Lecture 04 文本分类
本节课我们将学习 文本分类(text classification)。
本节课程大纲
- 分类的基本原理
- 文本分类任务
- 分类算法
- 模型评估
1. 分类的基本原理
- 输入
- 一个文档 $d$
- 通常表示为一个特征向量
- 一个固定的类别输出集合 \(C=\{c_1,c_2,\dots,c_k\}\)
- 分类的(Categorical),不是连续的(continuous,例如:regression)或者序数的(ordinal,例如:ranking)
- 一个文档 $d$
- 输出
- 一个预测的类别 $c\in C$
在分类任务中,我们的输入通常是一个文档的集合或者单个的文档,其中包含一些文本数据。另外,我们知道我们的任务所对应的一个封闭集合(closed set),例如对于主题分类任务,我们可能一共有 100 个不同的主题用于分类,这些可能的主题组成了一个封闭的集合,并且该集合里的元素通常是分类标签(categorical labels),而不是用于回归(regression)任务的连续数值或者用于排序的序数型数据(ordinal data)。
而我们希望输出一个关于文档 $d$ 的预测类别 $c$,它应该是来自封闭集合 $C$ 中的一个元素。在一些其他类型的分类任务变体中,我们想要预测的可能不是一个类别,而是多个类别,我们称之为 多标签分类(multi-label classification),但是今天我们不会讨论它。本节课中,我们假设在我们要处理的应用中,正确的标签类别只有一个。
2. 文本分类任务
有很多不同种类的文本分类任务,这节课我们主要通过一些例子介绍以下几种:
-
主题分类(Topic classification)
关于试图理解给定文档的主题是什么,例如:我们可能想知道一篇给定的文章是关于体育的还是国际新闻的。 -
情感分析(Sentiment analysis)
尝试分析作者对于某种产品或者一些其他事情的情感,经常用于评论领域,例如:影评、购物点评、产品测评等。 -
作者身份识别(Authorship attribution)
目标是试图发现某段文本的原作者是谁,例如:司法语言学、抄袭检测等。 -
母语识别(Native-language identification)
类似于作者身份识别,我们也是希望通过一段文本推测出作者相关的一些信息,不同的是,在母语识别中,我们关心的不是作者的确切身份,而是其使用的母语是什么。例如:非英语母语者在进行英文写作时,往往会倾向于采用一种不同于英语母语者的风格,我们可能希望知道其母语是什么。母语识别可以用于教育领域,因为它可以帮助教师发现一些特定学生群体在用非母语写作时可能会犯的一些共同错误。 -
自动事实检测(Automatic fact-checking)
自动事实检测是一个目前需求非常迫切的领域,同时也是一个非常困难的领域。其目的是帮助人们识别社交网络媒体上的一些虚假新闻和信息。
另外,请注意我们的 输入不一定是完整的 “文本”:尽管我们一直说输入是一个文档,但这并不意味着它总是像一篇新闻这种相对比较长的文档,它也可以是像一条推特这种非常短的文本(例如:基于推特的情感极性分析)。当我们谈到 “文档” 或者 “文本” 时,我们并不能假设输入的内容很长,它很有可能只有一句话,甚至可能只是一些 emoji 表情符号。
2.1 主题分类
-
应用场景:图书馆学(library science)和信息检索(information retrieval)
例子:想象你有一个在线图书馆,你试图整理你拥有的这些电子书和数字文档中的知识,如果有一种方法可以帮助你对这些成百上千的文档自动进行分类,那么用户就可以更轻松地在里面浏览和搜索信息。 -
标签类别:不同的主题类别(例如:体育、财经)
例子:媒体出版物中可能会有很多不同的主题分类,像 “工作”、“国际新闻” 等等。具体分类类别取决于你的数据来自的领域。 - 特征:
- 词袋模型(bag of words, BOW)
词袋模型表示是一个很好的选择,通常 unigram 已经足够了。另外,我们可能希望移除一些功能词和停用词,它们并没有包含太多与内容相关的信息。因为在主题分类任务中,我们希望提取到的是一些与内容相关的单词,这些单词可以帮助我们确定文本的主题。 - 更长的 N-grams 模型用于词组(phrases)
另外,对于词组(phrases),我们有时也会使用一些更长的 n-grams 模型(例如:bigrams、trigrams),所以我们也可以有 a bag of bigrams 或者 a bag of trigrams。
- 词袋模型(bag of words, BOW)
- 语料库的例子:
- Reuters news corpus(RCV1,路透社新闻语料库,请参阅 NLTK 示例)
- Pubmed abstracts(一个提供生物医学方面的论文搜索和摘要的数据库)
- Tweets with hashtags(带有话题标签的推文)
2.2 主题分类的例子
请问以下来自路透社新闻语录中的文本的主题是 收购(acquisitions) 还是 收益(earnings)?
LIEBERT CORP APPROVES MERGER
Liebert Corp said its shareholders approved the merger of a wholly-owned subsidiary of Emerson Electric Co. Under the terms of the merger, each Liebert shareholder will receive .3322 shares of Emerson stock for each Liebert share.
这段文本中提到了 “股东(shareholders)”、“合并(merge)”、“子公司(subsidiary)”、“分配股票(share stock)” 这些词,所以我们可以判断这段文本的主题应该是 收购(acquisitions)。
2.3 情感分析
-
应用场景:意见挖掘(opinion mining)、商业分析(business analytics)
例如:你所在的公司最近发布了一个新产品,你希望获得一些用户反馈。如今,社交媒体是一个用来挖掘用户意见的好地方,这些从网络渠道挖掘到的用户反馈将有助于产品的改善。 -
标签类别:正面(Positive)/ 负面(Negative)/ 中性(Neutral)
通常,情感分析的结果可以分为正面和负面两种情况,但是有时我们也会考虑中性的情况。 - 特征:
-
N-grams
这里我们不用词袋模型,而是采用 n-grams 特征。原因是在之前的主题分类任务中,我们并不关心单词之间的顺序;但是在情感分析任务中,单词之间的顺序非常重要。例如:我们的句子中有一个非常正面的词 “$\textit{happy}$”,假如我们像之前词袋模型中一样丢弃单词之间的顺序信息,那么预测的效果将不会太好。 -
极性词典(Polarity lexicons)
极限词典本质上是一个包含了一堆正面极性和负面极性的单词的字典。通常是由人们手工创建的,它的精度很高,但是覆盖范围很小,很适用于通过 bootstrap 的方式来提升我们算法的表现。
-
- 语料库的例子:
- Polarity movie review dataset (NLTK 中的极性影评数据集)
- SEMEVAL Twitter polarity datasets(基于推特的情感极性分析数据集)
2.4 情感分析的例子
请问以下来自 SEMEVAL Twitter polarity datasets 中的推文的 极性(+/-) 是什么?
