Lecture 11 上下文表示
这节课我们学习 上下文表示(Contextual Representation),即单词在上下文中的含义。
1. 上下文表示
1.1 词向量/嵌入
在之前的章节中,我们已经学习过 词向量/嵌入(Word Vectors/Embeddings),我们还学习了如何通过基于计数的方法来得到词向量。
- 每个单词 type 都有一个表示。
- Word2Vec
- 无论单词的上下文是什么,我们得到的单词表示都是相同的。
通过这种方式,无论这些单词在句子中是如何被使用的或者出现在句子中的哪个地方,以及它们的相邻单词是什么,模型学习到的每个单词 type 的词向量/嵌入都只有一种表示。我们称之为 上下文无关词向量/嵌入(Contextual Independent Word Vectors/Embeddings)。 - 这种上下文无关词向量没有捕获到 单词的多义性(multiple senses of words)。
例如:对于单词 “$\textit{duck}$”,其既可以表示鸭子这种动物,也可以表示躲避这一动作。而我们之前的词向量没有办法捕获到这两种含义之间的差异,因为对于同一单词我们只有一种向量表示。 - 上下文表示(Contextual representation)$=$ 基于上下文的单词表示
如果一个单词在两个句子中的含义不同,那么我们将得到该单词的两种不同的上下文表示。 - 但是,更重要的是,我们发现预训练的上下文表示在大部分下游任务中的表现都 相当出色。这种基于上下文的单词表示已经在目前的 NLP 系统中充当着基石的角色。
1.2 RNN 语言模型
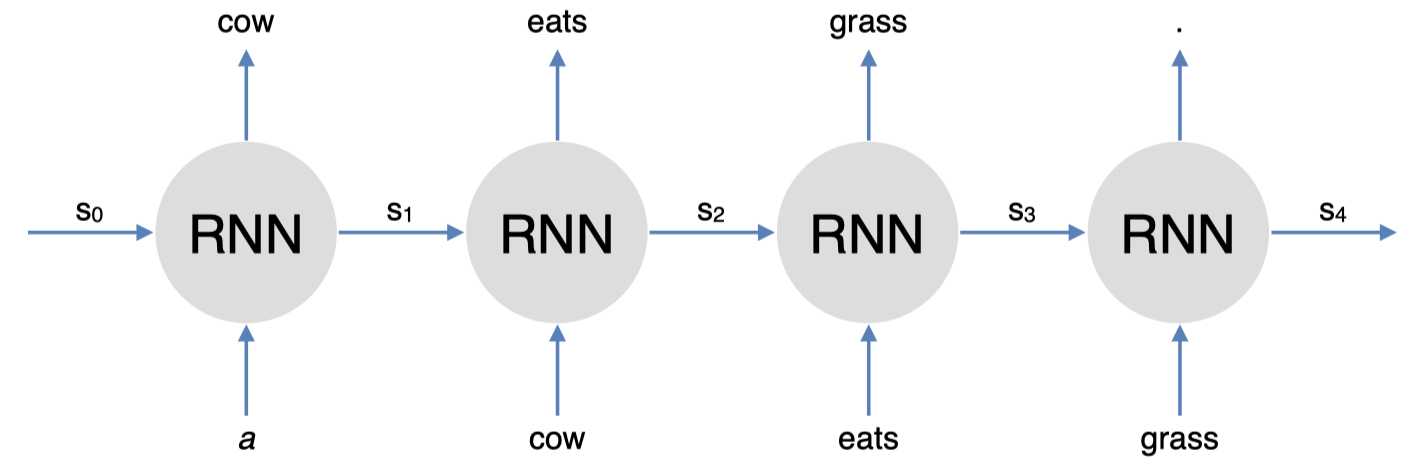
所以,我们应当如何学习到这种上下文表示呢?
这里,我们有一个 RNN 语言模型:“$\textit{a cow eats grass}$”。这里,RNN 模型试图预测下一个单词:给定单词 “$\textit{a}$”,RNN 模型试图预测下一个单词 “$\textit{cow}$”;给定单词 “$\textit{cow}$”,它试图预测下一个单词 “$\textit{eats}$” 等等。
下面是一个简单的 RNN 语言模型:
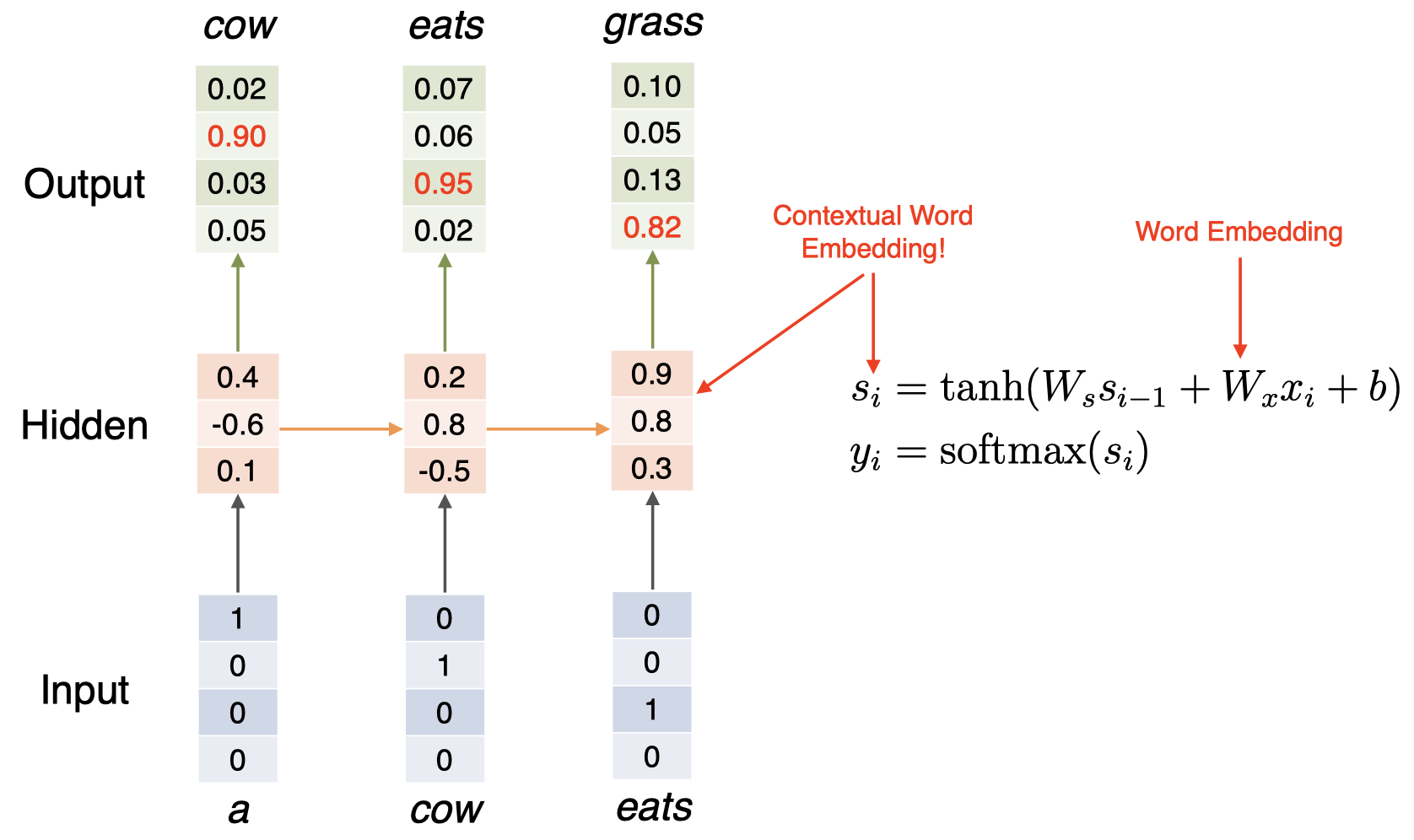
模型一共 3 层:输入层是单词的 one-hot 向量;隐藏层作为中间层;输出层用于预测下一个单词。其中,隐藏层的计算公式如右边所示:其接受前一个时间步(time-step)的隐藏状态 $s_{i-1}$,并结合当前输入 $x_i$,然后加上一个偏置项 $b$,然后输入一个非线性激活函数 $\tanh$,然后我们得到当前时间步的隐藏状态 $s_i$;之后,我们将当前时间步的隐藏状态 $s_i$ 输入到一个 $\mathrm{softmax}$ 函数中,得到词汇表中的所有单词的在当前时间步的概率分布。
我们知道,词嵌入对应上面的矩阵 $W_x$,我们可以将隐藏状态 $s_i$ 从某种程度上解释为当前单词的上下文表示。为什么可以这样解释呢?假设当前输入单词为 “$\textit{eats}$”,我们计算出该单词的隐藏状态,该 隐藏状态不仅捕获了单词 “$\textit{eats}$” 的信息,而且还包括之前见过的历史单词:“$\textit{a}$” 和 “$\textit{cow}$”。所以,我们可以将 RNN 语言模型中的隐藏状态从某种程度上视为一种上下文单词表示。
那么,问题解决了吗?
