Lecture 04 面向事务的计算
参考教材:Transaction Processing: Concepts and Techniques, Jim Gray and Andreas Reuter, Morgan Kaufmann, 1993
本节课中,我们将介绍面向事务的计算及其相关概念。
1. 事务模型
1.1 ACID 特性
事务 (Transactions) 是数据库系统中的一个行动或者操作单元。一个事务需要满足 ACID 特性:
-
原子性 (Atomicity)
对于数据的所有更改都当作单个操作一样执行。也就是说,要么一次性执行所有更改,要么所有更改都不执行。
- 应用程序将无法直接找到失败原因。
- 也许可以通过其他方式找到失败原因,例如:通过查看系统日志或伪造成功。
-
一致性 (Consistency)
当一个事务开始和结束时,数据应当处于一致状态。(例如:银行转帐)
- 通常无法计算。
- 即使可以使用某种受限语言进行计算,也可能是不切实际的,因为这意味着巨大的计算需求。
- 只能保证受限的一致性类型,例如:后面将要讨论的可序列化交易。
- 当原子性无法满足时将出现不一致性问题,另外,当存在并发 (同时有多个事务对同一数据进行操作) 时也可能出现不一致性问题。
-
隔离性 (Isolation)
事务的执行就好像它是系统上唯一的事务一样。
- 例如:在某个应用程序中,将资金从一个帐户转移到另一个帐户,隔离性可以确保另一个事务只能在其中一个或另一个帐户中看到转移后的资金,但不会同时在两个帐户中看到,也不会在两个帐户中都看不到。
-
持久性 (Durability)
系统应该能够容忍系统故障,并且任何 已提交的更新 都不应丢失。
1.2 磁盘更新
磁盘写 (Disk writes) 为原子操作:
要么整个数据块都已正确写入磁盘,要么数据块内容未更改。为了实现原子磁盘写入,通常有两种策略:
- 双工写 (Duplex write)
- 每个数据块都被 顺序 写入两个位置 (即第一个位置写入成功后,才会在第二个位置写入)。
- 我们可以通过其 CRC 来确定磁盘块的错误。
- 每个块都与一个版本号关联。具有最新版本号的块包含了最新数据。
- 如果其中一个写入失败,则系统可以发出另一个写入。
- 它始终保证至少一个块上具有一致的数据。
-
日志写 (Logged write)
与双工写类似,不同之处在于其中一个写操作会进入日志。如果对块的更改很小,则此方法将非常高效。我们将在本课程的后面讨论另一种高效方法。
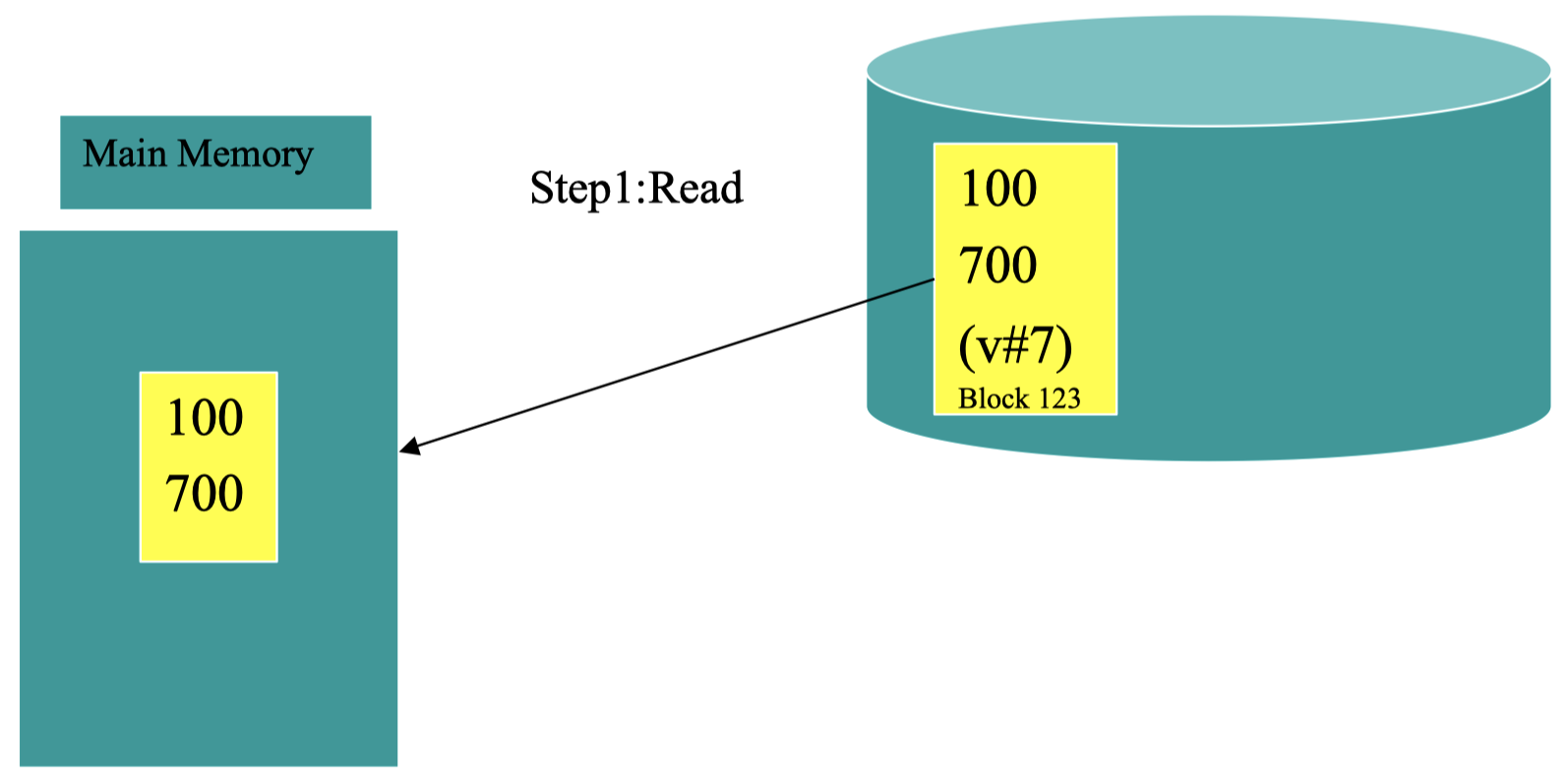
下面是一个基于双工写更新磁盘块的例子,磁盘上 ID 为 123 的块上存在一些数据信息,其版本号为 v#7,我们希望对其进行一些修改:

首先,我们将数据从磁盘上读取到主存中:
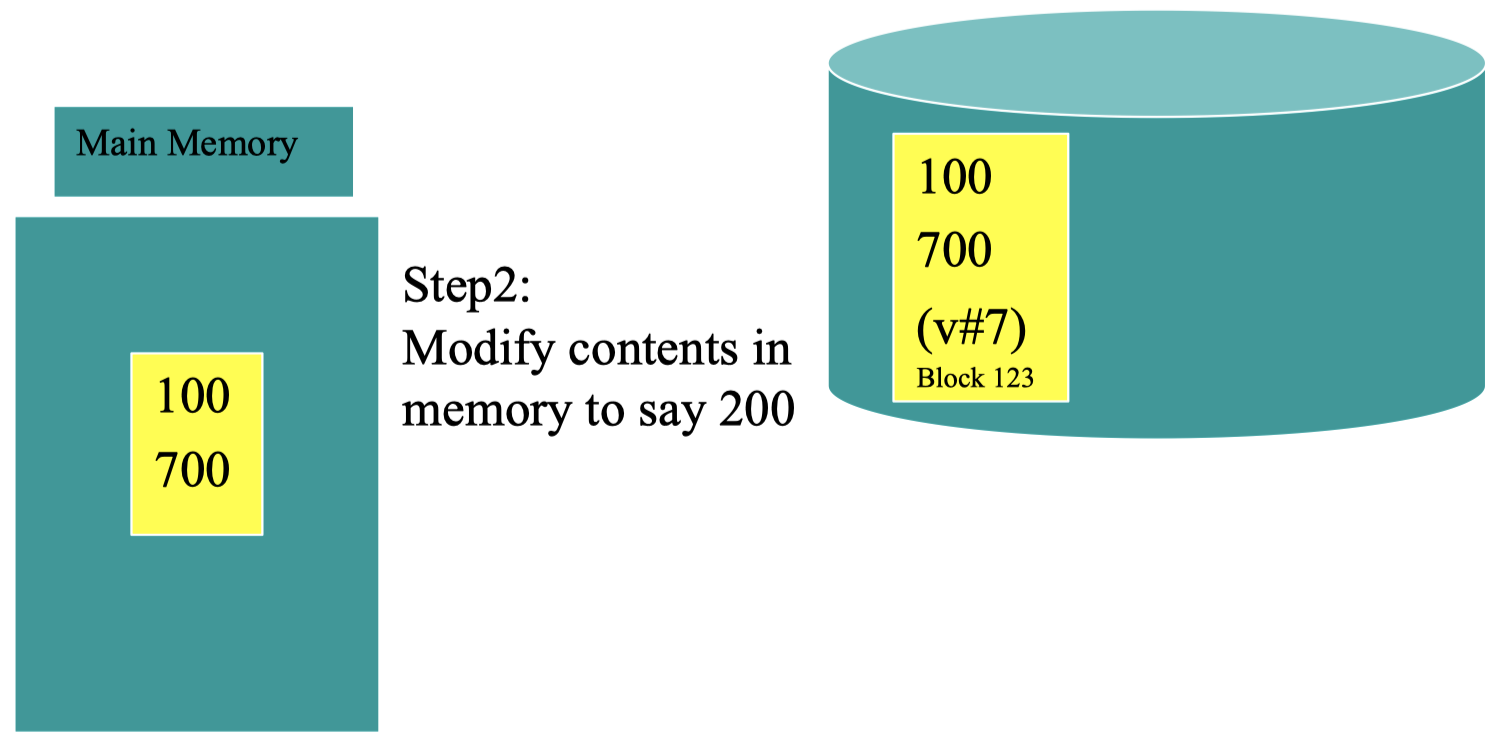