anyone having problems with Windows 10? may be coincidental but since i downloaded, my WiFi keeps dropping out. Itunes had a malfunction
可以看到,该用户表示自己的 Windows 10 总是出现 WiFi 掉线的问题。显然,对于 Windows 10 来说,这不是什么积极的评价。所以我们可以判断这段文本的情感极性应该是 负面的(Negative)。
2.5 作者身份识别
-
应用场景:司法语言学(forensic linguistics)、抄袭检测(plagiarism detection)
目标是试图发现某段文本的原作者是谁。例如:司法语言学中的收集网络犯罪证据;或者学术论文中的抄袭检测。 -
标签类别:作者(例如:莎士比亚)
任务标签可以是一些著名的作者,例如莎士比亚。也可以是诸如推特用户 ID 等类似信息。 - 特征:
- 功能词(function words)的使用频率
关于特征选择,作者身份识别任务和其他任务有些区别:内容相关的单词在这里并没有那么重要,它们传达给我们的更多是关于主题的信息,但是当我们的目标是找出某段文本的作者时,我们实际上想要捕捉的是关于该作者写作风格的信息,所以句子中的功能词在这里更加重要一些。 - 字符级别的 n-grams(Character n-grams)
相比那些和内容相关的单词,我们希望给句子中的功能词以更高的权重,尤其是这些功能词在句子中的使用方式,所以像关于功能词在字符级别的 n-grams 在这里会非常有用 。 - 话语结构(Discourse structure)
让我们脱离单词层面来看这个任务,话语结构可能会很有用。不同的作者可能会采用不同的叙述方式:有些作者的叙述方式可能很有逻辑性,而有些可能比较跳跃。所以这种更高层次的话语结构对于识别作者身份是非常有帮助的。
- 功能词(function words)的使用频率
- 语料库的例子:
- Project Gutenberg corpus(古腾堡语料库,请参阅 NLTK 示例)
2.6 作者身份识别的例子
请问以下这段来自 Project Gutenberg 的文本是由哪位著名的 小说家 写的?
Mr. Dashwood’s disappointment was, at first, severe; but his temper was cheerful and sanguine; and he might reasonably hope to live many years, and by living economically, lay by a considerable sum from the produce of an estate already large, and capable of almost immediate improvement. But the fortune, which had been so tardy in coming, was his only one twelvemonth. He survived his uncle no longer; and ten thousand pounds, including the late legacies, was all that remained for his widow and daughters.
如果你阅读过很多小说,相信你应该能够很快给出答案:Jane Austen(简$\cdot$奥斯汀)
2.7 母语识别
-
应用场景:司法语言学(forensic linguistics)、教育应用(educational applications)
正如之前提到的,和作者身份识别类似,只不过这里我们关心的不是作者的身份,而是其母语。母语识别也可以用于司法语言学,但更常见的应用是教育方面,它可以帮助缩小来自不同文化背景的教师和学生之间的隔阂。 -
标签类别:作者的母语(例如:中文)
- 特征:
- 单词级别的 n-grams(Word n-grams)
单词级别的 n-grams 在这里很有用,它们可以在一定程度上捕捉到关于句法的信息,所以了解作者在句子中是如何组织这些单词的可以帮助我们识别作者的母语。 - 句法模式(Syntactic patterns)
如果再深挖一下,我们可能会关注到句法模式,例如:词性(part of speech,POS)和解析树(parse trees)。 - 语音特征(Phonological features)
如果我们还有作者的声音信息,那么语音特征会非常有用。例如:通过口音(accent)我们可以判断某人使用的母语是什么。
- 单词级别的 n-grams(Word n-grams)
- 语料库的例子:
- TOEFL/IELTS essay corpora(托福 / 雅思作文语料库)
2.8 母语识别的例子
请问下面这段文本的作者的 母语 是什么?
Now a festival of my university is being held, and my club is joining it by offering a target practice game using bows and arrows of archery. I’m a manager of the attraction, so I have worked to make it succeed. I found it puzzled to manage a event or a program efficiently without generating a free rider. The event is not free, so we earn a lot of money.
识别出作者的母语是一个很困难的问题,但是如果我们对于这种母语有一些了解的话,我们会知道它来自一种亚洲语言:日语。为什么是日语呢?我们知道,英语是一种 “vo” 语言,动词(verb)通常在宾语(object)前面;而日语是一种 “ov” 语言,动词通常放在句子结尾。可以看到,在这段文字中,作者会试图将动词放在句末,所以这给了我们一些提示:这段文字可能出自一位母语为日语的作者。这里,我们通过观察作者在句子中如何组织单词,从而发现了一些有关作者母语的信息。
2.9 自动事实检测
-
应用场景:社交媒体、新闻业(虚假新闻)
由于分布在社交媒体上的虚假新闻和信息日益增多,自动事实检测正在受到越来越多的关注。 -
标签类别:真实(True)/ 虚假(False)/ 不确定(Can’t be sure)
通常这是一个二分类的任务,例如一段文本中包含的是真实信息还是虚假信息。但有时也存在第三种标签:无法确定。 - 特征:
- N-grams
- 非文本的元数据(Non-text metadata)
虽然文本的 n-grams 特征可能会有一些帮助,但是想要真正自动实现这种事实检测,我们通常需要依赖一些文本信息之外的特征,即非文本的元数据,例如:出版商、作者、完成时间等等。这些信息在事实检测任务中有时可能比文本本身的信息更有用,所以我们需要将文本信息和非文本的元数据信息结合起来作为特征。
- 语料库的例子:
- Emergent, LIAR: political statements(一个关于政治言论的语料库)
- FEVER(由亚马逊和谢菲尔德大学的研究人员共同编写的一个开源语料库,旨在促进事实验证系统的发展)
2.10 自动事实检测的例子
请问以下陈述是 真实的 还是 虚假的?
Austin is burdened by the fastest-growing tax increases of any major city in the nation.