-
几乎解决了,但是还没有完全解决。因为该 RNN 语言模型得到的单词的上下文表示仅仅捕获了该单词左边的上下文。
例如:对于单词 “$\textit{cow}$”,其隐藏状态仅仅捕获了其前面出现过的单词 “$\textit{a}$” 的信息,而没有捕获到其后面出现的单词 “$\textit{eats}$” 的信息。 -
解决方案:使用 双向 RNN(bidirectional RNN)模型替代。
1.3 双向 RNN
现在,我们来看一下如何利用双向 RNN 模型来捕获当前单词左右两侧的上下文信息,从而得到当前单词的上下文表示。
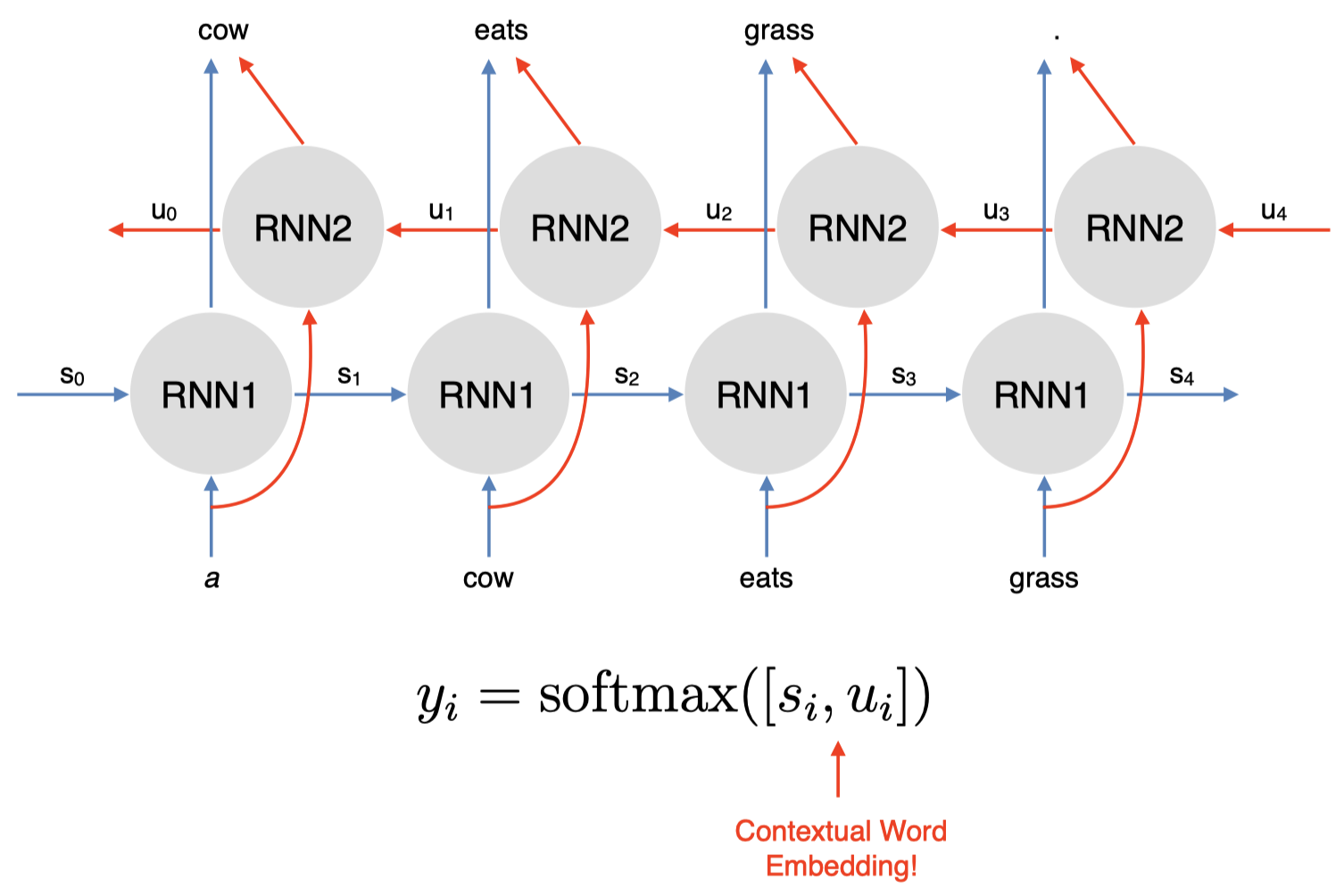
我们有一个简单的 RNN1,和之前一样,我们有句子 “$\textit{a cow eats grass}$”。其中,$s_0, s_1, s_2, s_3$ 表示每个单词 $x_i$ 的前一个时间步的隐藏状态,即 $s_{i-1}$;输出的当前隐藏状态 $s_i$ 捕获了基于之前单词的上下文表示。然后,我们可以简单地添加一个反向 RNN2,从右向左进行,以捕获当前单词右边的上下文单词,同样,我们会得到一个输出的当前隐藏状态 $u_i$。然后,我们可以连接前向和后向两个 RNN 的隐藏状态 $s_i$ 和 $u_i$,从而得到一个同时捕获了当前单词两侧上下文单词信息的词表示。
还是以单词 “$\textit{cow}$” 为例,我们的预测单词为 “$\textit{eats}$”。这里,当前单词 “$\textit{cow}$” 的上下文表示由两部分构成:其中指向预测单词 “$\textit{eats}$” 的蓝色箭头表示隐藏状态 $s_2$ 捕获的左边的上下文单词 “$\textit{a}$” 的信息,而指向预测单词 “$\textit{eats}$” 的红色箭头表示隐藏状态 $u_1$ 捕获的右边的上下文单词 “$\textit{eats}$” 和 “$\textit{grass}$” 的信息。
所以,通过双向 RNN 模型,我们可以得到同时包含当前单词两侧信息的上下文表示,并且,无需另外设计新的模型或者架构。
2. ELMo
双向 RNN 这种思路也启发了 ELMo 模型:它是一种非常流畅自然的单词上下文表示模型,并且在大部分的 NLP 任务中都取得了非常好的效果。
2.1 ELMo:基于语言模型的嵌入
ELMo 表示 基于语言模型的嵌入(Embeddings from Language Models)。
- Peters et al. (2018): https://arxiv.org/abs/1802.05365v2
- ELMo 在一个包含 1B(10 亿)单词的语料库上训练了一个双向多层 LSTM 语言模型。
- 它结合了来自 LSTM 的 多层(multiple layers)的隐藏状态,并用于下游任务中。
- 这是 ELMo 的创新点之一:因为之前关于预训练模型的上下文表示研究只使用了顶层的信息,因此并没有在性能上获得太大提升。而对于 ELMo,假如我们使用了一个 2 层的 LSTM,那么我们将同时使用第一层和第二层的 LSTM 的输出。
- 最重要的是,研究发现,仅仅通过增加一些预训练的上下文词嵌入,就能在大部分的 NLP 任务中取得较大提升。
2.2 ELMo 架构
- LSTM 层数 $= 2$
- LSTM 隐藏层维度 $= 4096$
- 使用 字符级的卷积神经网络(Character CNN)来创建词嵌入。
- 没有未知单词
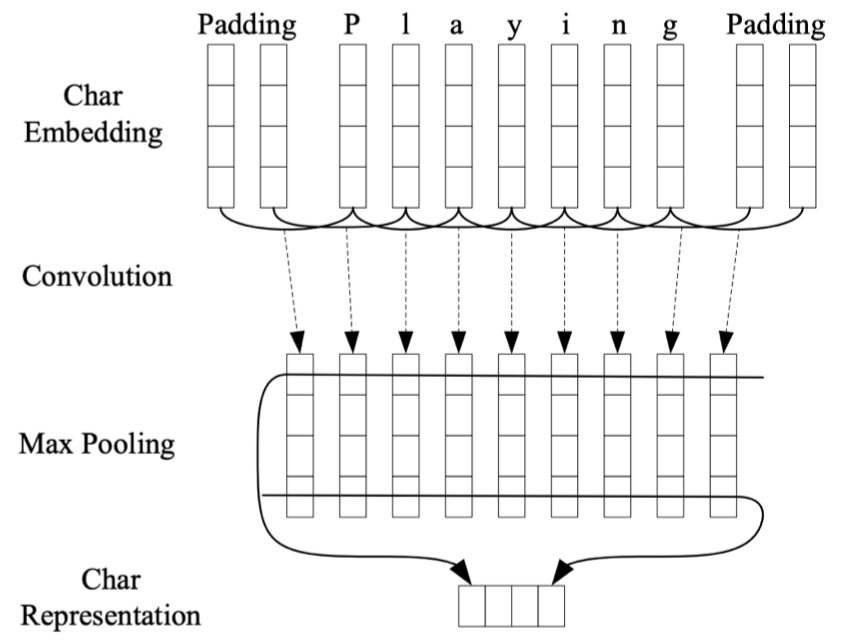
例如:对于单词 “$\textit{Playing}$”,相比直接创建一个该单词的词嵌入,ELMo 选择将其 token 化为一个个英文字母:“$\textit{P}$”、“$\textit{l}$”、“$\textit{a}$”、“$\textit{y}$”、“$\textit{i}$”、“$\textit{n}$”、“$\textit{g}$”。然后我们学习得到单词中每个字母的字符嵌入,并且在其前后添加 paddings 以保证最终得到的单词嵌入的长度一致。然后将其喂给一个带最大池化层的 CNN 模型,来创建一个基于字符嵌入的单词 “$\textit{Playing}$” 的表示。
那么,为什么要这样做呢?因为这样可以基本解决未知单词的问题。例如:假设我们在语料库中没有见过单词 “$\textit{Playing}$”,那么当遇到这个单词时,我们需要另外用一个未知单词嵌入来表示它。而如果我们将其分解为字符嵌入,那么只要我们的语料库中包含了这些字符,我们就不会遇到未知单词的问题。通常,这种方法很简单,因为组成单词的字符通常都是有限的(例如:不考虑大小写的话,英文单词都是由 26 个字母组成)。所以,这是一种可以避免未知单词问题的方法。
2.3 提取上下文表示
当我们在 10 亿单词语料库上对该双向 LSTM 模型进行预训练之后,我们如何提从中提取单词的上下文表示呢?我们又该如何将我们提取到的上下文表示用于下游任务呢?