然后,我们需要对其中某些信息进行更改,例如将 100 改为 200:
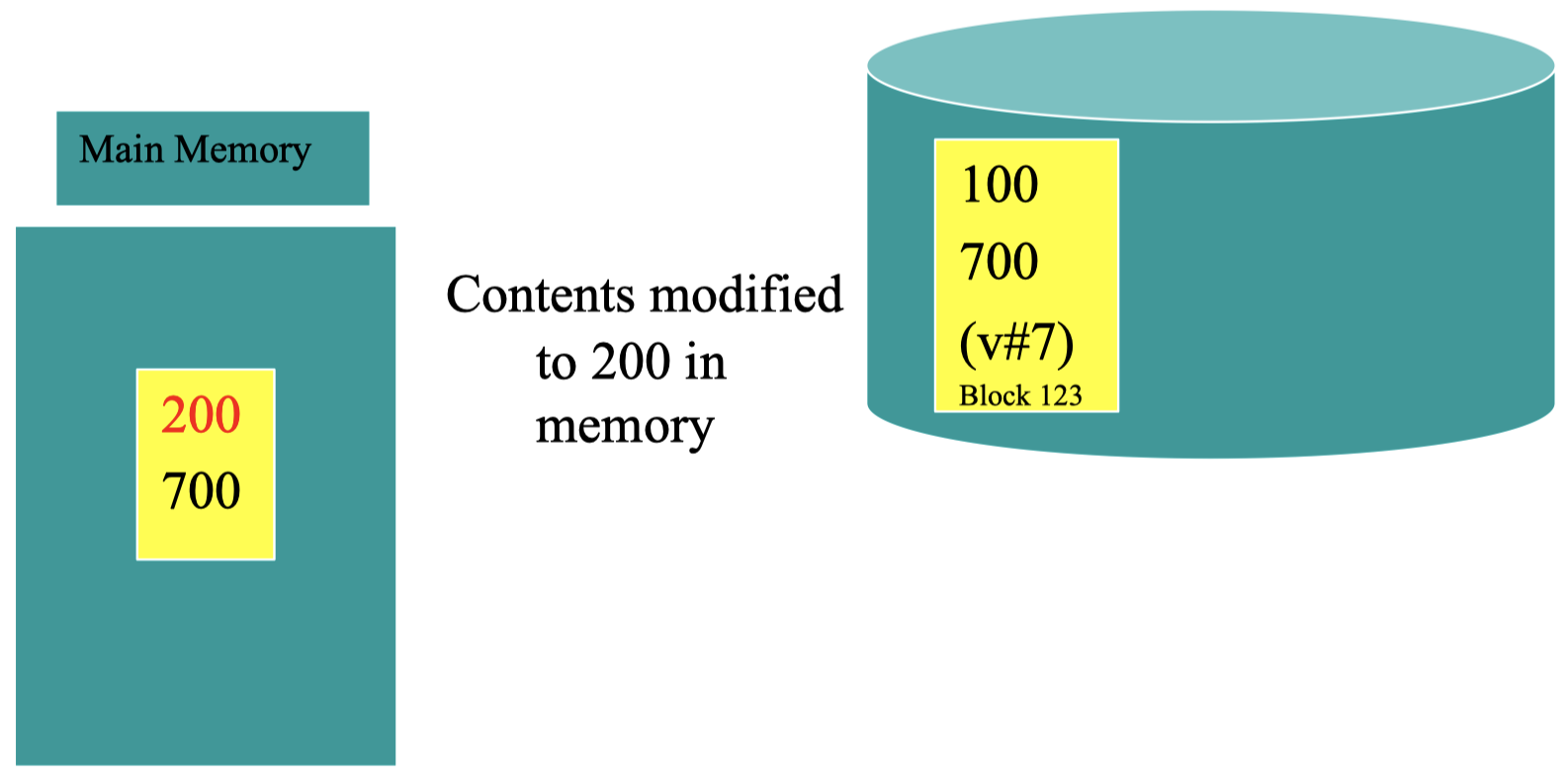
数据已经在内存中更改完成:
更改后的数据需要被写回磁盘中:
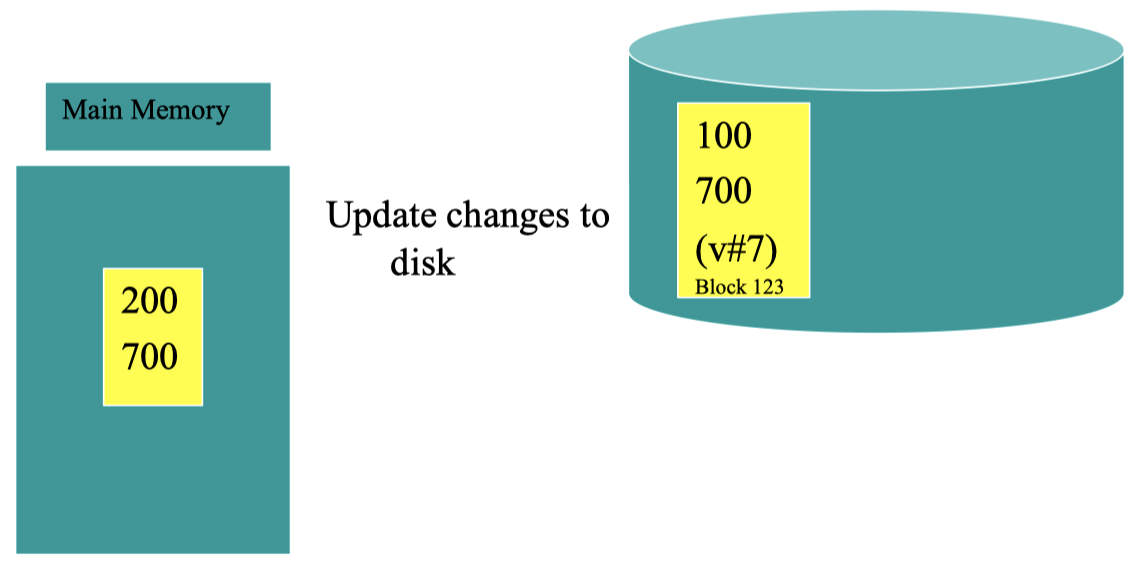
但是,我们并不会立即将更改后的数据直接写入之前数据所在的块,而是先将其写入一个新的块里 (理想情况下,可以选择在另一块磁盘上写入):
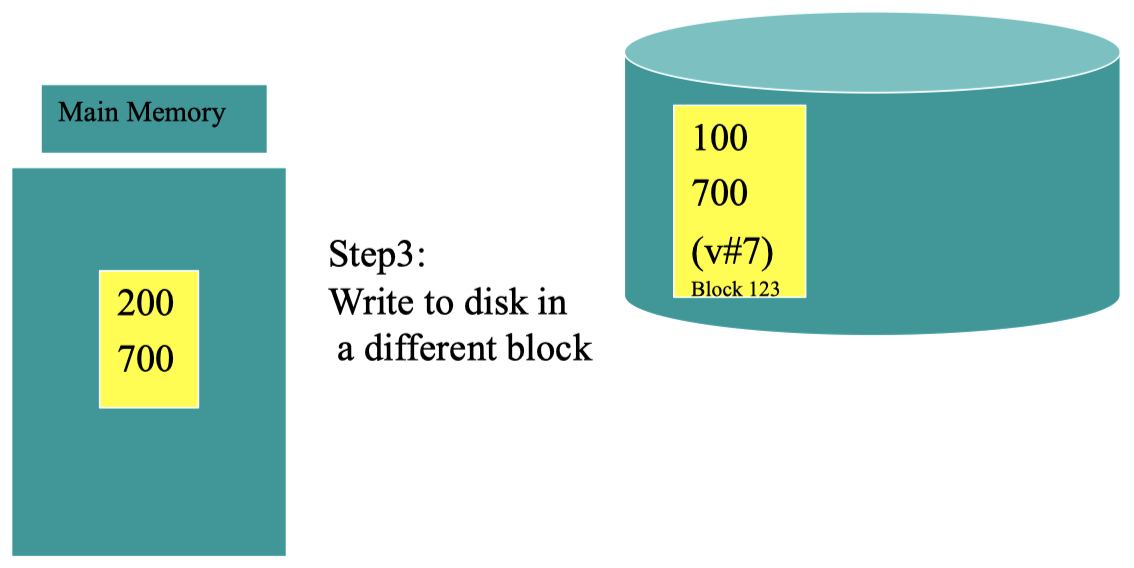
在新的数据块 (ID 为 475) 写入完成后,它会得到一个新的版本号 v#8,由于它比原始版本号 (v#7) 要大,因此,磁盘系统会将其视为最新数据。接下来,将对原始数据块 123 中的数据进行更新,并且将其版本号升级为 v#9:
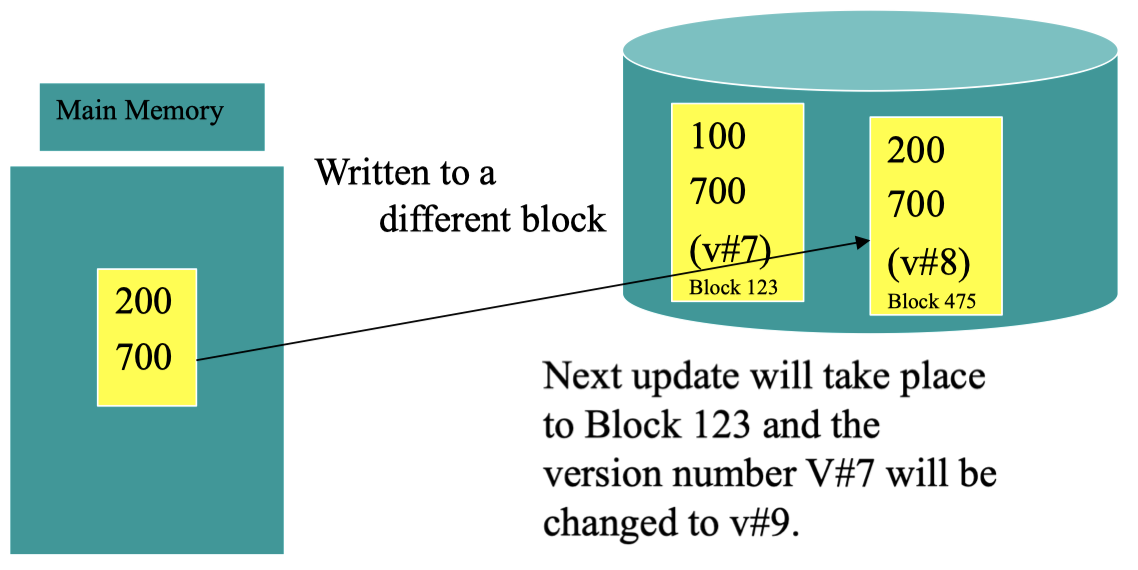
这样做的目的是:当我们在磁盘上的数据块 123 进行第二次更改写入时,即使出现故障导致更新失败,在数据块 475 上仍然保留有正确的更新之后的数据信息。
我们甚至可以利用这仅有的两个块进行交叉校验:如果最新的两个版本 v#8 和 v#9 包含相同的数据信息,说明两次写入更新都是成功的,并且数据信息都是正确的。而假如其中某个失败了,导致我们只有一个数据块信息,这种情况下,我们仍然可以采用另一种被称为 循环冗余校验 (CRC) 的技术来判断该磁盘上是否存在数据错误。
1.3 循环冗余校验 (CRC)
循环冗余校验 (Cyclic Redundancy Check, CRC) 也称为 多项式编码 (polynomial code),其基本思想是:将位串看作系数为 $0$ 或 $1$ 的多项式。
一个 $k$ 位的二进制串可以视为一个 $k-1$ 阶多项式的系数列表,该多项式有 $k$ 项,从 $x^{k-1}$ 到 $x^0$。对于一个 $k$ 位的二进制串,其最高 (最左边) 位对应的是 $x^{k-1}$ 项的系数,接下来的位对应的是 $x^{k-2}$ 项的系数,以此类推。
例如,对于一个 $6$ 位的二进制串 $110001$,其代表了一个 $5$ 阶多项式,其各项系数从左至右依次为:$1,1,0,0,0,1$,即 $1x^5+1x^4+0x^3+0x^2+0x^1+1x^0$。
多项式的算术运算遵守代数域理论规则,以 $2$ 为模来完成。加法没有进位,减法没有借位,加法和减法都等同于 异或 (XOR)。例如:
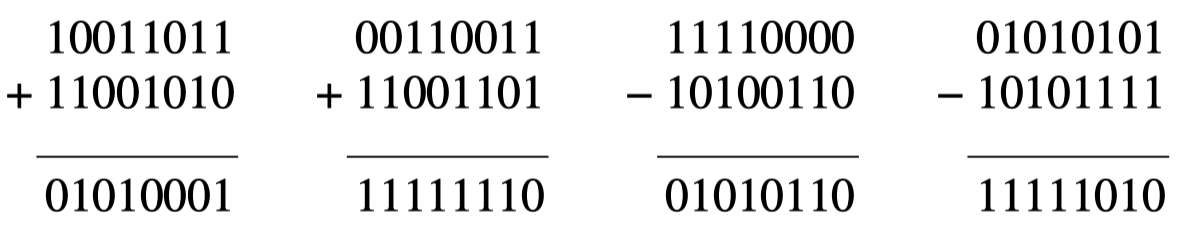
长除法与二进制中的除法运算一样,只不过减法按照模 2 进行。如果被除数与除数有一样多的位,则该除数要 “进入到” 被除数中,即两者位数相同则商为 $1$,否则为 $0$。