这里有一个陈述(statement),有时也被称为声明(claim),我们要做的是判断这个声明的真伪。仅从文本信息来看,我们很难判断这段陈述是真是假,我们需要一些更多的信息。这里答案是 虚假的。如果你对 Austin 这个城市比较了解,你可能会知道答案,但通常情况下这个任务是很困难的,所以我们接下来要做的是去网上寻找一些可以支持或者反对这段声明的证据。
2.11 构建一个文本分类器
构建一个文本分类器通常包含以下步骤:
- 确定感兴趣的任务
- 搜集合适的语料库
- 进行标注
- 特征筛选
- 选择机器学习算法
- 利用保留的开发数据调整超参数
- 根据需要重复先前的步骤
- 训练最终模型
- 在保留的测试数据上评估模型
注意:不要使用测试数据进行模型调整,另外,模型评估只在测试数据上进行。因为,如果你利用测试集对模型进行调整,那么在新的测试数据集上往往会产生过拟合现象,这会使得模型表现很差。在本学期后面的项目作业中,我们会有两个排行榜,如果你针对临时的排行榜进行过多优化的话,很有可能会导致在最终排行榜上由于过拟合而表现较差。
3. 分类算法
接下来,我们将讨论在文本分类任务中一些典型的机器学习模型。
3.1 选择一个分类算法
- 偏差(Bias)vs. 方差(Variance)
- 偏差:我们在模型中作出的假设
- 方差:对训练集的敏感度
在讨论具体的机器学习算法之前,我们需要先弄清两个概念:偏差 和 方差。这是两个非常重要的量,无论我们选择什么样的机器学习模型,通常都需要在这两者之间进行权衡,我们称之为 “偏差-方差权衡(Bias-Variance Tradeoff)”。
如果我们的模型中包含很多假设,那么模型会有一个较高的偏差和一个较低的方差。这种情况下,模型对于训练集不再特别敏感,因此,当我们将一个 “高偏差-低方差” 模型应用到一个新的数据集上时,往往表现会非常好,此时模型的鲁棒性很好。线性模型就是一个 “高偏差-低方差” 的典型例子,因为我们假设目标函数是线性的,这是一个很强的假设,它将导致一个比较高的偏差,但同时线性模型具有很强的鲁棒性,通常不会在训练集上发生很严重的过拟合。相反,非线性模型属于典型的 “低偏差-高方差” 模型,我们不会对目标函数作出任何假设,这会使模型具有较高的方差,使得在训练集上倾向于过拟合。
-
基本假设(Underlying assumptions)
我们还希望弄清楚关于特征的基本假设。例如:在朴素贝叶斯模型中,我们假设特征之间互相独立;但是在文本分类问题中,这样的假设是不适用的,这种情况下朴素贝叶斯模型的效果往往不会很好。 -
复杂度
我们的模型包含多少参数对于模型来说是一个很重要的问题。 - 速度
当我们构建一个应用时,速度是一个很重要的指标。我们的模型可能准确率非常高,但是如果求解需要花费大量时间的话,它可能无法用在我们的应用中。
3.2 朴素贝叶斯(Naïve Bayes)
现在,让我们来看一下最简单的机器学习模型之一:朴素贝叶斯。
- 寻找在贝叶斯定理下,具有最高似然的标签类别:
- 即标签类别的概率乘以给定该标签类别时特征的概率
- 贝叶斯定理:\(P(A\mid B)=\dfrac{P(B\mid A)P(A)}{P(B)}\)
-
朴素地假设特征之间相互独立:
\[p(c_n\mid f_1,\dots,f_m)=\prod_{i=1}^{m}p(f_i\mid c_n)p(c_n)\]该模型基于贝叶斯假设,并且计算条件概率:它试图计算在给定一些特征 $f_1,\dots,f_m$ 的情况下,某个特定分类标签 $c_n$ 的条件概率 $p(c_n\mid f_1,\dots,f_m)$。并且我们假设所有特征之间都是互相独立的,这意味着根据链式法则,它们的联合条件概率可以写成各自条件概率 $p(f_i \mid c_n)$ 的连乘,然后我们将其乘以分类标签 $c_n$ 的先验 $p(c_n)$。频率越高的类别标签会给予其更高的权重,因为它们出现更频繁。这从道理上可以说得通,因为对于出现频率越高的分类标签,我们在预测时也倾向于给予其更高的概率。
- 优点:
- 训练和分类的过程都非常快。
- 具有很好的鲁棒性,低方差。
- 数据不足的情况下也可以表现很好。因为在数据不足的时候,我们会希望作出很多假设,这也正是朴素贝叶斯可以很好地工作的原因。
- 如果特征之间独立性假设是正确的,朴素贝叶斯会是最佳分类器之一。
- 实现起来非常简单。
- 缺点:
- 偏差很高,模型假设很多,例如:线性目标函数、特征之间互相独立等等。
- 独立性假设在通常情况很难满足,尤其是对于这种文本分类的问题。
- 大部分情况下,和其他机器学习模型相比,朴素贝叶斯的准确率较低。
- 需要对特征和未知标签类别进行平滑处理,有时需要进行特征组合。所以在使用朴素贝叶斯时,为了提取有效特征,需要较多的手动特征工程。
3.2 Logistic 回归
接下来我们介绍另外一种非常基础的分类模型:logistic 回归。
-
尽管起名 “回归”,实际上它是一个分类模型。
-
Logistic 回归是一个线性模型,但是它通过 softmax 函数将输出 “压缩” 到 $(0,1)$ 区间从而得到一个有效的概率,如下图所示:
\[p(c_n\mid f_1,\dots,f_m)=\dfrac{1}{Z}\exp(\sum_{i=0}^{m}w_if_i)\]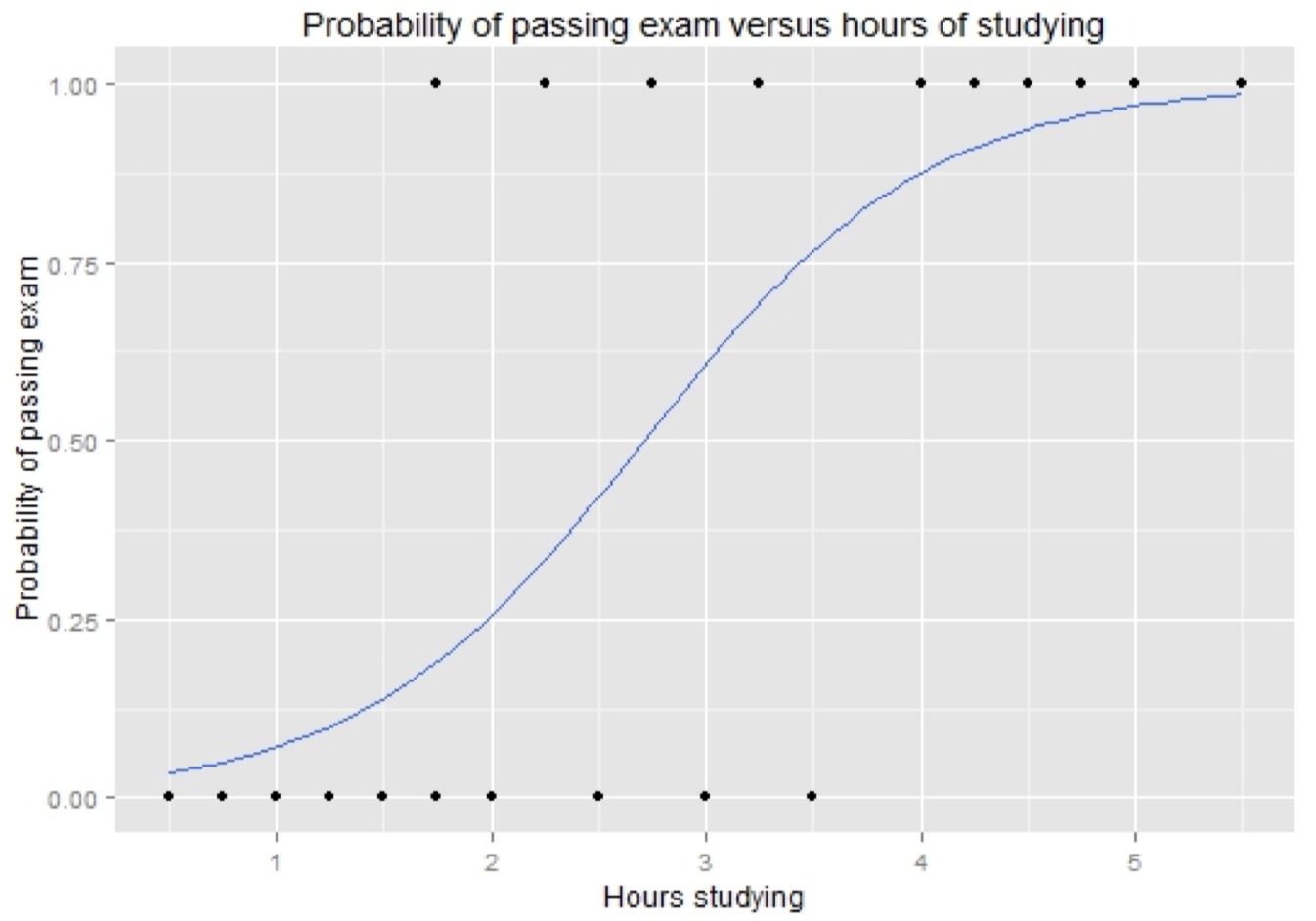
-
Logistic 回归模型在训练过程中会最大化所有训练数据的概率,因此非常适合拟合数据,但是同时存在过拟合的风险。因此,logistic 回归总是会包含一个正则项(或者说 “惩罚项”)使得权重降低或者稀疏。
- 优点:
- 相比朴素贝叶斯,logistic 回归不会假设特征之间的独立性,所以假如我们的数据中有很多互相关联的特征,logistic 回归可以很好地处理它们。
- 缺点:
- 高偏差,因为我们仍然将目标函数假设为线性。 尽管没有朴素贝叶斯那么高的偏差,但总体来说,logistic 回归还是属于偏差较高的模型。
- 训练过程很慢
- 如果不同特征之间的量级差别很大,logistic 回归将无法很好地工作,因此,我们需要进行一些特征缩放。
- 不同于朴素贝叶斯,logistic 回归通常需要大量数据,如果数据不足,其表现将会较差。
- 正如之前提到的,正则化对于 logistic 回归而言非常重要,因为如果缺少正则化项,模型将面临严重的过拟合风险。因此,为了保证鲁棒性,我们需要寻找一个合适的正则化项。
3.3 支持向量机
接下来我们将介绍支持向量机(Support Vector Machines,SVM),它属于一种判别式模型。
-