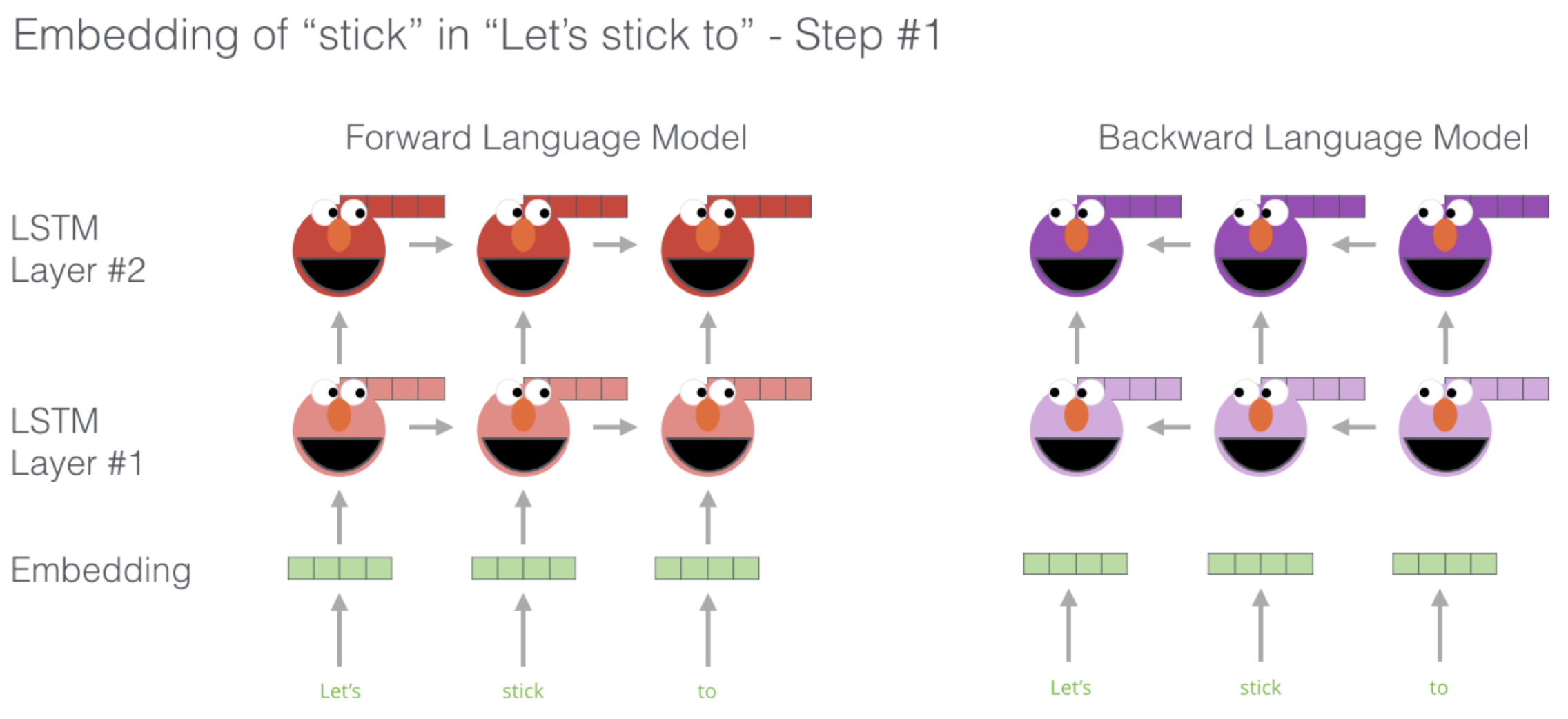
这里,我们有一个已经训练好的 ELMo 模型。然后假设现在我们有一个句子:“$\textit{Let’s stick to}$”,我们希望得到单词 “$\textit{stick}$” 的上下文表示。首先,我们将句子中的单词分别喂给 ELMo 中的前向语言模型和后向语言模型。
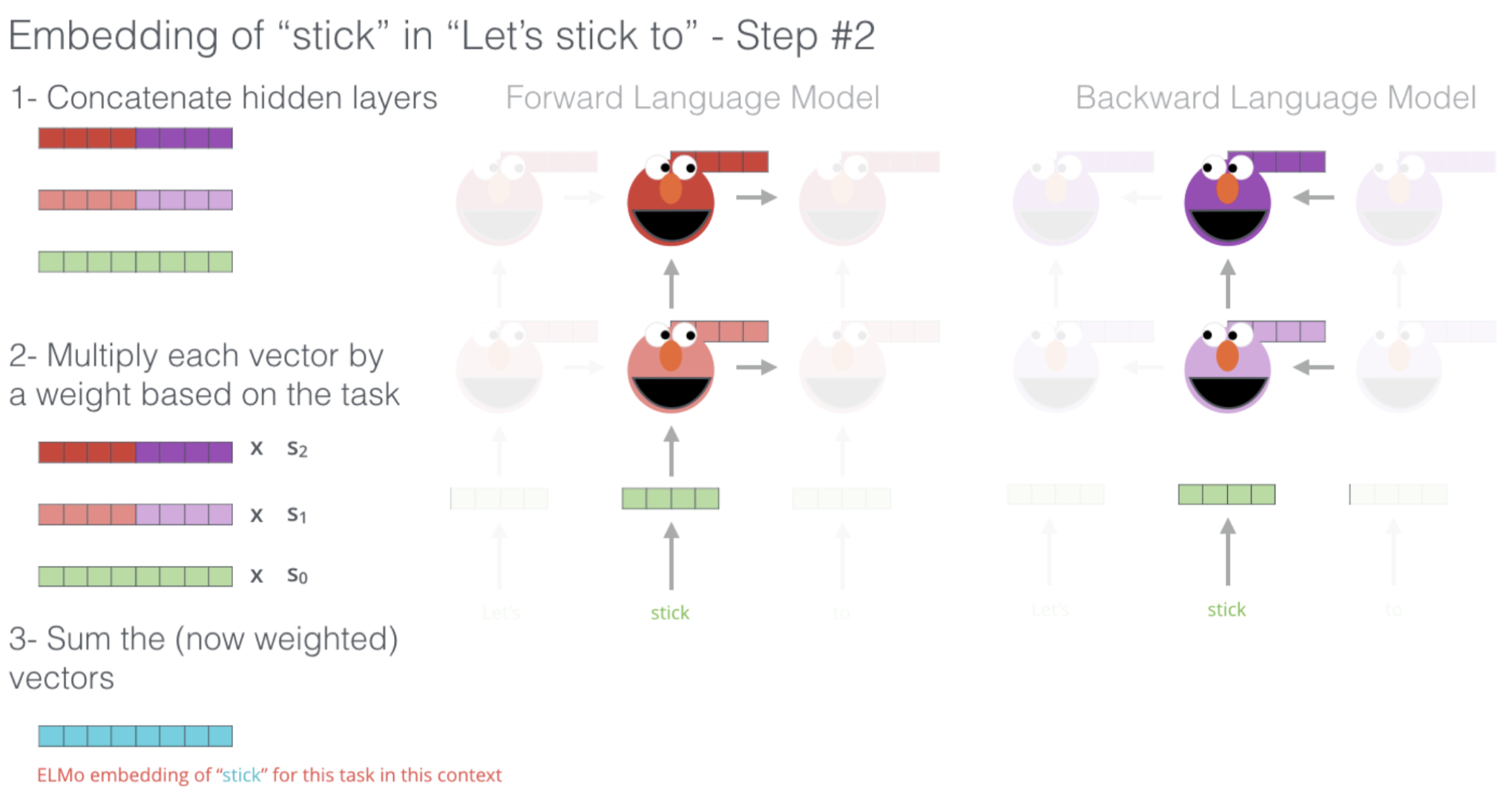
之后,我们观察两个语言模型中的所有 LSTM 层的隐藏状态,并且将两个模型中对应的每一层的隐藏状态以及输出层的词嵌入连接起来。然后,我们对每一层得到的连接向量进行加权求和(这里假设对应层的权重分别为 $s_2, s_1, s_0$,关于权重值的选择我们将在后面进行介绍)。然后我们将得到单词 “$\textit{stick}$” 在这里的上下文 “$\textit{Let’s stick to}$” 中的上下文嵌入表示。
可以看到,整个过程很简单:我们从两个方向的语言模型中提取所有层的隐藏状态,并对其进行连接,然后加权求和即可。
2.4 下游任务:词性标注
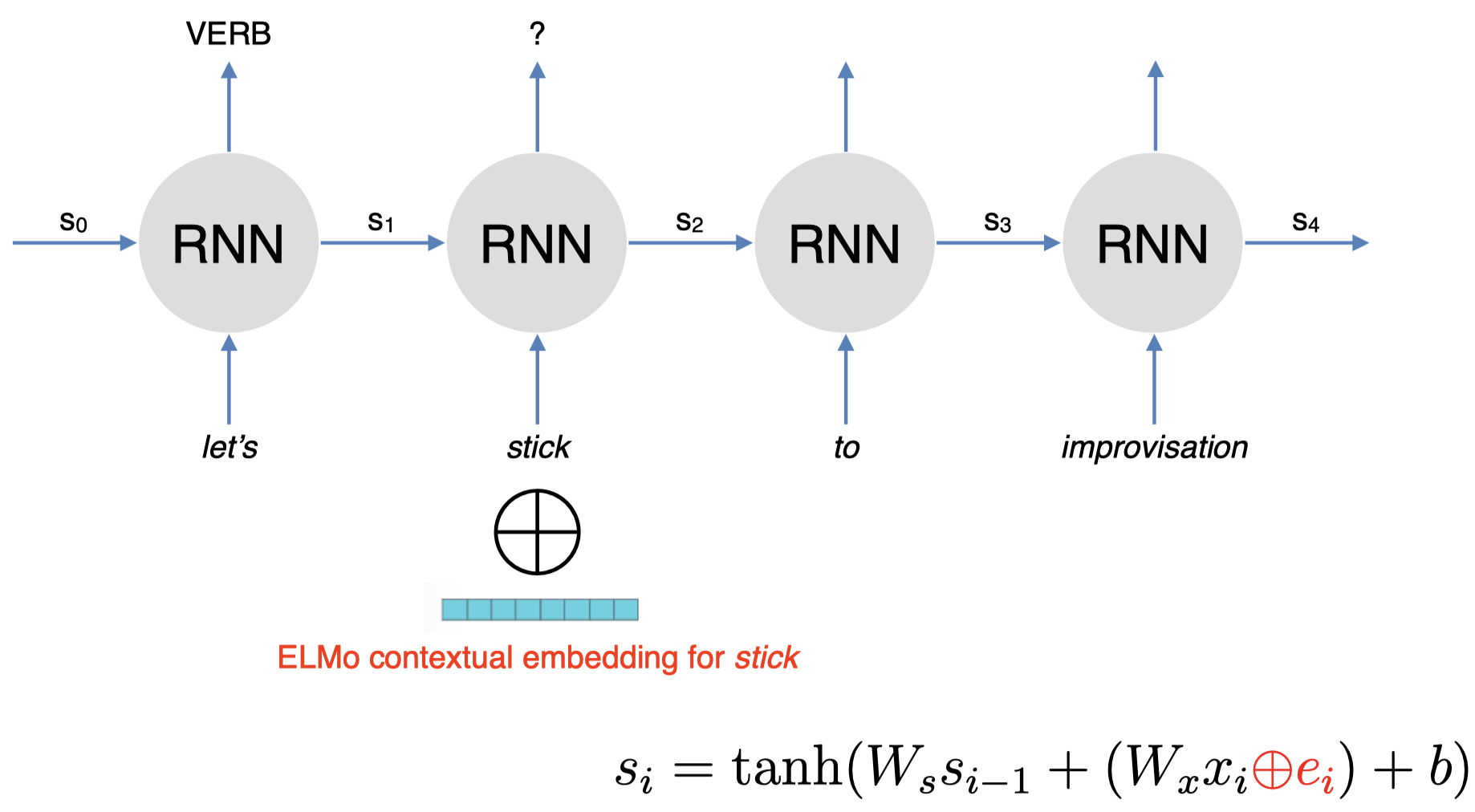
那么,我们如何将得到的上下文表示用于下游任务呢?