使用 CRC 时,消息发送方和接收方必须先商定一个 生成多项式 (generator polynomial) $G(x)$,其最高位和最低位系数必须为 $1$。假定一个二进制消息串有 $m$ 位,对应于多项式 $M(x)$,为了计算它的 CRC,$M(x)$ 的长度必须大于 $G(x)$。基本思想是在原二进制消息串的尾部附加一个校验和,使得新的二进制串能够被 $G(x)$ 除尽。当接收方收到了带校验和的消息串后,将尝试用 $G(x)$ 去除它。如果有余数,则说明消息传输过程中发生了错误。
CRC 计算过程如下:
- 假设 $G(x)$ 的阶数为 $r$。在消息串低位端添加 $r$ 个 $0$,新的消息串为 $m+r$ 位,对应多项式 $x^r M(x)$。
- 利用模 2 除法,用 $G(x)$ 对应的位串去除 $x^r M(x)$ 对应的位串。
- 利用模 2 减法 (即 XOR),从 $x^r M(x)$ 对应位串中减去余数 (总是小于等于 $r$ 位),其结果即为带校验和的消息串,其对应的多项式记为 $T(x)$。
下面是采用生成多项式 $G(x)=x^4+x+1$ 计算消息串 $1101011111$ 校验和的例子:

验证 CRC 的有效性:再次执行上述计算,可以很容易地验证收到消息的有效性,只不过这次在原消息尾部添加的是上面计算出的校验和而非之前的 $r$ 个 $0$ (当然,余数不足 $r$ 位则在前面补上对应数量的 $0$)。如果没有可检测的错误,则余数应等于 $0$。
通信或磁盘上的大多数错误都是连续发生的,其本质上是突发性的。带 $r$ 个校验位的多项式编码可以检测到所有长度小于或等于 $r$ 的突发错误。
例如,给定生成多项式 $G(x)=x^{32}+x^{23}+x^7+1$,它可以检测所有长度小于或等于 $32$ 位的突发错误;在长度为 $33$ 的 $100$ 亿个突发错误中,有 $5$ 个不会被检测到;在长度为 $34$ 或更大的 $100$ 亿个突发错误中,有 3 个不会被检测到。当然,如果需要检测更多位的错误,可以使用更高阶的生成多项式,代价就是计算量会增加。
1.4 其他相关术语
操作类型:
- 无保护操作 (Unprotected actions):没有 ACID 属性
- 受保护操作 (Protected actions):这些操作在完成之前 不会被外部化。这些操作受到控制,并且可以根据需要回滚。它们具有 ACID 属性。
- 真实操作 (Real actions):这些是真实的物理操作,一旦执行就无法撤消。在许多情况下,真实操作无法实现原子性 (例如:将发射两枚火箭作为单个原子操作)。
2. 事务类型
2.1 C 语言中的嵌入式 SQL 示例 (开放数据库连接)
现在,我们将通过一个简单例子来理解不同类型的事务。下面是一个在 C 语言中嵌入 SQL 的例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
int main(){
exec sql INCLUDE SQLCA; /*SQL Communication Area*/