支持向量机试图将所有的输入特征映射到某个高维空间中,然后寻找一个能够以最大间隔将正负样本分开的超平面。
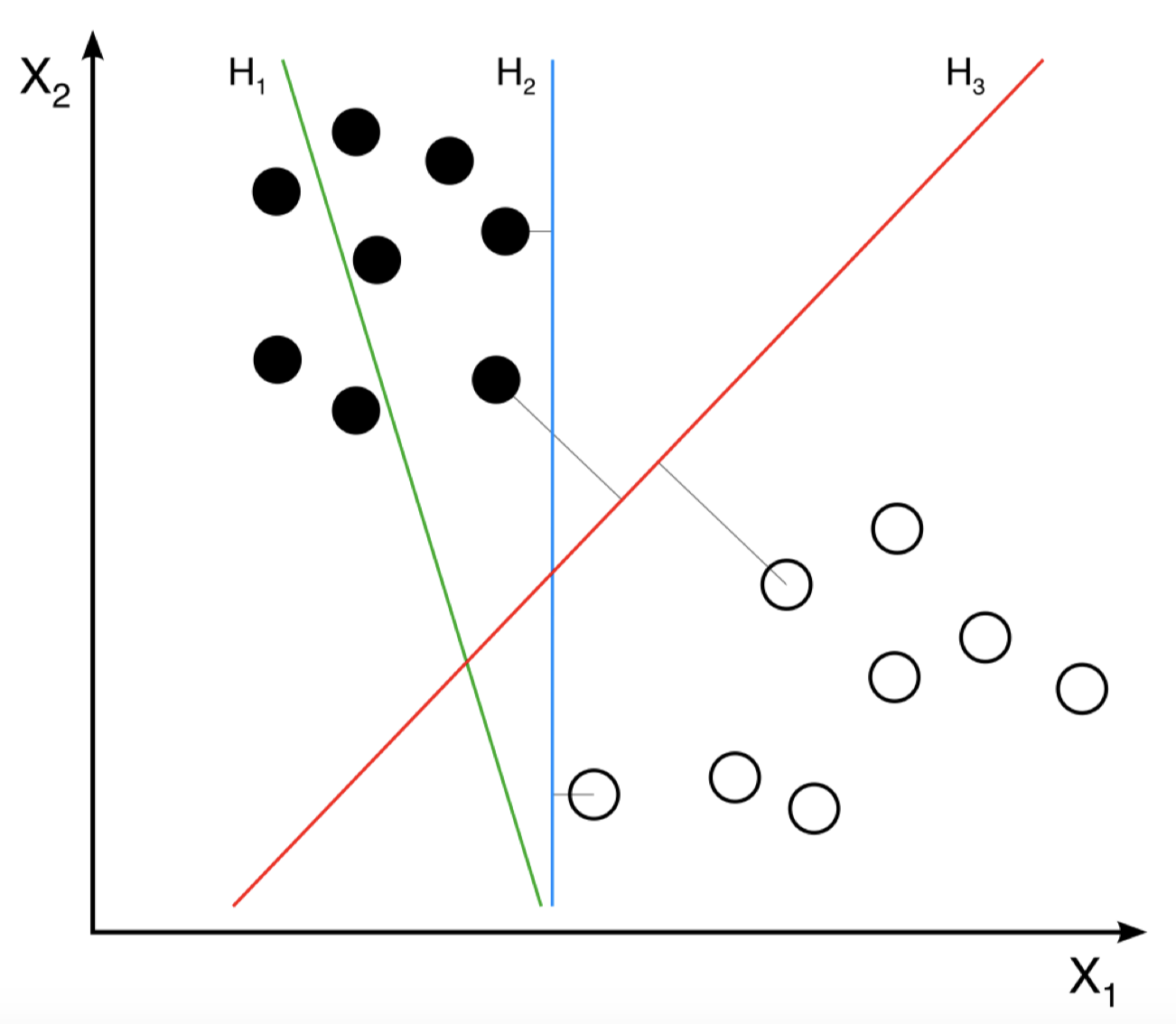
例如:在上图中,我们有绿色、蓝色和红色表示的三个超平面。可以看到,绿色 $H_1$ 超平面并不是一个理想的超平面,因为它没有很好地将黑白两类样本分开;蓝色 $H_2$ 看起来似乎不错,有效地将黑白样本分开了,但是和红色 $H_3$ 相比还是显得不够好,因为它到最近的样本点的距离要比 $H_3$ 到最近样本点的距离小一些,因此,$H3$ 是一个更好的超平面,它给出了一个最大的间隔。
-
当然,在实践中,我们永远不可能找到一个完美将正负样本分开的超平面。所以,我们会采用一种称为 “松弛变量(slack variables)” 的技巧,以允许存在一些分类错误。我们希望找到一个能够将绝大部分样本正确分类的超平面。
- 优点:
- 训练过程很快,准确率很高的线性分类器。
- 没有假设特征之间的独立性。
- 可以通过核技巧(kernel trick)中的非线性核将线性模型转换为非线性模型。
- 对于特征数量很多的数据集,表现非常好。很适用于 NLP 任务,因为特征集合中的特征数量相当于词汇表的大小(例如:我们的词汇表中可能有好几万个唯一单词),因此 SVM 在这种情况下表现会非常好。此外,对于 NLP 问题来说,SVM 在大部分情况下都是最好的机器学习模型之一。
- 缺点:
- SVM 原本是为二分类问题设计的,虽然我们可以通过某种方式将其扩展到多分类问题,例如:训练多个 以 “一对其余” 方式分类的模型,但这种做法会比较麻烦。
- 和 logistic 回归一样,如果不同特征之间的量级差别较大,SVM 将不能很好地工作。因此,SVM 也需要进行特征缩放。不过这通常带一点技巧性,因为进行特征缩放的最佳方式有时取决于具体的任务,所以并没有一种普适的方法。
- 当数据的标签类别存在不平衡问题时(例如:数据集中正例高达 90%,而负例只占 10%),SVM 的表现将非常差。
- 不像朴素贝叶斯可以很容易给出不同特征之间的重要程度,SVM 的可解释性较差。
3.4 K 近邻(KNN)
K 近邻(K-Nearest Neighbour,KNN)是一种非常简单的分类模型,它没有训练过程。
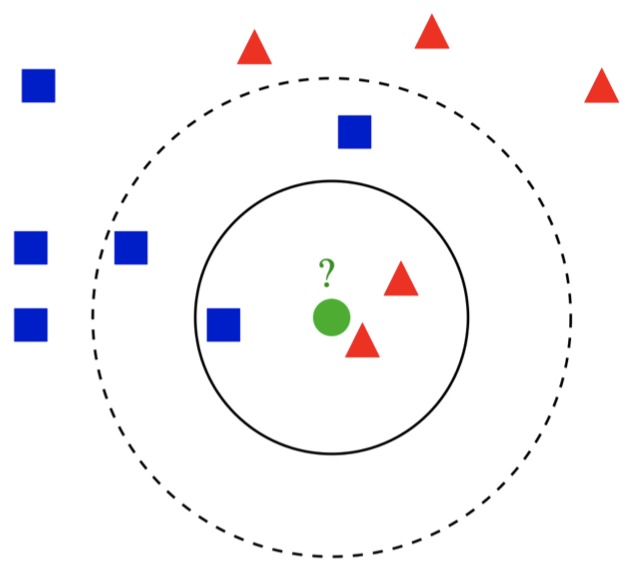
-
分类基于特征空间中离新数据点最近的 $k$ 个训练样本中的多数类别标签。
例如:在上图中,训练数据中的样本点有 $\color{blue}{\blacksquare}$ 和 $\color{red}{\blacktriangle}$ 两类,现在我们想要对某个新的数据点 $\color{#4FAC32}{\Large{\bullet}}$ 进行分类。当 $k=3$ 时,我们考虑距离 $\color{#4FAC32}{\Large{\bullet}}$ 最近的 $3$ 个训练样本(实线圆圈内),可以看到其中有 $2$ 个 $\color{red}{\blacktriangle}$ 和 $1$ 个 $\color{blue}{\blacksquare}$,因此我们将其分类为 $\color{red}{\blacktriangle}$;而当 $k=5$ 时,我们考虑距离 $\color{#4FAC32}{\Large{\bullet}}$ 最近的 $5$ 个训练样本(虚线圆圈内),可以看到其中有 $2$ 个 $\color{red}{\blacktriangle}$ 和 $3$ 个 $\color{blue}{\blacksquare}$,因此我们将其分类为 $\color{blue}{\blacksquare}$。 - 关于最近邻距离的定义可以有多种,选择哪种取决于具体的任务和特征:
- 欧几里得距离(Euclidean distance)
- 余弦距离(Cosine distance)
- 优点:
- 非常简单高效。
- 不需要训练过程(但是仍然需要依赖训练数据)。
- 原生支持多分类问题。
- 对于有限的数据集,总是可以给出正确的类别。理论上,如果有很多数据,KNN 会是一种非常好的方法。
- 缺点:
- 需要选择合适的超参数 $k$,尽管我们可以利用预留的开发数据对其进行调整,但是有时鲁棒性不是很好。
- KNN 同样存在不平衡类的问题。如果训练样本的类别之间严重不平衡,那么 KNN 几乎总是只会将新的数据划分为训练样本中占多数的类别标签。
- 通常很慢。在数据量很大的情况下,KNN 的可扩展性较差,因为在对测试数据进行分类的过程中,为了找到距离最近的 $k$ 个训练样本,我们需要计算测试样本到所有训练样本之间的距离,因此,整个过程会非常缓慢。
- 必须仔细筛选特征。为了能够扩展到很大的训练数据集上,必须保证选择的特征集合比较小以减小计算量,因为数据集越大,计算量也越大,过程会越慢。
3.5 决策树
接下来,我们介绍另外一种常见的分类模型:决策树。
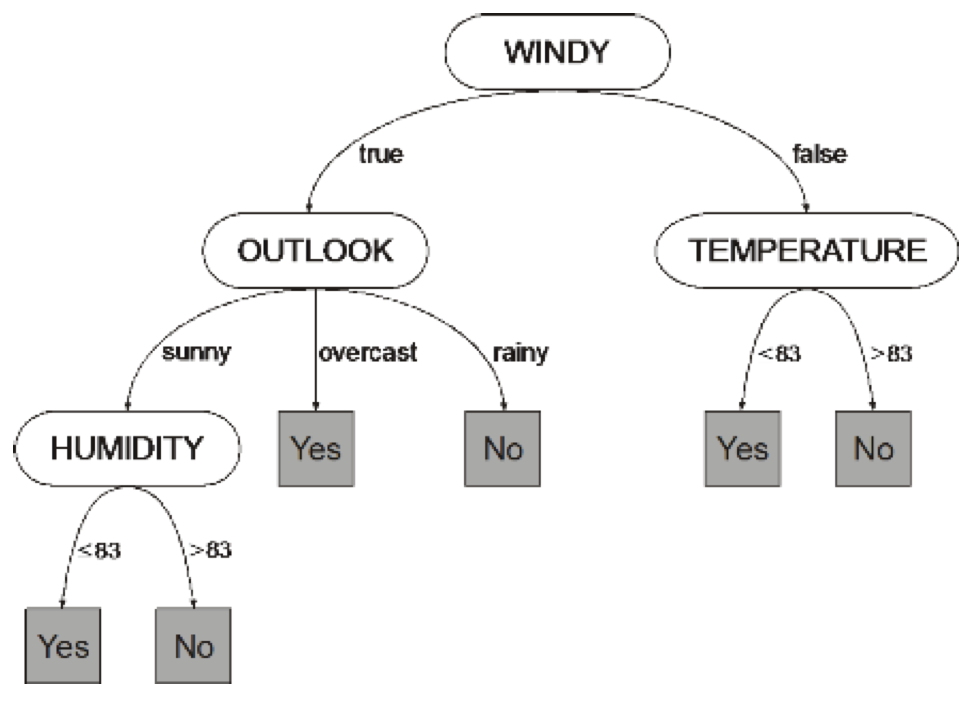
-
构造一颗树,其中每个中间结点代表一个特征,叶子结点代表最终的分类结果。这里,我们对每个中间结点的每一个分支方向进行类似 “是” 或 “否 的二分类测试,叶子结点的值就是 “是” 或 “否”。
-
训练过程基于互信息(mutual information)的贪婪最大化(greedy maximization)。
- 优点:
- 理论上,决策树的可解释性很强。因为我们可以追踪它采用的一系列规则,从路径上发现模型是如何一步步作出分类决策的。
- 模型构建和测试的过程都非常快。
- 不同于前面几种模型,决策树不需要考虑特征表示 / 缩放的问题。
- 适用于小的特征集合。
- 没有假设线性目标函数,可以很好地处理线性不可分问题。
- 缺点:
- 实践中,可解释性不如我们想象的那么好,除非特征数量确实非常少。通常,真实数据会包含大量特征,这会导致整棵树变得非常深,即便我们可以从根结点追踪路径,我们也很难从大量的特征中提取太多有用信息。
- 会产生很多高度冗余的子树,因为特征之间可能存在相互依赖。
- 当特征数量很大时,不建议采用决策树模型。
3.6 随机森林
接下来,我们介绍一种基于决策树的分类算法:随机森林。
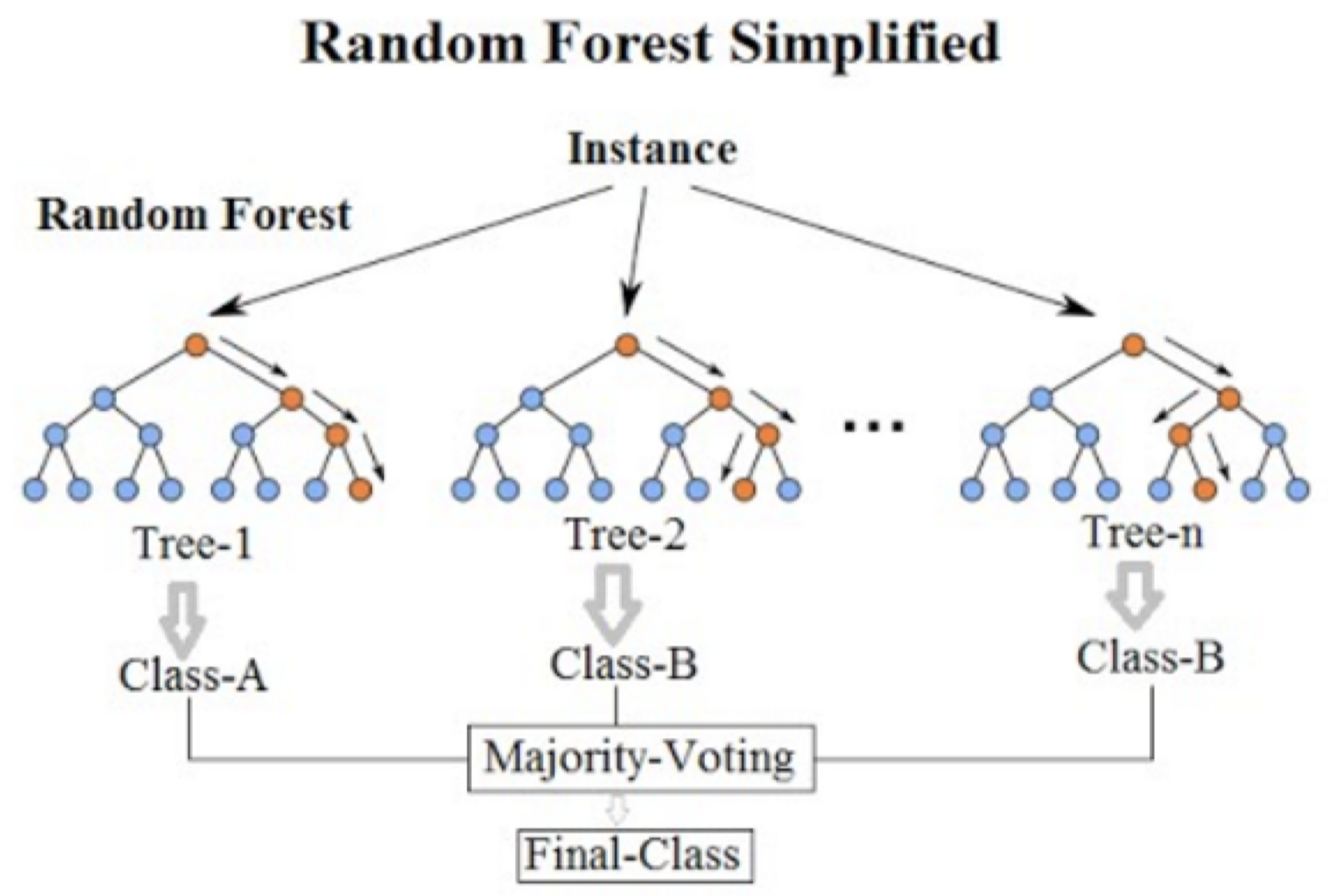
-
随机森林是一种集成分类器,它包含了很多决策树模型。
-
我们对原始训练数据进行划分,同时对于特征空间也进行划分,然后分别在每个划分上训练决策树模型,从而构建很多不同的决策树模型。
-
最终进行分类决策时,由全部子分类器(决策树)进行多数投票给出分类结果。