这里,我们有一个利用 RNN 进行 词性标注(POS Tagging)的任务:
给定一个句子 “$\textit{let’s stick to improvisation}$”,我们试图对其中的每个单词进行词性标注,例如:单词 “$\textit{let’s}$” 对应的 POS 为 “VERB”,我们希望得到单词 “$\textit{stick}$” 的 POS。
非常简单,我们简单地将基于 ELMo 得到的单词 “$\textit{stick}$” 的上下文表示和其在下游任务中的词嵌入进行连接。例如:这里,我们的下游任务中是一个简单的 RNN 模型,我们只需要在原始的隐藏状态 $s_i$ 的计算公式的基础上:将当前单词的嵌入 $W_x x_i$(其中,$x_i$ 为当前输入单词的 one-hot 向量,$W_x$ 为嵌入矩阵),连接一个基于 ELMo 得到的当前单词的嵌入 $e_i$ 即可。然后我们将得到的隐藏状态 $s_i$ 喂给 RNN 模型,然后像正常 RNN 模型一样进行训练即可。
当然,通常我们不会对 ELMo 中的语言模型进行训练,我们固定其隐藏状态,即双向 LSTM 中的参数,我们要学习的只是 ELMo 中的最后一步加权求和时的权重参数(即之前提到的 $s_2, s_1, s_0$)。在我们的词性标注任务开始时,我们将这些权重设置为一些随机值,然后我们根据任务的表现来更新这些权重,即我们利用下游任务来学习如何对 ELMo 中这些不同层的隐藏状态的连接向量进行线性组合,即如何选择权重来对连接向量进行加权求和。所以,实际上模型学习到的参数就是由这些权重值所组成的向量。
2.5 ELMo 的表现如何?
以下是 ELMo 在一些任务中的表现:

- SQuAD:一个非常著名的问答数据集(QA)
- SNLI:文本蕴含数据集(textual entailment)
- SRL:语义角色标注数据集(semantic role labelling)
- Coref:共指消解数据集(coreference resolution)
- NER:命名实体识别数据集(named entity recognition)
- SST-5:情感分析数据集(sentiment analysis)
左侧是 ELMo 之前的一些其他方法在这些任务上的最佳表现,右侧第一列是 BASELINE 方法的表现。作者所做的就是提取文档中每个句子的上下文表示,然后给每个单词连接上 ELMo 的上下文嵌入,对应右侧第二列 ELMo + BASELINE 的表现。可以看到,在大部分任务上都有显著提升。这里,我们并没有改变原有模型的架构,我们只是加入了一些单词的上下文嵌入信息,同时,也没有额外引入过多参数,因为学习的参数只是那些隐藏状态连接向量的权重(仅仅相当于 ELMo 模型的层数)。
2.6 其他发现
-
低层表示 $=$ 捕获句法(syntax)信息
一个有趣的发现是低层的表示(例如:第一层 LSTM 中的隐藏状态)倾向于捕获更多关于该单词的句法信息。因此,非常适用于 词性标注 (POS tagging) 、命名实体识别 (NER) 等任务。 -
高层表示 $=$ 捕获语义(semantics)信息
第二层 LSTM 中的隐藏状态捕获到的更多是关于单词语义方面的信息,因此,更适用于一些理解相关任务,例如:问答系统 (QA) 、文本蕴含 (textual entailment) 、情感分析 (sentiment analysis) 等等。
那么,这些特性是如何被发现的呢?
很简单,只需要观察一下如何解释从文本中学习到的关于隐藏状态连接向量的权重。例如:当下游任务是词性标注时,我们会发现第一层 LSTM 学习到的隐藏状态连接向量的权重值往往非常大;而在下游任务是情感分析时,我们会发现第二层 LSTM 学习到的隐藏状态连接向量的权重值非常大。
2.7 上下文 vs. 上下文无关
这里是一些关于上下文表示和上下文无关表示的定性分析,我们可以看一下两种方式学习到的词义有什么差别:

我们有一些上下文无关的 GloVe 词嵌入,可以看到对于单词 “$\textit{play}$”,我们可以得到一些最相近的单词,例如:“$\textit{playing}$”、“$\textit{game}$”、“$\textit{games}$” 等,这些单词的 GloVe 嵌入都和单词 “$\textit{play}$” 的 GloVe 嵌入相似度非常高。
但是,对于 ELMo,我们可以用它返回一些相似的句子,在这些句子中,给定的目标单词具有相同的词义。例如:对于单词 “$\textit{play}$”,在我们的第一个源句子的上下文中,它表示运动方面的含义,如果我们计算其上下文嵌入,然后计算 “$\textit{play}$” 在其他句子中的上下文嵌入,并与第一个源句子得到的上下文嵌入进行比较,我们会发现一些最相近的句子,在这些句子中,“$\textit{play}$” 具有和第一个源句子中相同的上下文含义,即同样表示运动方面的含义。而在第二个源句子中,“$\textit{play}$” 的含义则与戏剧方面相关,因此,ELMo 得到的最相近的句子中的 “$\textit{play}$” 含义同样与戏剧方面相关。
这种在不同上下文中含义上的差异是在上下文无关的词嵌入(例如:GloVe)中无法体现出来的。此外,从这个例子中,我们也可以学到如何简单地将这种上下文表示的词嵌入应用到 词义消歧(word sense disambiguation)任务中。
2.8 RNN 的缺点
但是,ELMo 同样存在一些缺点,因为其使用的是基于 RNN 模型的方法。
-
序列处理(Sequential processing):难以扩展到非常大的语料库和模型上。
由于使用 RNN,序列处理是不可避免的步骤。当我们想要计算句子中最后一个单词的上下文表示时,我们无法立即直接进行计算,我们需要先计算句子中倒数第二个单词的上下文表示,而这又需要我们先计算句子中倒数第三个单词的上下文表示。所以,由于 RNN 的特性,我们必须从句子的第一个单词开始依次计算单词的上下文表示。因此,基于 RNN 的方法很难扩展到非常大的语料库和模型上。 -