exec sql BEGIN DECLARE SECTION;
/* The following variables are used for communicating between SQL and C */
int OrderID; /* Employee ID (from user) */
int CustID; /* Retrieved customer ID */
char SalesPerson[10] /* Retrieved salesperson name */
char Status[6] /* Retrieved order status */
exec sql END DECLARE SECTION;
/* Set up error processing */
exec sql WHENEVER SQLERROR GOTO query_error;
exec sql WHENEVER NOT FOUND GOTO bad_number;
/* Prompt the user for order number */
printf ("Enter order number: ");
scanf_s("%d", &OrderID);
/* Execute the SQL query */
exec sql SELECT CustID, SalesPerson, Status
FROM Orders
WHERE OrderID = :OrderID // ”:” indicates to refer to C variable
INTO :CustID, :SalesPerson, :Status;
/* Display the results */
printf ("Customer number: %d\n", CustID);
printf ("Salesperson: %s\n", SalesPerson);
printf ("Status: %s\n", Status);
exit();
query_error:
printf ("SQL error: %ld\n", sqlca->sqlcode); exit();
bad_number:
printf ("Invalid order number.\n"); exit();}
2.2 相关概念
-
主机变量
在
BEGIN DECLARE SECTION和END DECLARE SECTION之间所包含的部分中所声明的变量被称为 主机变量 (Host Variables)。访问这些变量时,它们以冒号:作为前缀。冒号对于区分主机变量和数据库对象 (例如表和列) 至关重要。 -
数据类型
DBMS 支持的数据类型和主机语言可以完全不同。主机变量具有以下两个作用:
- 主机变量是程序变量,通过主机语言的语句进行声明和操作
- 在嵌入式 SQL 中使用它们来检索数据库数据
