安排
| 日期 | 教学周 | 课程 | 名称 | 主题 | 阅读材料 |
|---|---|---|---|---|---|
| 3月2日 | 1 | L01 | 课程概览与介绍 | 介绍 | N/A |
| 3月2日 | 1 | L02 | 文本预处理 | 介绍 | JM3 第 2 章: 正则化 |
| 3月9日 | 2 | L03 | N-gram 语言模型 | 单词 / 文档 | E18 第 6 章 (跳过 6.3 节) |
| 3月9日 | 2 | L04 | 文本分类 | 单词 / 文档 | E18 第 1 & 2 章 |
| 3月16日 | 3 | L05 | 词性标注 | 序列标签 | JM3 第 8 章: 8.1-8.3;8.5.1 节 |
| 3月16日 | 3 | L06 | 序列标注:隐马尔可夫模型 | 序列标签 | JM3 附录 A |
| 3月23日 | 4 | L07 | NLP 深度学习:前馈网络 | 深度学习 | G15 第 4 章 |
| 3月23日 | 4 | L08 | NLP 深度学习:循环网络 | 深度学习 | G15 第 10 章 |
| 3月30日 | 5 | L09 | 词汇语义学 | 语义学 | N/A |
| 3月30日 | 5 | L10 | 分布语义学 | 语义学 | N/A |
| 4月6日 | 6 | L11 | 上下文表示 | 语义学 | N/A |
| 4月6日 | 6 | L12 | 话语 | 语义学 | N/A |
| 复活节假期 | 🏖 | 🏖 | 🏖 | 🏖 | 🏖 |
| 4月20日 | 7 | L13 | 形式语言理论与有限状态自动机 | 句法 | N/A |
| 4月20日 | 7 | L14 | 上下文无关语法 | 句法 | N/A |
| 4月27日 | 8 | L15 | 成分句法分析 | 句法 | N/A |
| 4月27日 | 8 | L16 | 依赖句法分析 | 句法 | N/A |
| 5月4日 | 9 | L17 | 机器翻译 | 应用 | N/A |
| 5月4日 | 9 | L18 | 信息提取 | 应用 | N/A |
| 5月11日 | 10 | L19 | 问答系统 | 应用 | N/A |
| 5月11日 | 10 | L20 | 主题模型 | 应用 | N/A |
| 5月18日 | 11 | L21 | 概括 | 应用 | N/A |
| 5月18日 | 11 | L22 | 生成 | 应用 | N/A |
| 5月25日 | 12 | L23 | 客座演讲 | 杂项 | N/A |
| 5月25日 | 12 | L24 | 课程回顾 | 杂项 | N/A |
1.7 时间安排
- 课程
- 周一 09:00-10:00 $\quad$ Glyn Davis (B117)
- 周一 16:15-17:15 $\quad$ Law GM15 (David P. Durham)
- 研讨会:每周几次
- 可以向助教提出任何问题
- 如果需求人数很多,可能考虑安排办公室答疑时间
- 推荐
- 通过 Canvas 上的讨论板块提问
1.8 关于 Python
- 本课程中将会涉及大量使用 Python
- 研讨会中会涉及大量编程
- 形式为交互式 Jupyter Notebook
- 用 Python 完成作业和项目
- 推荐的 Python 库
- NLTK(文本处理)
- Numpy, Scipy, Matplotlib(数学、绘图)
- Scikit-Learn(机器学习工具)
- Python 新手?
- 请在课程学习中自行安排时间学习 推荐的资源
2. 背景介绍
2.1 自然语言处理
- 涉及语言学、计算机科学和人工智能的跨学科研究。
- 该研究的目的是了解如何设计算法来处理和分析人类语言数据。
- 与 计算语言学 密切相关,但是计算语言学的目标是从计算角度研究语言,以验证语言学假设。
2.2 为什么要进行文本处理?
- 大量的信息都 “陷入” 在非结构化文本中
- 我们如何找到这些信息?
- 如何让计算机自动在这些数据上进行推理?