RNN 模型是从左向右运行的(只能捕获到单侧的上下文信息)。
原始的 RNN 模型是单向的,因此我们只能捕获到目标单词左侧的上下文信息。RNN 的这种设计理念是基于我们希望得到一个格式正确的句子概率,我们希望计算得到的所有可能句子的概率之和为 1,因此 RNN 被设计为从左向右的单向语言模型。但这样带来的问题是我们无法捕获目标单词另一侧的上下文信息。 -
双向 RNN(Bidirectional RNN)可以在一定程度上解决这个问题,但是它只能捕获到表面的双向表示的交互信息。因为在处理单词的时候,ELMo 中的前向 RNN 模型和后向 RNN 模型彼此之间并不存在交互。我们只是对这两个独立的 RNN 的输出进行了简单地连接操作。
3. BERT
因此,我们将继续介绍一种更加高效的上下文表示的学习模型:BERT,它是目前为止表现最好的模型之一。
3.1 BERT
BERT 意为 基于 Transformers 的双向编码器表示(Bidirectional Encoder Representations from Transformers)。
-
Devlin et al. (2019): https://arxiv.org/abs/1810.04805
- BERT 使用 自注意力网络(self-attention networks),又称 Transformers,来捕获单词之间的依赖关系。
- 这种方式的主要优点在于无需进行序列处理。
不同于基于 RNN 模型的 ELMo,我们可以使用 BERT 直接计算句子中某个单词的上下文嵌入而不必先计算其前面单词的嵌入。因此,可以很容易扩展到非常大的语料库上。
- 这种方式的主要优点在于无需进行序列处理。
- BERT 还使用 掩码语言模型(masked language model)来捕获深度双向表示。
在之前的 ELMo 中,我们看到其只捕获了表面的双向表示,因为前向和后向语言模型之间是相互独立的。而在 BERT 中,我们稍后将看到 Transformers 使用单个模型同时捕获两个方向的上下文信息。 - 失去了生成语言的能力。
BERT 无法单独进行语言生成任务,它无法计算有效的句子概率,也无法从左至右生成句子。 - 但是,这不是一个很大的问题,如果我们的目标只是学习单词的上下文表示。
如果我们的目标只是高效地生成单词的双向上下文表示,那么 BERT 无法生成语言并非一个很大的问题,因为我们可以将其与其他语言模型结合来实现语言生成。
3.2 ELMo vs. BERT 架构对比
这里是 ELMo 和 BERT 的架构图表示:
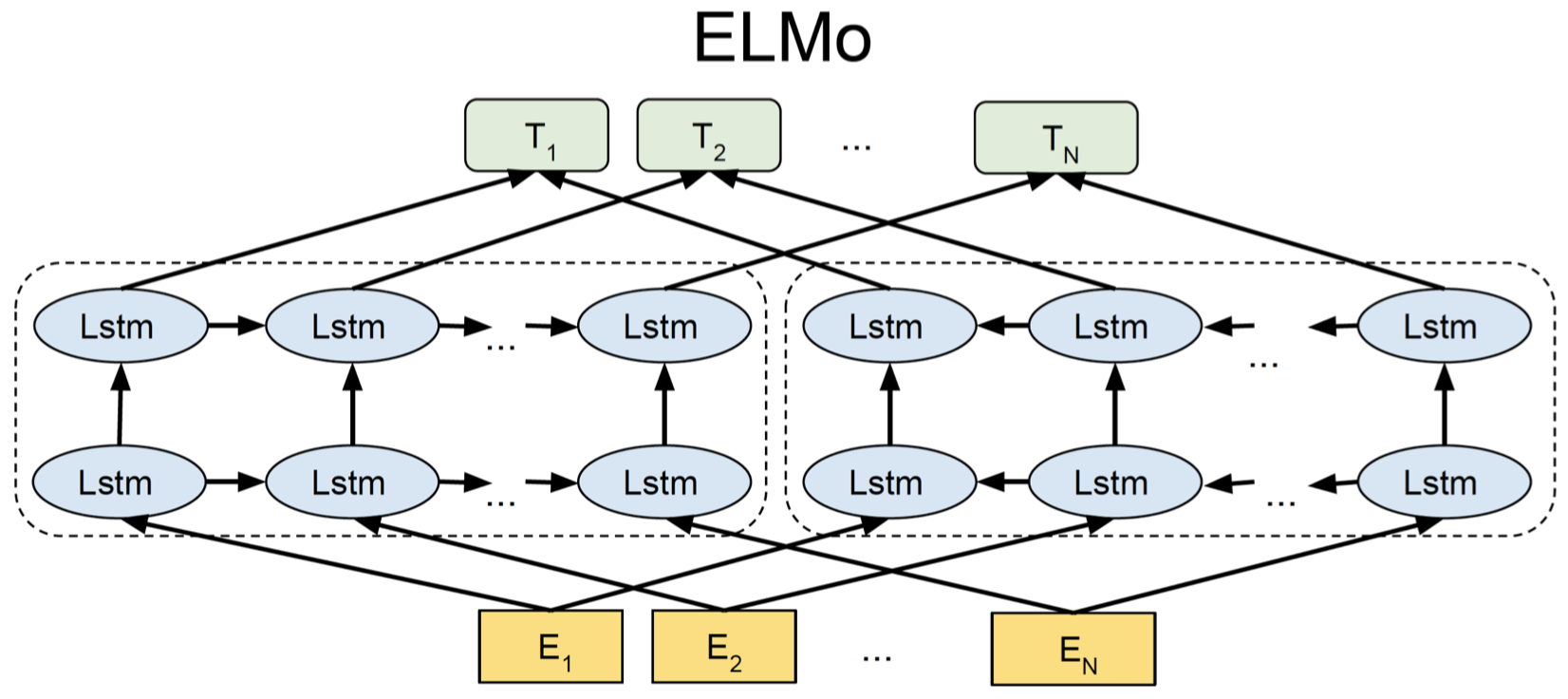
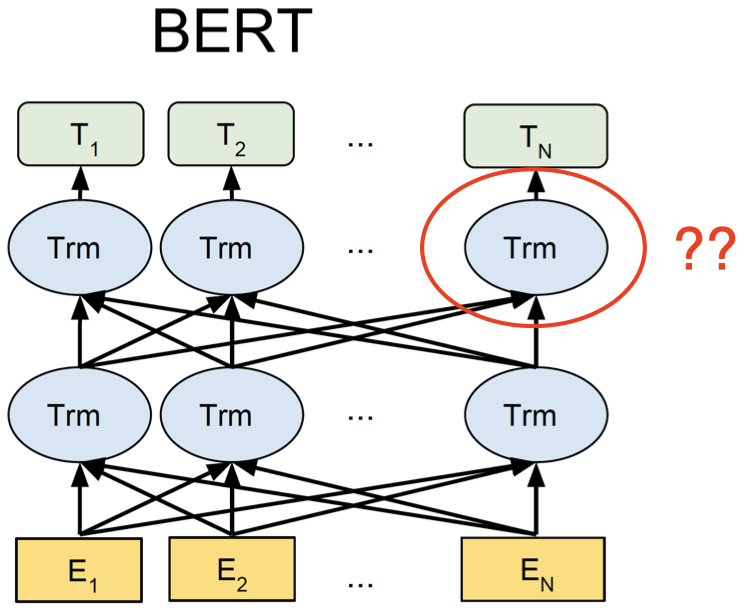
上面是 ELMo 的架构图,其中下面的黄色方块表示输入单词。可以看到,ELMo 具有一个从左至右的 LSTM 和一个从右至左的 LSTM 模型,我们将单词序列分别输入给这两个 RNN 语言模型,然后我们将两个模型输出的隐藏状态向量进行连接得到双向的上下文信息。但是,这两个 LSTM 语言模型在处理单词的过程中并没有任何交互。
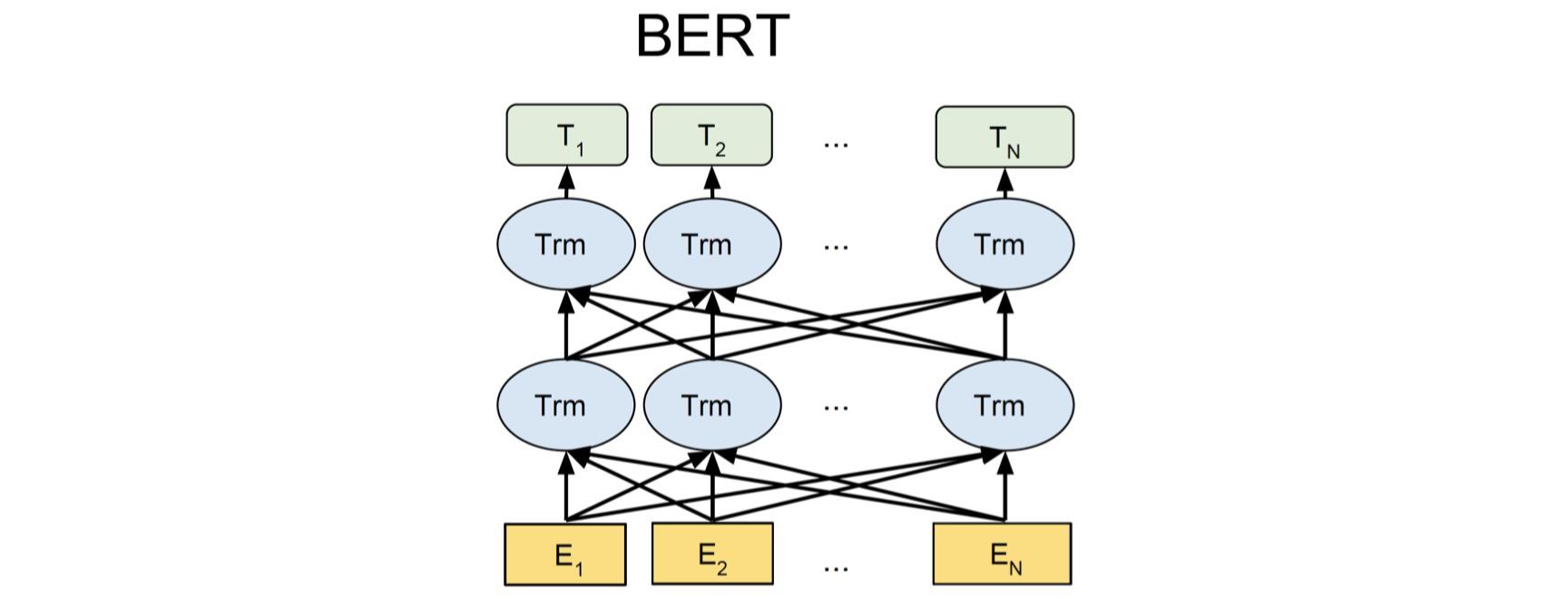
上面是 BERT 的架构,其中每个蓝色椭圆表示 Transformer。假设现在我们要计算第二个单词 $E_2$ 的上下文表示,Transformer 会查看单词 $E_2$ 周围的所有上下文单词,即从 $E_1$ 到 $E_N$ 的整个单词序列,然后计算一个集合表示(aggregate representation)作为单词 $E_2$ 的上下文表示。然后我们会经过一系列的 Transformers,每一层都执行类似的操作,例如:第二层的 Transformers 会将所有第一层 Transformers 的输出作为输入,并将它们结合起来,计算得到最终的上下文表示 $T_2$。由于这里我们使用单个模型来捕获两个方向的上下文信息,模型可以捕获到不同的两侧上下文单词之间更深层次的关系。
3.3 目标 1:掩码语言模型
我们前面提到过 BERT 使用了 掩码语言模型(Masked Language Model)。
- 随机 “掩去(mask)” $k\%$ 的 tokens。
- BERT 的目标:正确预测出被掩去的单词(masked words)。
例如,现在我们有以下句子:

首先,我们在预处理时随机 “掩去” 两个单词:“$\textit{lecture}$” 和 “$\textit{and}$”,将它们用 “$\text{[MASK]}$” 代替。然后,我们将处理后的句子喂给 BERT,然后训练 BERT 并让其预测这两个 “$\text{[MASK]}$” 所对应的原始单词。这个过程和 RNN 语言模型有些类似,在 RNN 语言模型中,我们同样需要预测单词,只是由于 RNN 是单向模型,我们在预测第一个 “$\text{[MASK]}$” 所对应的原始单词时,我们将只基于其左侧的上下文单词信息 “$\textit{Today}$”、“$\textit{we}$”、“$\textit{have}$”、“$\textit{a}$” 来预测单词 “$\textit{lecture}$”,而并没有使用其右侧的上下文信息。这里的掩码语言模型的不同在于,我们将同时使用两侧的上下文单词信息来进行预测。
3.4 目标 2:预测下一个句子
BERT 的第二个目标是预测接下来的句子。
- 这使得 BERT 可以学习句子之间的关系。
- BERT 的目标是预测句子 B 是否紧跟在句子 A 后面。
- 这个预训练目标对于需要分析句子对的下游应用(例如:文本蕴含、句子相似度)非常有用。