如果没有与 DBMS 数据类型相对应的主机语言类型,则 DBMS 会自动转换数据。但是,由于每种 DBMS 在转换过程中都有其自己的规则和偏好,因此必须谨慎选择主机变量类型。
-
错误处理
DBMS 使用语句
INCLUDE SQLCA,通过一个 SQL 通信区 (SQL Communications Area, SQLCA) 向应用程序报告运行时错误。而WHENEVER...GOTO语句则告诉预处理器为程序生成错误处理代码,以处理 DBMS 所返回的错误。 -
单例 SELECT
用于返回数据的语句是一个 单例 (singleton) SELECT 语句;也就是说,它仅返回一行数据。因此,上面的代码示例中并没有声明或使用 游标 (cursors)。
接下来,我们将看一下两种不同的事务类型:扁平事务 (Flat Transaction) 和 嵌套事务 (Nested Transaction)。
2.3 扁平事务
扁平事务的思想很简单:BEGIN WORK 和 COMMIT WORK 内部的所有内容都处于同一级别; 也就是说,该交易将与其他所有事务一起保留 (提交),或者与其他所有事务一起回滚 (中止)。
下面是一个银行转账的例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
exec sql CREATE Table accounts(
AccId NUMERIC(9),
BranchId NUMERIC(9),
FOREIGN KEY REFERENCES branches,
AccBalance NUMERIC(10),
PRIMARY KEY(AccId));
exec sql BEGIN DECLARE SECTION;
long AccId, BranchId, TellerId, delta, AccBalance;
exec sql END DELCLARATION;
/* Debit/Credit Transaction*/
DCApplication(){
read input msg;
exec sql BEGIN WORK;
AccBalance = DodebitCredit(BranchId, TellerId, AccId, delta);
send output msg;
exec sql COMMIT WORK;
}
/* Withdraw money -- bank debits; Deposit money – bank credits */
Long DoDebitCredit(long BranchId, long TellerId, long AccId, long AccBalance, long delta){
exec sql UPDATE accounts
SET AccBalance = AccBalance + :delta
WHERE AccId = :AccId;
exec sql SELECT AccBalance INTO :AccBalance