例如:在上图中我们训练了 3 个决策树子模型,对于一个新的测试数据,树 1 给出的分类结果为类别 A,树 2 和树 3 给出的分类结果为类别 B,所以模型最终分类结果为类别 B。 - 优点:
- 通常比决策树的准确率更高,鲁棒性也更好。
- 对于中小型数据集,效果非常好。
- 训练很容易实现并行化。因为每棵决策树都可以单独进行训练,所以可以 很好地扩展到较大的数据集上,只需要增加决策树的数量即可。
- 缺点:
- 解释性不如决策树那么好,因为这里包含很多决策树。
- 和决策树一样,对于很大的特征集合,训练速度很慢。
3.7 神经网络
最后,我们将介绍神经网络。它很早之前就被提出了,其灵感来自人类大脑的工作机制。

-
通常,神经网络是由一组按层排列、互相连接的节点组成。
例如:上图中,我们有一个由输入层、隐藏层和输出层所组成的 3 层神经网络。 -
神经网络通常包括:输入层(特征)、输出层(类别概率)以及一个或多个隐藏层(输入特征的中间表示)。
-
基本上,每个节点所做的就是对其上一层的输入执行线性加权,再将结果通过激活函数(通常是一个非线性函数)传递给下一层的节点。
- 优点:
- 非常强大,推动了如今深度学习的浪潮。
- 在给定大量数据的情况下,对于大多数的 NLP 和 CV 任务而言,神经网络都可以得到几乎最高的准确率。
- 缺点:
- 不属于现成的分类器,需要自己设计具体架构。
- 和其他传统的机器学习模型相比,神经网络的参数数量要多得多,很难选择出最合适的参数组合。
- 训练过程很慢。
- 神经网络属于 “低偏差-高方差” 模型,容易产生过拟合。因此,我们需要花费很多精力在模型的正则化上。
- 计算成本高,通常依赖于 GPU。
3.8 超参数调整
在前面关于文本分类的步骤中,我们提到了一些关于超参数调整的内容。超参数调整是非常必要的,因为对于任何给定的机器学习模型,我们会有一系列的超参数,例如:SVM 中的松弛变量或者神经网络中的 batch size 等。
- 对于训练集的调整
- 开发集(也称 “验证集”)
- 不属于训练集或者测试集
- k 折交叉验证,适用于训练数据较少的情况
-
特定的分类模型有其特定的超参数,对于不同的模型,我们需要知道其对应的超参数是什么。 例如:决策树模型中树的深度
-
通常,我们需要调整的超参数的数量都比较多,所以我们很难尝试所有的超参数组合,这种情况下,我们可以采用网格搜索的策略寻找近似最优的超参数组合。
- 还有很多超参数与正则化有关(例如,神经网络模型)
- 正则化超参数可以降低模型复杂度
- 用于防止过拟合
4. 模型评估
最后一部分,我们将讨论几种常见的模型评估指标。
4.1 准确率(Accuracy)
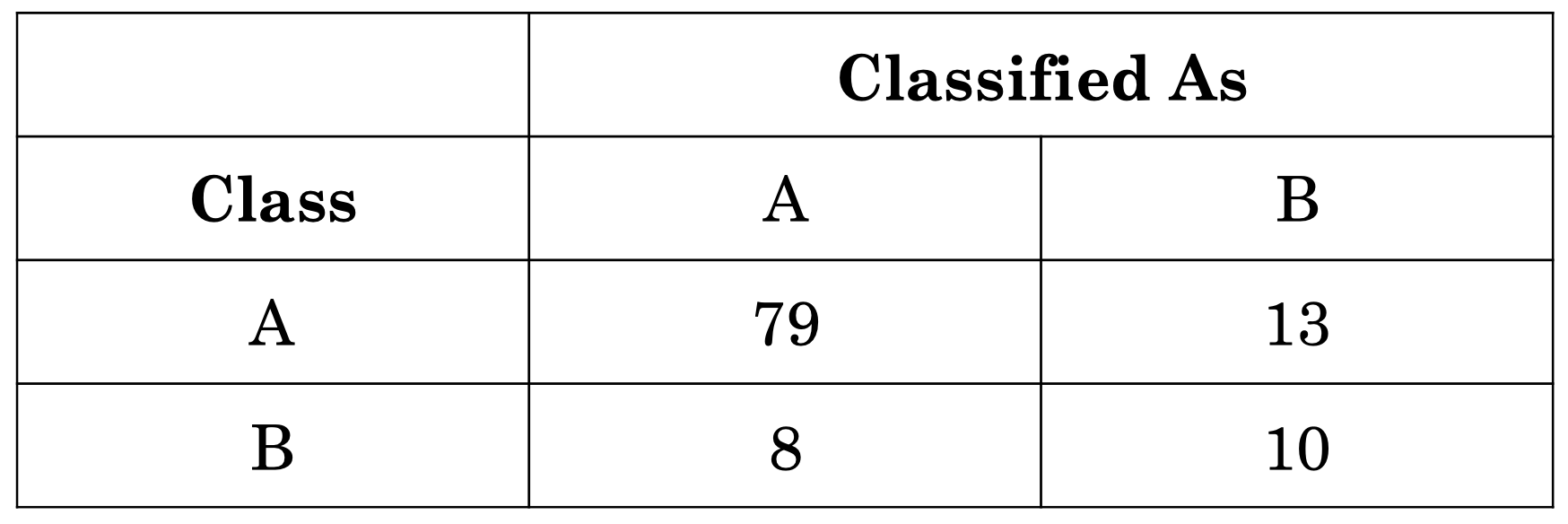
这里,我们有一个表格,左边的列表示数据的真实类别,上面的行表示我们的模型给出的类别。准确率的计算公式为:
\[\text{Accuracy} = \dfrac{\text{correct classifications}}{\text{total classifications}}= \dfrac{79+10}{79 + 13 + 8 + 10}=0.81\]$0.81$ 看起来是一个不错的结果,但是如果仔细观察会发现,最常见类别的 baseline 准确率为:
\[\text{Accuracy}_{\text{most}} = \dfrac{\text{most common class instances}}{\text{total classifications}}= \dfrac{79+13}{79 + 13 + 8 + 10}=0.84\]这意味着,如果我们直接简单地将所有数据都判定为类别 A,我们将得到 $84\%$ 的准确率。所以,当训练集存在类别不平衡问题时,准确率并不是一个很好的评估指标。
4.2 精度(Precision)与召回率(Recall)
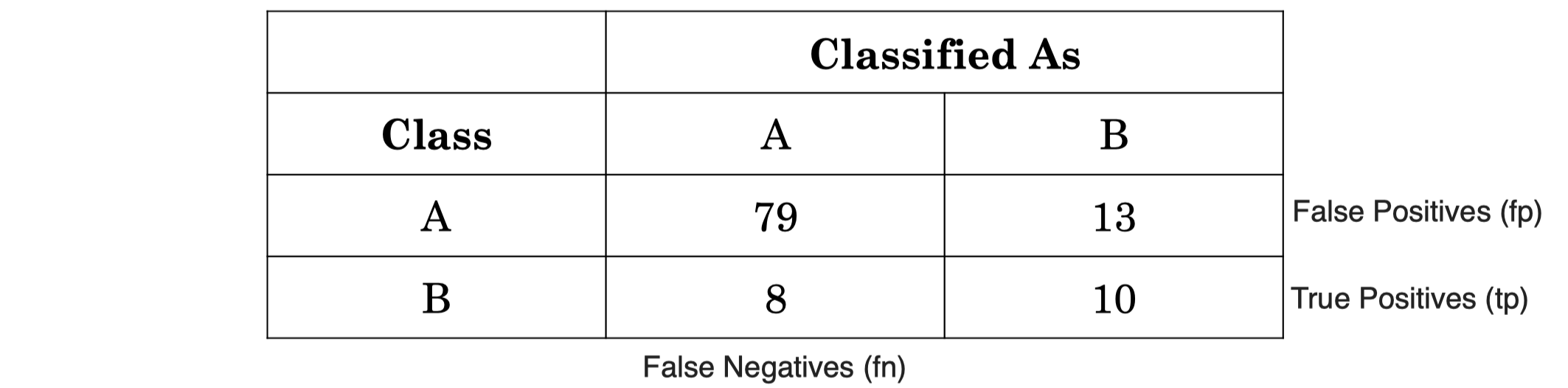
假设现在我们对少数类 B 感兴趣,即将类别 B 作为 “阳性类(positive class)”,其精度和召回率计算公式如下:
\[\text{Precision} = \dfrac{\text{correct classifications of B (tp)}}{\text{total classifications as B (tp + fp)}}= \dfrac{10}{10 + 13}=0.43\\\\\] \[\text{Recall} = \dfrac{\text{correct classifications of B (tp)}}{\text{total instances of B (tp + fn)}}= \dfrac{10}{10 + 13}=0.56\]4.3 F(1)-score
-
精度和召回率的结合:
\[\text{F1}=\dfrac{2\times\text{Precision}\times \text{Recall}}{\text{Precison}+\text{Recall}}\] - 像精度和召回率一样,其定义取决于特定的阳性类别。
- 但可以作为一个通用的的多类别指标。
- 宏观平均(Macroaverage):不同类别之间的平均 F-score
例如,我们可以分别计算类别 A、B 的 F-score,然后取两者的平均值。从本质上看,这里我们认为 A、B 两个类别一样重要。 - 微观平均(Microaverage):利用计数累加和计算 F-score
这里,我们计算的是综合的 F-score,它会根据 A、B 数量的差别产生偏差,当我们认为 A、B 两个类别的重要程度不一样时,我们可以选择这种方法。所以具体采用哪种计算方式取决于我们的任务。
- 宏观平均(Macroaverage):不同类别之间的平均 F-score
5. 总结
-
对于感兴趣的任务,我们有很多算法可以尝试。(请参阅 scikit-learn)
-
但是,如果我们的目标是在新任务上取得良好的结果,那么一个标注好的、数据丰富的数据集和适当的特征通常比使用某种的特定算法更重要。
6. 扩展阅读
- Natural Language Processing, Draft 15/10/18, by Eisenstein
- Chapter 4 (4.1, 4.3-4.4.1)
- Chapter 2 & 3:回顾线性核非线性分类算法
下节内容:词性标注
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。 欢迎转载,并请注明来自:YEY 的博客 同时保持文章内容的完整和以上声明信息!