例如,在上面左边的两个句子,我们希望 BERT 的预测结果是句子 B 是句子 A 的下句,因为两个句子之间的衔接非常自然;而对于右边的两个句子,我们希望 BERT 的预测结果是句子 B 不是句子 A 的下句,因为二者没什么直接关系。
我们并不需要专门的带标签数据,因为对于正样本,我们只需要给定一个语料库,然后从中选取两个相邻的句子,就可以得到 “IsNextSentence” 标签的句子对。对于负样本,我们只需要随机选取一个句子,然后再从语料库中随机抽样得到另一个句子,即可得到 “NotNextSentence” 标签的句子对。因此,我们不需要专门准备一个带标签的数据集。
3.5 训练/模型细节
-
BERT 使用 WordPiece (subword) Tokenisation
类似之前在文本预处理中学过的 BPE(Byte-Pair Encoding) 算法,不同点在于,WordPiece 基于概率生成新的 subword 而不是下一最高频字节对。 - BERT 使用多层 Transformers 来学习上下文表示。
- 模型训练在 Wikipedia+BookCorpus 上完成。
- 训练需要在多个 GPU 上运行好几天。
3.6 BERT 微调(Fine-Tuning)
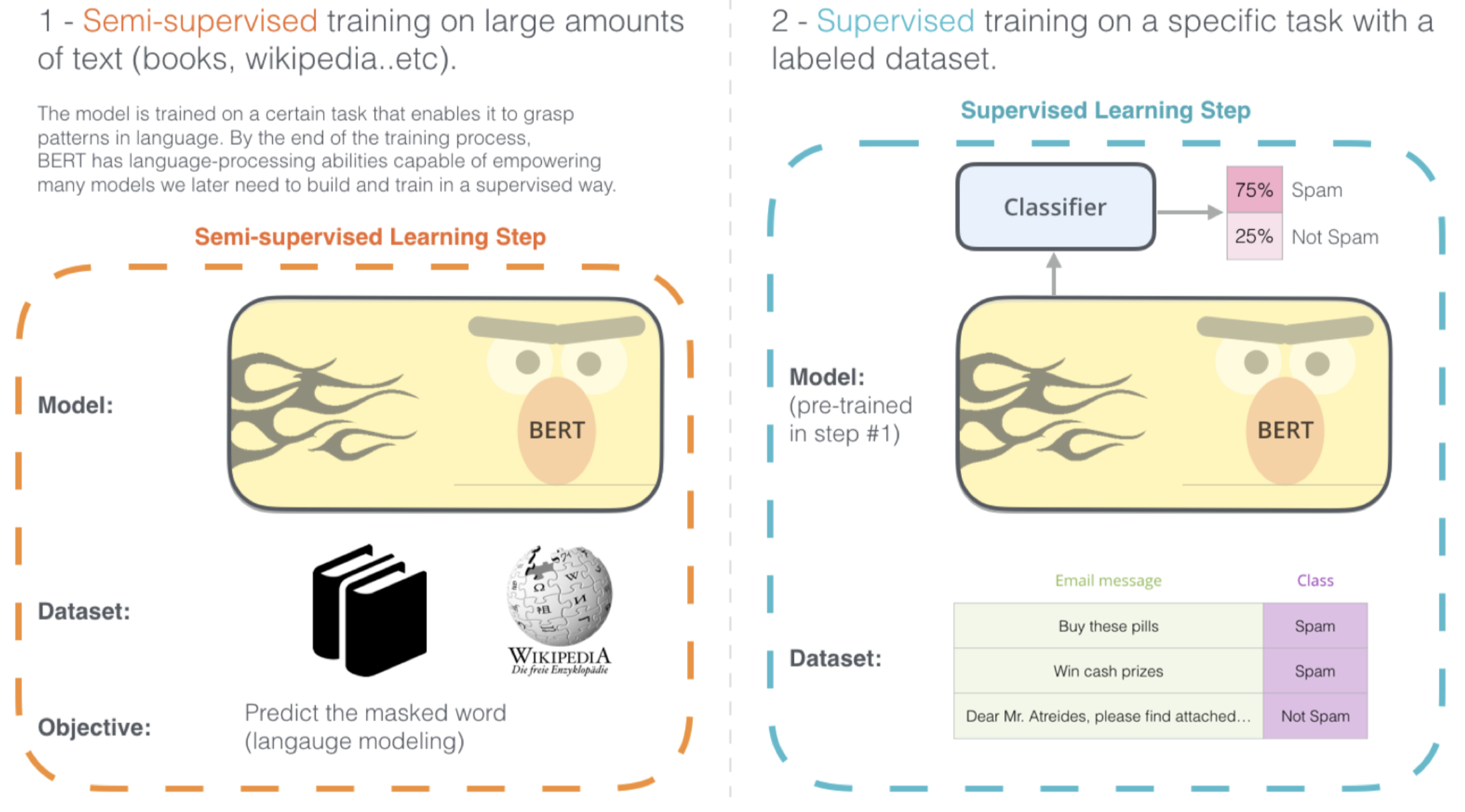
首先,在一个大的语料库上对 BERT 进行预训练,这一步是无监督学习,因为这里的目标任务是掩码语言模型和预测下一个句子,我们无需准备带标签数据集。因此,我们基于这两个任务在一个很大的语料库(例如:Wikipedia+BookCorpus)上对 BERT 进行预训练。
一旦预训练完成之后,假如我们希望将基于 BERT 的上下文表示应用到下游任务中,例如现在我们有一个垃圾邮件检测任务,我们有一个由邮件信息和类别标签组成的垃圾邮件分类数据集。我们要做的就是将数据集中的邮件信息喂给 BERT,得到这些邮件信息的上下文表示,然后,我们在 BERT 之上再增加一个分类器层用于分类。所以,我们将 BERT 输出的词上下文表示输入分类器(例如:多层感知器)进行分类。然后在训练时,我们可以同时更新分类器和 BERT 内部的参数。
3.7 例子:垃圾邮件检测
现在,让我们来看一下具体如何利用 BERT 实现垃圾邮件检测。
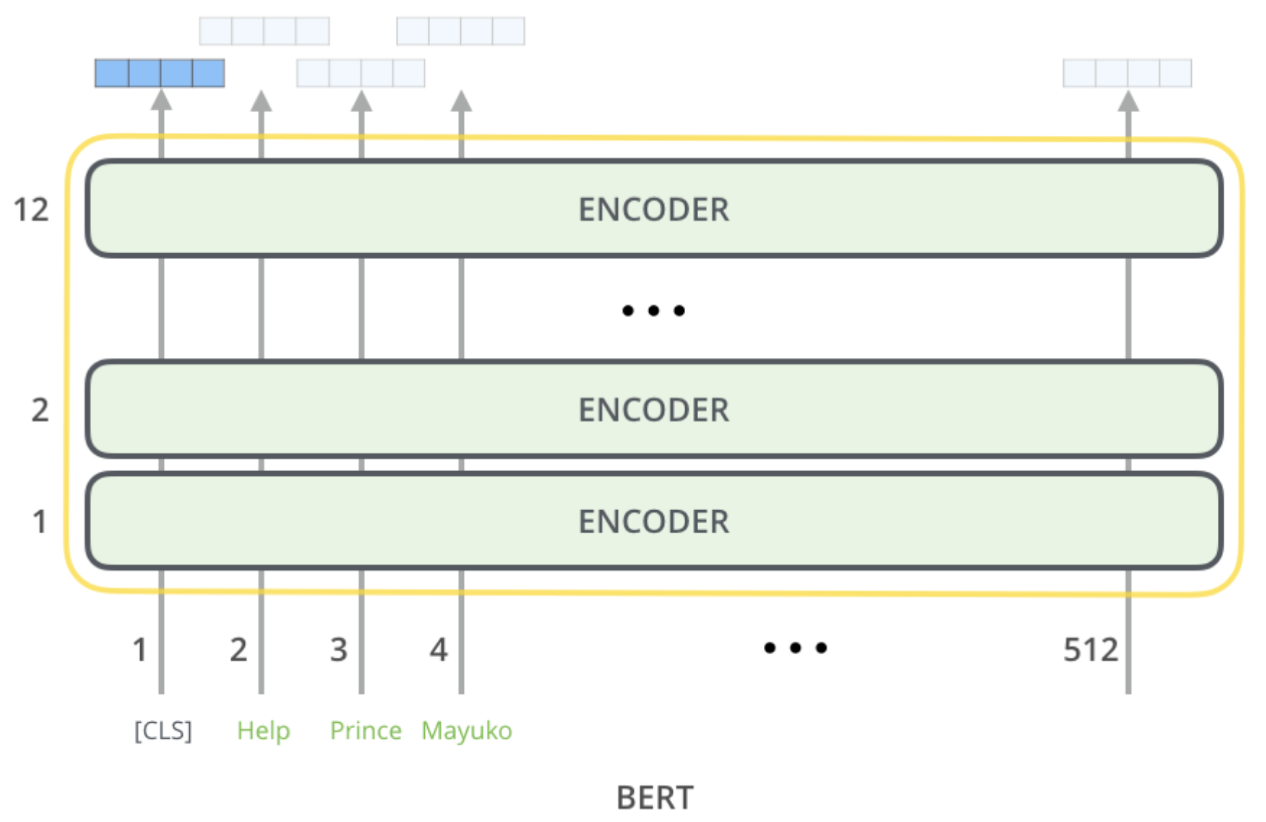
在 BERT 的数据集预处理过程中,我们需要做的是在数据集中的每个句子前面加上一个特殊的 token “$[\text{CLS}]$”,然后将整个句子喂给 BERT。我们有很多 ENCODER 层,每一个 ENCODER 都是一个 Transformer,然后,BERT 会返回每个输入单词 token 的上下文表示。现在,所有这些词嵌入都是基于上下文的,因为我们通过多层 Transformer 的注意力机制整合了所有输入单词的信息。

然后,我们仅将 “$[\text{CLS}]$” 这一个 token 的上下文表示输入分类器层(忽略其他单词的上下文表示),分类器层可以是由简单的前馈神经网络加上 softmax 分类器组成,然后进行垃圾邮件分类。非常重要的一点是,当我们希望利用下游任务(垃圾邮件分类)来训练模型/微调模型参数时,我们不仅更新分类器(前馈神经网络)中的参数,同时也会更新 BERT 中的参数。我们当然也可以只更新分类器中的参数,但是在实践中,这种做法的效果并不理想。
3.8 BERT vs. ELMo
那么,BERT 和 ELMo 到底在哪些方面存在差异呢?
-
ELMo 只能提供单词的上下文表示。
两者都可以提供单词的上下文表示,但是 ELMo 只能提供单词的上下文表示,ELMo 需要另外提供下游应用的神经网络架构。回忆一下之前 ELMo 的例子,我们有单独的 baseline 模型(有自己的神经网络架构),ELMo 仅仅提供单词的上下文表示,我们还需要提供用于下游任务的单独的神经网络架构。 -
当应用于下游应用时,ELMo 的上下文表示是固定的。
另一个主要区别是,当我们利用下游任务进行训练/微调时,ELMo 中用于学习上下文表示的语言模型的参数是固定的(没有训练),这个过程中,唯一得到训练的参数是赋予来自不同 LSTM 层隐藏状态连接向量的权重(例如:$s_2,s_1,s_0$)。我们并不会对 ELMo 中的 LSTM 层的参数进行更新。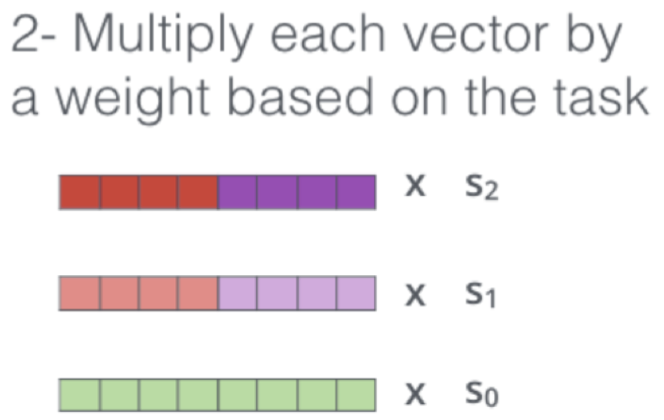
- BERT 为下游任务增加了一个分类层。
- 无需特定任务的模型
BERT 不需要另外单独的下游任务模型。BERT 提供了单词的上下文表示,我们要做的只是为下游任务增加一个分类层。
- 无需特定任务的模型
- BERT 在微调时会更新所有参数。
3.9 BERT 的表现如何?
下面是 BERT 在一些 NLP 任务上的表现:
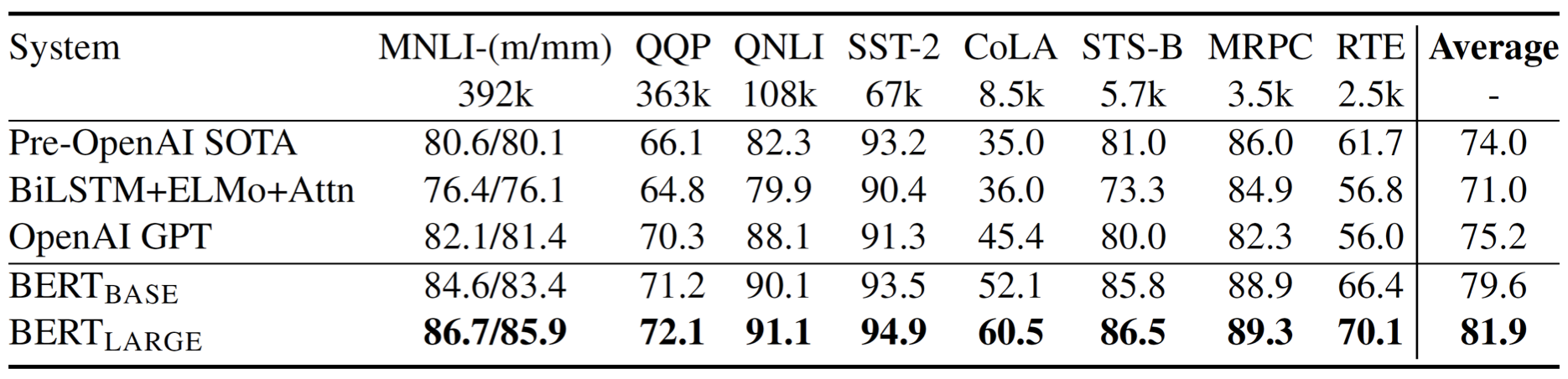
- MNLI, RTE:文本蕴含(textual entailment)
- QQP, STS-B, MRPC:句子相似度(sentence similarity)
- QNLP:可回答性预测(answerability prediction)
- SST:情感分析(sentiment analysis)
- COLA:句子可接受度预测(sentence acceptability prediction)
BERT 在所有任务上都取得了非常好的表现。此外,BERT 发布了 2 种版本:\(\text{BERT}_{\text{BASE}}\) 和 \(\text{BERT}_{\text{LARGE}}\)。其中,\(\text{BERT}_{\text{LARGE}}\) 的参数数量要比 \(\text{BERT}_{\text{BASE}}\) 的参数数量更多一些。
3.10 Transformers
我们已经见过了 BERT 中的 Transformers,那么,到底什么是 Transformers?它们又是如何工作的呢?