FROM accounts WHERE AccId = :AccId;
exec sql UPDATE tellers
SET TellerBalance = TellerBalance + :delta
WHERE TellerId = :TellerId;
exec sql UPDATE branches
SET BranchBalance = BranchBalance + :delta
WHERE BranchId = :BranchId;
exec sql INSERT INTO history(TellerId, BranchId, AccId, delta, time)
VALUES( :TellerId, :BranchId, :AccId, :delta, CURRENT);
return(AccBalance);
}
让我们检查一下帐户余额,并拒绝任何透支帐户的借记。
1
2
3
4
5
6
7
8
9
10
11
12
DCApplication(){
read input msg;
exec sql BEGIN WORK;
AccBalance = DodebitCredit(BranchId, TellerId, AccId, delta);
if (AccBalance < 0 && delta < 0){
exec sql ROLLBACK WORK;
}
else{
send output msg;
exec sql COMMIT WORK;
}
}
2.4 扁平事务的局限性
尽管扁平事务非常简单,但是它无法对很多实际应用场景建模。
例如,机票预订:
1
2
3
4
5
BEGIN WORK
S1: book flight from Melbourne to Singapore
S2: book flight from Singapore to London
S3: book flight from London to Dublin
END WORK
问题:如果我们无法从都柏林到达最终目的地,我们希望从新加坡飞往巴黎,然后到达我们的最终目的地。
如果选择回滚,那么我们需要重新预订从墨尔本到新加坡的预订,这将造成 时间和资源的浪费。
又例如,雇员加薪:
1
2
3
4
5
6
7
8
9
10
IncreaseSalary(){
real percentRaise;
receive(percentRaise);
exec SQL BEGIN WORK;
exec SQL UPDATE employee
set salary = salary*(1+ :percentRaise)
send(done);
exec sql COMMIT WORK;
return
}
这可能是一个非常长时间的事务,任何事务失败都需要大量不必要的计算。
2.5 带保存点的扁平事务
前面提到,对于一个很长的语句列表,其执行过程中耗时会更长,同时也更容易发生错误,而任何错误都将导致回滚所有操作,这将耗费大量时间。