- 首先需要了解这些结构,找到重要的元素和关系等等……
- 现存的人类语言超过 1000 种
- 挑战
- 搜索、显示结果
- 信息提取
- 翻译
- 问答
- ……
2.3 激动人心的应用
- 智能对话代理,例如 《星际穿越》中的TARS(2014)
- https://www.youtube.com/watch?v=wVEfFHzUby0
- 语音识别
- 自然语言理解
- 语音合成
- IBM 的 “沃森” 问答系统
- 基于大型文本集的问答系统 —— 整合了信息提取和其他功能
- https://www.youtube.com/watch?v=FC3IryWr4c8
- https://www.youtube.com/watch?v=lI-M7O_bRNg (从 3:30 到 4:30)
- 沃森背后的研究并非革命性的
- 但这是 AI 历史上的一个变革性的成果
- 将先进的文本处理组件与大型文本集合和高性能计算相结合
- 还有很多其他方面的应用:机器翻译、搜索引擎、智能家居等等
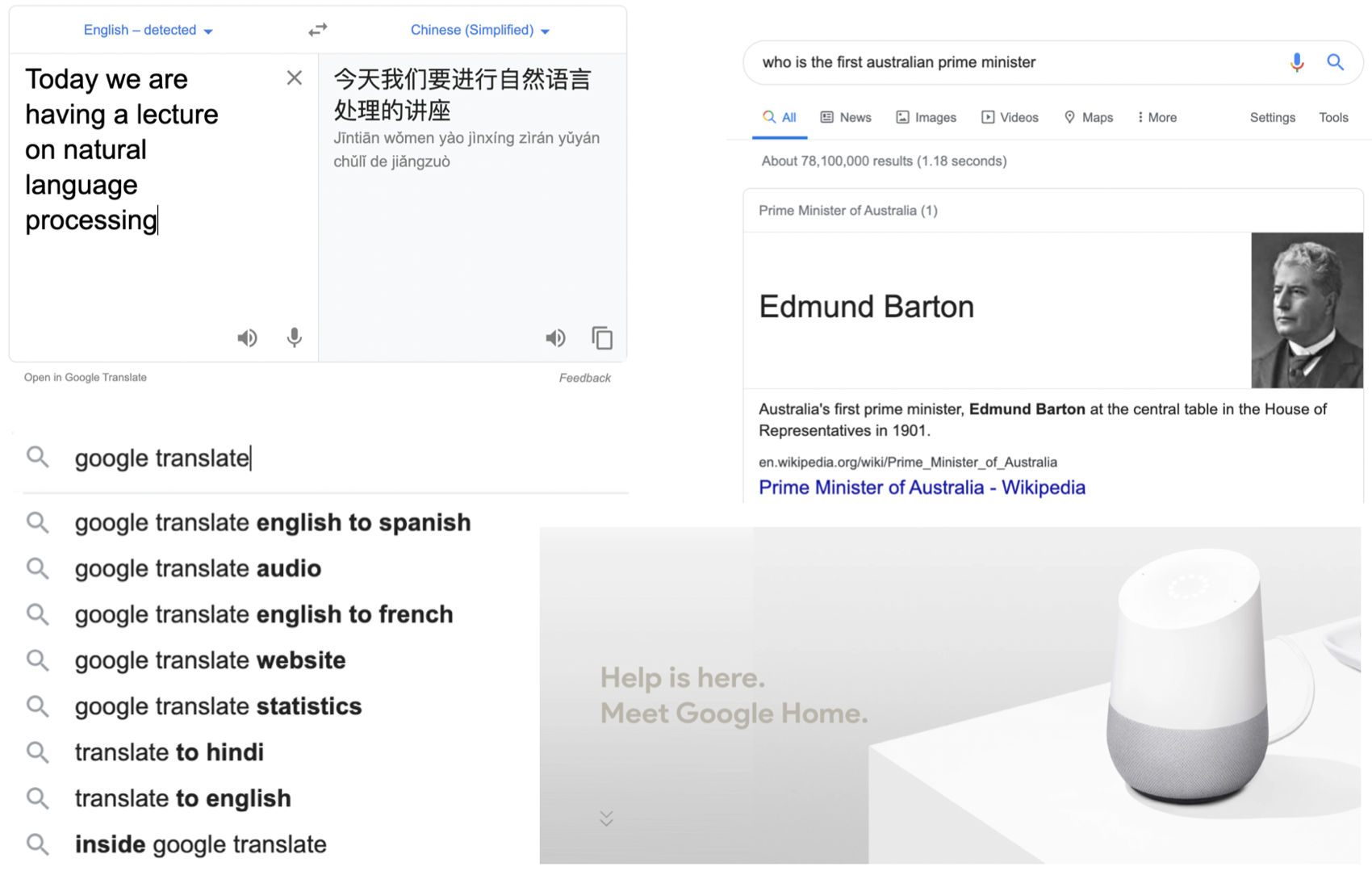
3. 主题概览
- 单词、序列和文档
- 文本预处理
- 语言模型
- 文本分类
- 结构学习
- 序列标注(例如:词性标注)
- NLP 深度学习
- 前馈和循环模型
- 语义学
- 单词如何形成含义
- 句法
- 单词排列方式
- 应用
- 机器翻译
- 信息提取
- 问答系统
4. 模型与算法
- 状态机
- 由状态、状态之间的转换和输入组成的形式模型。
例如:有限状态自动机
- 由状态、状态之间的转换和输入组成的形式模型。
- 形式规则系统
- 正则语法、上下文无关语法来解释句法
- 机器学习
- 理解序列:隐马尔可夫模型
- 文本分类:Logistic 回归、SVM
- 神经网络(深度学习)
5. 语言中的歧义
- $\textit{I made her duck.}$ 这句话存在以下几种可能的含义:
- $\textit{I cooked 🦆 for her.}$
我为她煮了鸭子。 - $\textit{I cooked 🦆 belonging to her.}$
我把她的鸭子给煮了。 - $\textit{I caused her to quickly lower her head or body.}$
我使得她迅速把头低下了或弯下了腰。 - $\textit{I waved my magic wand and turned her into a 🦆.}$
我挥舞我的魔杖,然后将她变成了一只鸭子。
- $\textit{I cooked 🦆 for her.}$
-
为什么存在如此多可能的解释?因为语言是很复杂的。
- $Duck$ 这个词可能存在如下含义:
- 名词:鸭子 🦆
- 动词:快速低下头或弯下身体(例如:为了避开某物)
- $Her$ 这个词可以是一个:
- 宾语代词(即动词的间接宾语)
- 或者,所有格代词
- $Make$ 这个词在句法上也是模棱两可的:
- 及物动词(带一个宾语:$duck$)
- 双宾动词(第一个宾语:$her$;第二个宾语:$duck$)
- 可以带一个直接宾语和动词:宾语($her$)被执行了言语动作($duck$)
思考: 这里之所以存在歧义是因为在这句话之前,我们没有足够的上下文。所以,只要有了足够的上下文信息,机器就可以分辨这种歧义吗?