3.11 Attention is All You Need
- Vaswani et al. (2017): https://arxiv.org/abs/1706.03762
- Transformers 使用 注意力机制(attention)替代 RNN(或者 CNN)来捕获单词之间的依赖关系。
这里是一个如何利用注意力机制捕获单词之间依赖关系的例子:
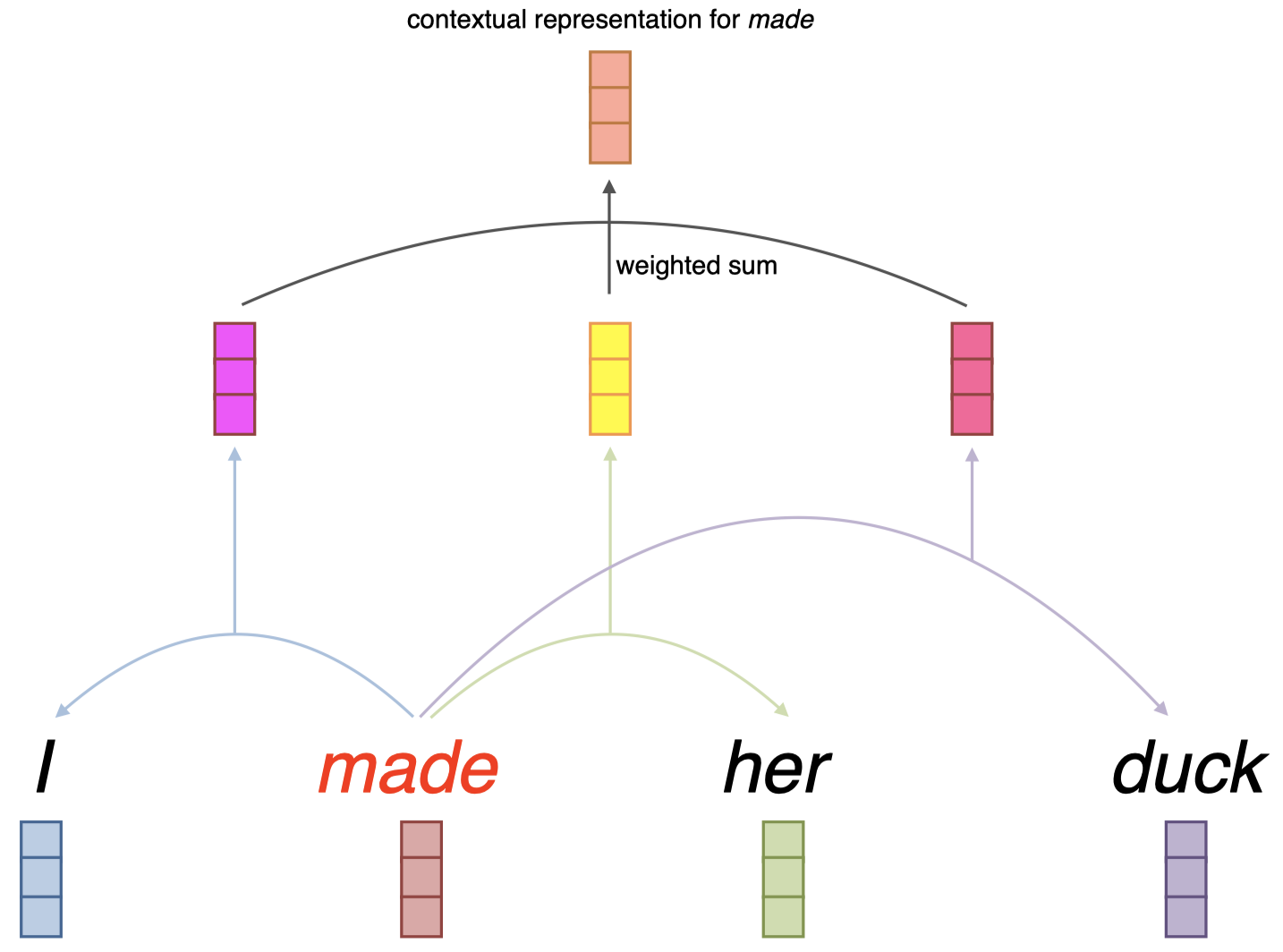
假设现在我们有一个句子 “$\textit{I made her duck}$”,我们希望计算其中单词 “$\textit{made}$” 的上下文嵌入。我们需要先分别单独观察单词 “$\textit{made}$” 周围的单词,例如,对于单词 “$\textit{I}$”,我们将结合单词 “$\textit{made}$” 和 “$\textit{I}$”,组合得到一个向量(第二层中的亮紫色向量)。这个过程称为 注意力(attention),因为我们这里将注意力放在一个特定单词(“$\textit{I}$”)上。然后,对于第二个单词 “$\textit{her}$” 进行相同的操作,得到一个表征了单词 “$\textit{made}$” 和 “$\textit{her}$” 的复合向量(第二层中的亮黄色向量)。同理,对于最后一个单词 “$\textit{duck}$” 也一样,我们得到一个复合向量(第二层中的桃红色向量)。这三个复合向量分别捕获了单词 “$\textit{made}$” 周围的三个上下文单词。然后,我们对这三个复合向量进行加权求和,得到单词 “$\textit{made}$” 的上下文表示。
这就是注意力机制的核心思想。所以,可以看到,这里并没有涉及序列处理,因为假如现在我们要计算单词 “$\textit{duck}$” 的上下文表示,我们可以直接计算其周围单词的注意力组合,而无需先计算出其前一个单词 “$\textit{her}$” 的上下文表示。实际上,第二层的三个复合向量可以采用并行方式计算,因此,这里不涉及序列处理,这也是和基于 RNN 这种序列模型的 ELMo 相比,BERT 能够很好地扩展到大型语料库上的原因。
3.12 自注意力机制:实现
我们这里进一步介绍这种 自注意力机制(Self-Attention)的实现。
- 输入:3 个向量
- 查询向量(query vector)$q$
查询向量是目标单词的向量,例如:“$\textit{made}$”。 - 键向量(key vector)$k$ 和 值向量(value vector)$v$
键、值向量是目标单词周围单词的向量,例如:“$\textit{her}$”。
- 查询向量(query vector)$q$
- 查询、键、值都是 向量。
- 它们都是来自单词嵌入的线性投影(linear projections)。
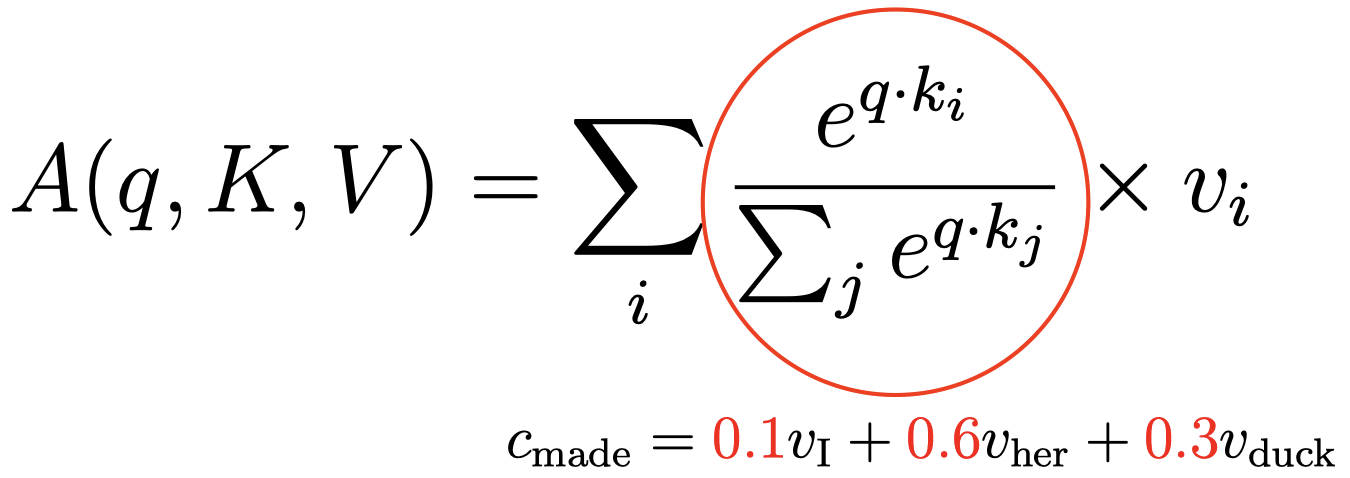
例如,假设现在我们有单词 “$\textit{made}$” 和 “$\textit{her}$” 的嵌入。我们将单词 “$\textit{made}$” 的嵌入投影到一个查询向量 $q$,然后将单词 “$\textit{her}$” 的嵌入投影到一个键向量 $k$,并再次将单词 “$\textit{her}$” 的嵌入投影到一个值向量 $v$。然后,当我们试图计算单词 “$\textit{made}$” 的上下文表示时,如之前例子中演示的,我们将对复合向量 $v_I$,$v_{her}$,$v_{duck}$ 进行加权求和,其中 $v_I$ 是单词 “$\textit{I}$” 的值向量,$v_{her}$ 是单词 “$\textit{her}$” 的值向量, $v_{duck}$ 是单词 “$\textit{duck}$” 的值向量,这些值向量都是对应单词嵌入的投影向量。
那么,这里的权重值 $0.1$,$0.6$ 和 $0.3$ 又是如何得到的呢?