一种策略是采用 带保存点 (save points) 的扁平事务:
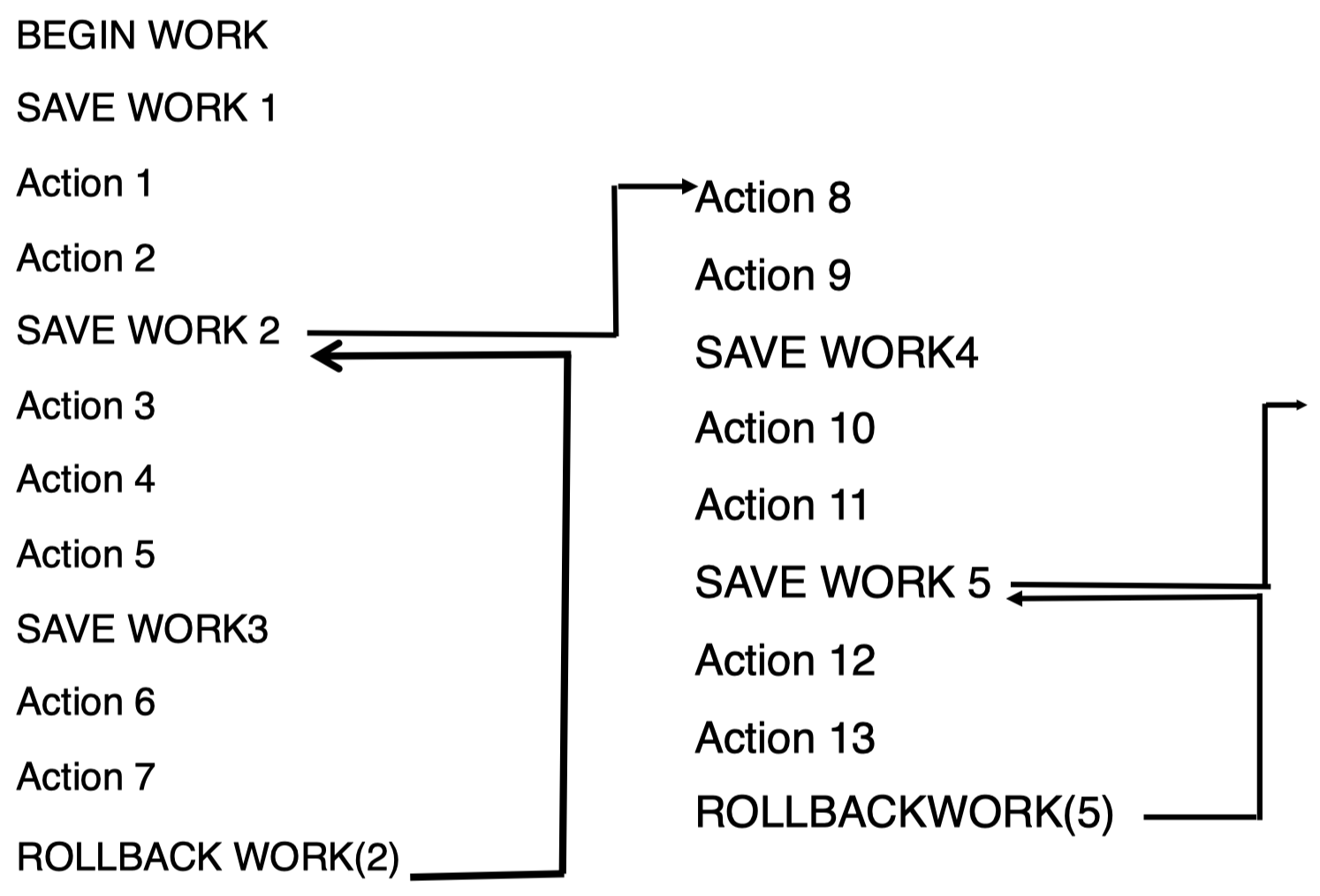
通过在待执行语句中插入一些保存点,它们可以保留之前已经完成的操作。一旦发生错误,我们可以选择直接回滚到之前的某个保存点状态,而不必完全从头开始。例如,在执行操作 7 后,我们希望回滚到保存点 2,这种情况下,操作 3-7 会被丢弃,系统将从保存点 2 的状态开始 (即已经执行过操作 1 和 2),直接执行操作 8。
例如,假如我们需要为一次长途旅行预订机票:
- 伦敦 $\to$ 纽约 $\qquad$ 纽约 $\to$ 芝加哥 $\qquad$ 芝加哥 $\to$ 得梅因
- 我们可能希望分别在 伦敦 $\to$ 纽约 和 纽约 $\to$ 芝加哥 的预订代码之后插入保存点。
- 如果我们订不到 芝加哥 $\to$ 得梅因 的机票,我们可以回滚到 伦敦 $\to$ 纽约 之后的保存点,然后可能尝试预订从 圣路易斯 中转的机票。
另外,一种类似策略是采用 链式 (chained) 事务:当错误发生时,所有已经执行的操作将被保存,然后在此状态上,继续执行下一次操作。
2.6 嵌套事务
现在,我们来看另一种事务类型:嵌套事务。
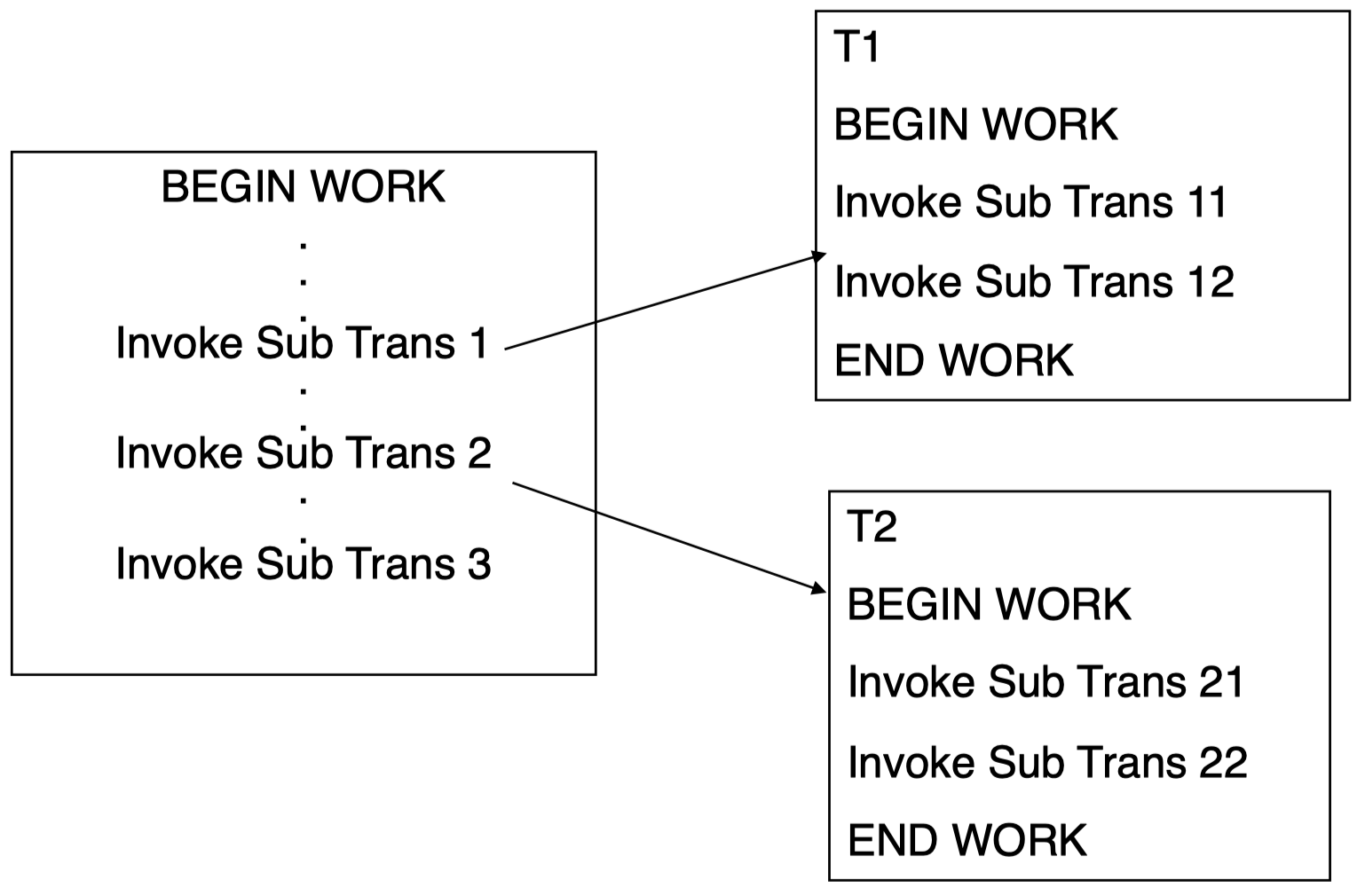
对于嵌套事务,我们可以从逻辑上将一个事务的操作集合划分为不同的子事务。在父事务内部,我们按照所需顺序依次调用所有子事务。在子事务内部,我们用 BEGIN WORK 和 END WORK 包裹所有需要执行的操作或者下一层子事务。
2.7 嵌套事务规则
- 提交规则
- 子事务可以提交或者中止,但是,除非其所属的父级也提交,否则其本身无法进行提交。
- 子事务具有 A (原子性),C (一致性) 和 I (隔离性) 属性,但没有 D (持久性) 属性,除非其所有祖先都进行提交 (因为嵌套事务可以包含很多层)。
- 子事务的提交使得其结果仅可用于其父级。
- 回滚规则
- 如果子事务回滚,则其所有子级将被强制回滚。
- 可见性规则
- 子事务所做的更改只有在对其进行提交时才对父级可见。而父级的所有对象对其子级都是可见的。这意味着 父级不应当在子级访问其对象时对它们进行修改。通常不会发生这种问题,因为父级不会与其子级并行运行。
另外一种类似策略是 开放嵌套事务,其区别在于子事务可以独立提交而无需依赖父级。
3. 事务处理
3.1 事务处理监视器 (TP monitor)
TP 监视器 的主要功能是 集成 其他系统组件并管理资源。下面是一个 TP 监视器的一般架构:
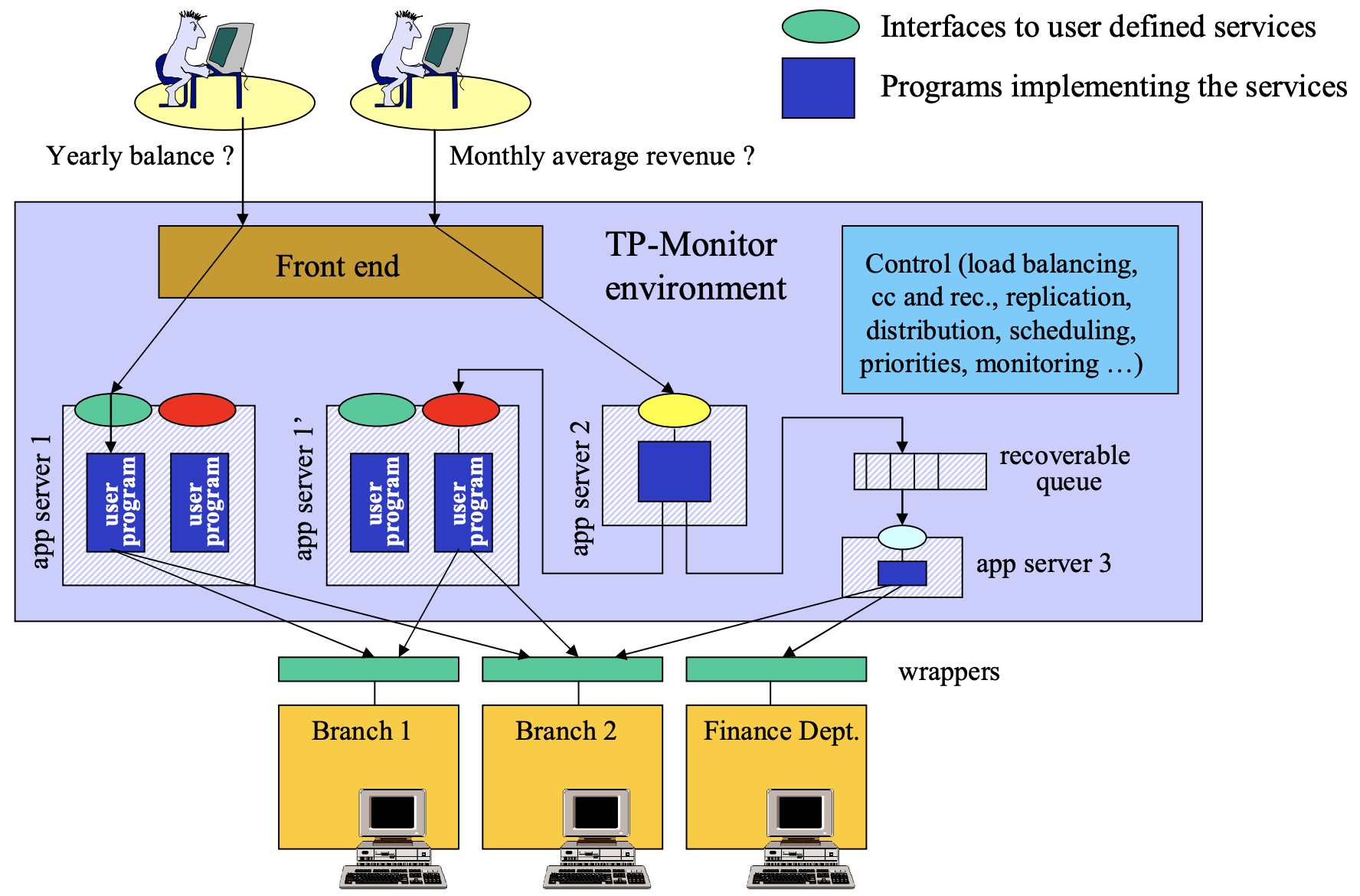