显然,上下文信息总是越多越好的。但对于消除歧义来说,不仅仅是上下文的问题。因为即便可以得到所想要的全部上下文,对于机器来说可能还是无法轻易作出解释:这对人类来说很简单,但是对于机器来说很难。而且某些时候,上下文甚至不是文本类型的,它可以是非语言的,你可能没有接触过它,或者,有些时候这种上下文涉及的是一种文化层面的差异。所以,有时即便有了上下文,机器可能也无法真正去有效利用它。但通常来说,拥有更多的上下文信息总是更好的。
6. 语言与思想
- 处理语言的能力可以视为真正的智能机器的一块试金石。
- 因为有效地使用语言与我们的一般认知能力息息相关。
- 艾伦·图灵(Alan Turing)提出了著名的 图灵测试(Turing test),以评估一台机器是否具有智能。
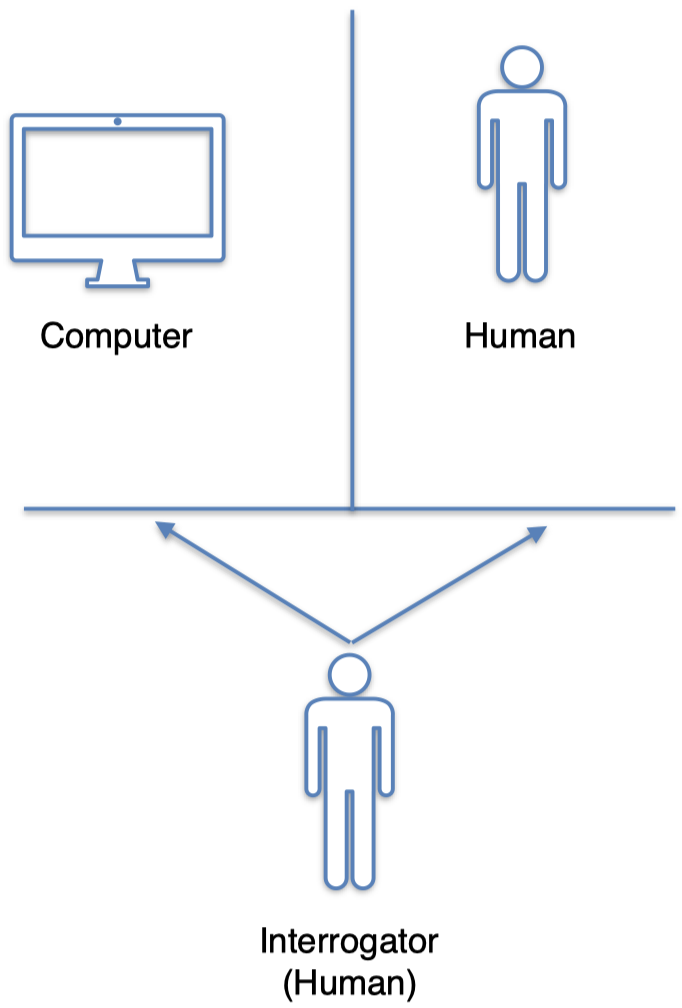
6.1 图灵测试
- 3 个参与者:2 个人类和 1 台计算机
- 其中一个人作为询问者
- 测试涉及两方之间的对话
- 询问者的作用是通过询问一系列问题来确定哪一方的参与者是机器
- 如果这台机器可以骗过询问者,让其误以为 他/她 在和一个人类进行对话,那么我们可以认为这台机器具有智能
6.2 机器具有智能了吗?