这是基于上面的 $A(q,K,V)$ 的计算公式,它给出了某个特定单词的上下文表示。其中,$v_i$ 对应不同注意力组合的投影向量 $v_I$,$v_{her}$,$v_{duck}$。对应的权重是通过红圈内的表达式计算得到的。我们简单地计算目标单词的查询向量 $q$ 和对应上下文单词的键向量 $k_i$ 的点积,然后在所有上下文单词上进行 $\text{softmax}$ 计算。
例如:上面例子中,$v_I$ 的权重为 $\dfrac{e^{q_{made}\cdot k_{I}}}{e^{q_{made}\cdot k_{I}}+e^{q_{made}\cdot k_{her}}+e^{q_{made}\cdot k_{duck}}}=0.1$
-
基于注意力机制的单个单词的上下文表示计算公式:
\[A(q,K,V)=\sum_i \dfrac{e^{q\cdot k_i}}{\sum_j e^{q\cdot k_j}}\times v_i\]当我们有多个查询向量时(即需要同时计算多个单词的上下文表示时),我们可以将它们堆叠为矩阵形式:
\[A(Q,K,V)=\text{softmax}(QK^{\mathrm T})V\] -
Transformers 还使用 缩放后的点积(scaled dot-product)来避免计算得到的数值过大:
\[A(Q,K,V)=\text{softmax}\left(\dfrac{QK^{\mathrm T}}{\sqrt{d_k}}\right)V\]其中,$d_k$ 表示查询向量(query)和键向量(key)的维度。
因为我们进行了很多点积操作,所以最终得到的值可能非常大,Transformers 对此处理非常简单,就是直接将点积结果除以一个标量 $\sqrt{d_k}$。
3.13 多头注意力机制
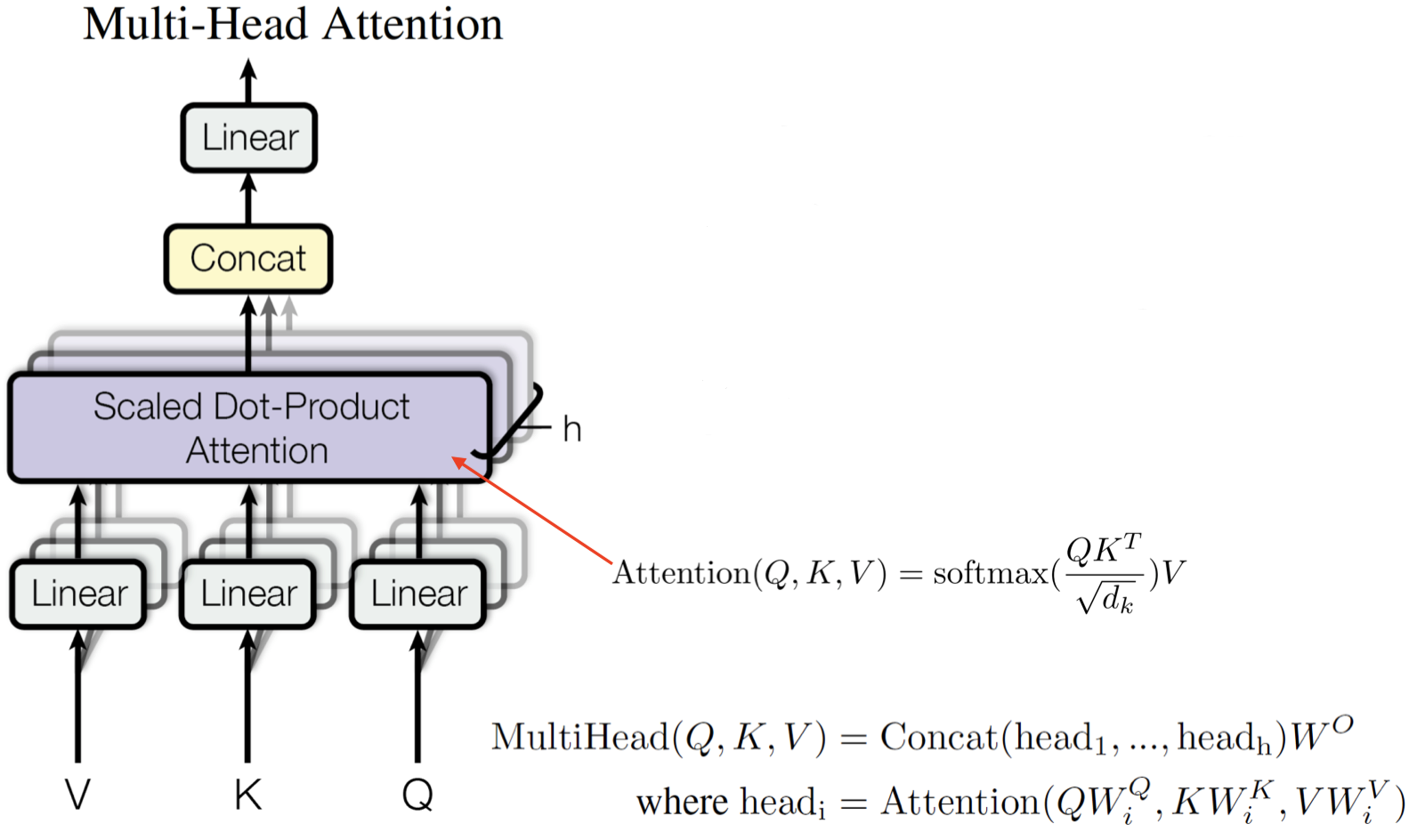
此前我们看到的是,每一个单词对只有一个注意力(attention),例如:对于单词 “$\textit{made}$”,我们在计算注意力时,每次只考虑一个上下文单词(例如:“$\textit{I}$”)。但是,论文作者还提出了一种 多头注意力机制(multi-head attention),就是简单地将这个步骤重复多次以允许多次交互。
这里,我们有查询、键、值向量 $V,K,Q$,然后我们有一个之前提过的经过缩放的点积自注意力层。现在我们所做的就是将这个过程重复多次,这个过程可以并行化。然后,我们将得到的结果进行连接。这意味着我们将允许模型捕获这些单词对之间的不同类别的交互。具体公式如上所示,对于每一个头 $\text{head}_i$,我们进行一次注意力计算 $\text{Attention}(QW_i^{Q},KW_i^{K},VW_i^{V})$。因为有多个头,我们可以多次线性投影所有的查询、键、值向量,所以每一个头 $\text{head}_i$ 都有一个自己的投影矩阵 $W_i$。将计算得到的所有 $\text{head}_i$ 进行连接,然后再进行一次线性投影计算得到多头注意力 $\text{MultiHead}(Q,K,V)$。
3.14 Transformer 块
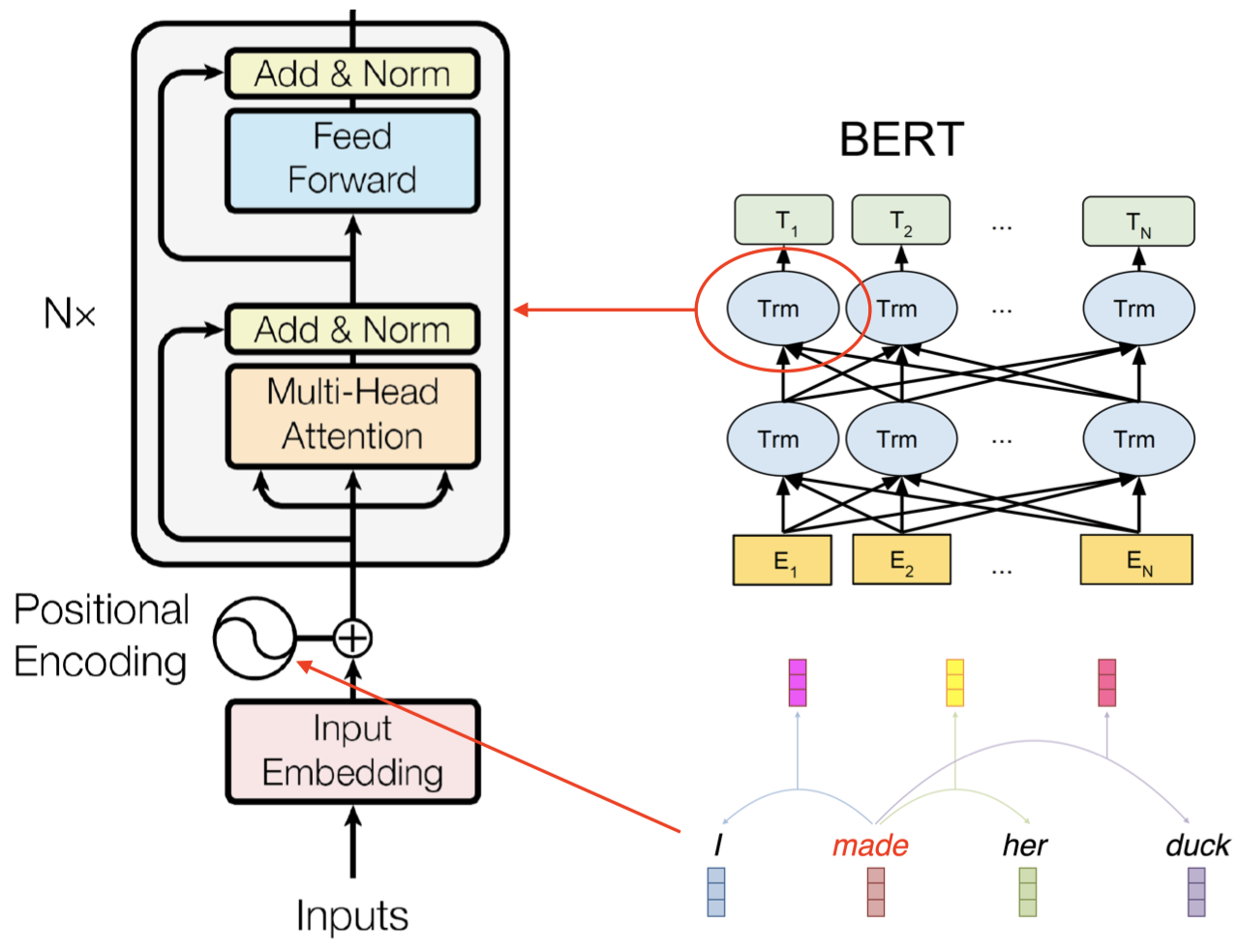
可以看到,完整的 Transformer 块中还包含看一些其他操作。给定一个输入,我们先对其进行嵌入计算,然后计算查询、键、值向量,并在此基础上计算多头注意力的向量。然后,我们将之前查询、键、值向量的结果再加入到多头注意力的结果中进行归一化处理(normalization)。这意味着,我们从注意力网络中得到第一个单词的上下文表示 $T_1$ 后,我们再回过头来将原单词的嵌入 $E_1$ 加入到 $T_1$ 的结果中,这种做法被称为 残差连接(residual connection),其理由是我们不希望模型忽略原单词的嵌入信息。然后,我们将通过残差连接以及归一化得到的结果喂给一个前馈网络,并再次进行归一化操作。这就是在一个 Transformer 模型中所发生的全部事情。
另外,在输入 Transformer 块之前的位置编码(Positional Encoding)又指的是什么呢?回忆一下,当我们计算注意力(attention)时,例如:我们要计算单词 “$\textit{made}$” 的上下文表示时,我们每次分别独立地将注意力放在上下文单词 “$\textit{I}$”、“$\textit{her}$”、“$\textit{duck}$” 上,但是对于模型而言,它并不知道单词的位置信息:即单词 “$\textit{her}$” 是和目标单词 “$\textit{made}$” 相邻的下一个单词,单词 “$\textit{duck}$” 和目标单词 “$\textit{made}$” 的距离要更远一些等等。所以,位置编码实际上是一个向量,它编码了文本中单词的一些位置信息,例如:单词 “$\textit{duck}$” 出现在文本中的第 4 个位置,单词 “$\textit{her}$” 出现在第 3 个位置等等。因此,位置编码为模型提供了一些词序相关的信息。
4. 总结
- 我们学习了基于 ELMo 和 BERT 的单词上下文表示,以及它们在下游任务中的表现,并且也学习了如何将它们应用到下游任务中。
- 这些模型都是在非常大的语料库上训练的。
- 因此,它们构建了一些语言相关的知识。
- 使用无监督目标,模型训练无需专门提供带标签数据集。
- 由于模型是在非常大的语料库上训练的,因此,当我们将它们用于下游任务时,我们不再是从零开始(“scratch”)的状态,因为模型在某种程度上已经理解了一些单词含义相关的信息,以及单词之间的关系。所以,现在模型需要做的只是将这些理解带入下游任务的模型中进行训练。这也是这类上下文表示模型非常有用的原因之一。并且,正如 BERT 中提到的,基于大量语料库得到的预训练词嵌入在一定程度上缓解了下游任务对于数据量的需求。
5. 扩展阅读
- ELMo: https://arxiv.org/abs/1802.05365v2
- BERT: https://arxiv.org/abs/1810.04805
- Transformer: http://nlp.seas.harvard.edu/2018/04/03/attention.html
下节内容:语篇
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。 欢迎转载,并请注明来自:YEY 的博客 同时保持文章内容的完整和以上声明信息!