- 艾伦·图灵(Alan Turing)预测,到 20 世纪末,具有 10 GB 内存的机器将有 30% 概率成功欺骗人类询问者。
- 我们今天拥有的最聪明的对话代理离真正的智能还很遥远。
- 无论如何,你还是可以构建一些程序 骗过 这个测试。ELIZA 程序就是一个这样的例子。
6.3 ELIZA
- 用户: You are like my father in some ways(你在某些方面像我父亲)
- ELIZA: What resemblance do you see(你看到了什么相似之处)
- 用户: You are not very aggressive but I think you don’t want me to notice that(你有点不思进取,但我想你并不希望我注意到这一点)
- ELIZA: What makes you think I am not aggressive(是什么让你认为我没有进取心)
- 用户: You don’t argue with me(你不跟我争论)
- ELIZA: Why do you think I don’t argue with you(你为什么认为我不跟你争论)
- 用户: You are afraid of me(你害怕我)
- ELIZA: Does it please you to believe I am afraid of you(拜托,你相信我会怕你吗)
7. 自然语言处理简史
1950 年代
- Computing Machinery and Intelligence(计算机器与智能), Alan Turing
- Turing test(图灵测试):通过一个对话测试来测量机器智能
- Syntactic Structures(句法结构), Noam Chomsky
- Formal language theory(形式语言理论):使用代数和集合论将形式语言定义为符号序列
- 例如:$\textit{Colourless green ideas sleep furiously.}$(无色的绿色思想激烈地沉睡。)
- 该句子从意义上讲不通
- 但它的语法似乎还不错
- 强调了语义(含义)和句法(句子结构)二者的区别
1960-1970 年代
- Symbolic paradigm(符号范式)
- Generative grammar(生成式语法):发现生成语法句子的规则系统
- Parsing algorithms(解析算法)
- Stochastic paradigm(随机范式)
- 贝叶斯方法用于光学字符识别(optical character recognition, OCR)和作者身份署名(authorship attribution)
- 第一个在线语料库:Brown corpus of American English(美式英语布朗语料库)
- 100 万个单词,覆盖 500 种不同类型的文档(新闻、小说等等)
1970-1980 年代
- Stochastic paradigm(随机范式)
- Hidden Markov models(隐马尔可夫模型)、noisy channel decoding(噪声信道解码)
- Speech recognition and synthesis(语音识别与合成)
- Logic-based paradigm(基于逻辑的范式)
- 更多的语法系统:例如,Lexical functional Grammar(词汇功能语法)
- Natural language understanding(自然语言理解)
- Terry Winograd 教授 在 MIT 人工智能实验室创建的 SHRDLU(积木世界)系统
- 嵌入玩具积木世界的机器人
- 程序采用自然语言命令,例如:
move the red block to the left of the blue block(将红色块移动到蓝色块的左侧) - 激发了对 semantics(语义)和 discourse(话语)领域的研究
1980-1990 年代
- Finite-state machines(有限状态机)
- Phonology(语音学)、morphology(词法)和 syntax(句法)
- Return of empiricism(经验主义的回归)
- IBM 为语音识别开发的概率模型
- 在 part-of-speech tagging(词性标注)、parsing(解析)和 semantics(语义)方面启发了其他的数据驱动方法
- 基于 held-out data(保留数据)、quantitative metrics(定量指标),以及和最新技术进行比较的经验主义评估
1990-2000 年代:机器学习的崛起
- 更好的计算能力
- 逐渐减少 Chomskyan theories of linguistics(乔姆斯基语言学理论)的主导地位
- 开发了更多的语料库
- Penn Treebank, PropBank, RSTBank 等
- 涵盖各种形式的 syntactic(句法)、semantic(语义)和 discourse annotations(话语注释)的语料库
- 来自机器学习社区的更好的模型:支持向量机、Logistic 回归
2000 年代:深度学习
- 深度神经网络(即具有许多层的网络)的出现
- 从计算机视觉社区开始进行图像分类
- 优势:使用原始数据作为输入(例如仅是文字和文档),而无需开发手动特征工程
- 计算上昂贵:依靠 GPU 在大型模型和训练数据上进行扩展
- 促进了我们现在正在经历的 AI 浪潮
- 家庭助理和聊天机器人
NLP 的未来
- NLP 的问题解决了吗?
- 机器翻译的表现距离完美还很遥远
- NLP 模型仍然无法推理文本
- 不太接近能够通过图灵测试的水平
- Amazon Alexa Prize:https://www.youtube.com/watch?v=WTGuOg7GXYU
下节内容:文本预处理
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。 欢迎转载,并请注明来自:YEY 的博客 同时保持文章内容的完整和以上声明信息!