例如,在一个银行系统中,后端系统包含两个分支 (Branch 1 和 Branch 2) 和一个财务部门 (Finance Dept.)。然后,用户向该系统请求数据,但用户并不知道后端数据是如何管理的,而 TP 监视器将采取一些措施确保用户和后端之间实现顺利交互。首先,所有来自用户的请求将通过一个队列来维持,并且 TP 监视器将根据系统负载情况决定这些请求的优先级。无论这些信息处理器 (分支或者财务子系统) 检索的是什么信息,它们同样需要传递给客户端,所以 TP 监视器还需要提供用户定义服务的接口。TP 监视器的另一个重要功能是:对所有的用户请求以某种方式进行分解或者组合,使这些事务的 ACID 性质得以维持。例如,假如某个客户希望存入一笔存款,然后所有相关的必要信息 (例如账户、余额等) 的更新都必须是一个原子操作,而 TP 监视器将保证这一点。
3.2 计算方式
TP 监视器维持来自用户的请求,以及用户和服务器之间的通信或者接口。工作请求会影响到资源和队列的管理,其中可能包含许多工作单元,它们对于如何分配资源具有非常大的影响。
下面是一些常见的工作请求的计算方式:
- 批处理 (Batch Processing)
- 包含许多工作单元
- 粗粒度 (Coarse grained) 资源分配
- 顺序访问模式
- 较少的并发工作
- 隔离执行
- 应用程序本身负责恢复
- 例如:通过频繁的程序检查指向;运行某些系统工具以恢复丢失的数据等。
这是长时间运行的应用程序经常使用的模型。
- 分时 (Time-sharing)
- 每个终端一个进程
- 粗粒度资源分配
- 不可预测的资源请求
- 顺序执行
- 数百个并发用户
- 应用程序/用户负责恢复
- 例如:频繁检查点,运行系统工具以恢复丢失信息,要求操作员恢复丢失的文件。
- 实时处理 (Real-Time processing)
- 事件驱动的操作
- 重复的工作负载
- 例如:监视真实设备并响应异常等。
- 设备与任务的动态绑定
- 例如:每个任务可能直接负责监视或控制设备,并将信息传输到需要该信息的那些任务。
- 隔离执行
- 高可用性,但不一定具有形式上的一致性
- 高性能:系统应提供出色的响应时间,这可能涉及保证截止日期的安排
-
客户端-服务器处理 (Client-Server processing)
这与分时非常相似,唯一区别在于服务是通过向服务器进程发送消息来处理的。基于分时系统实现的客户端-服务器模型能够增加可支持的并发用户数量。
- 面向事务处理 (Transaction-oriented processing)
- 不同计算之间共享数据
- 可变请求
- 重复的工作负载
- 通常是简单计算 (短事务)
- 可能支持批事务
- 大量并发用户 (OLTP,在线交易处理)
- 智能客户程序
- 高可用性
- 基于系统的自动恢复
- 自动负载均衡
下面是关于这几种计算方式的总结:
| 批处理 | 分时 | 实时处理 | 客户端-服务器 | 面向事务处理 | |
|---|---|---|---|---|---|
| 数据 | 私有 | 私有 | 私有 | 共享 | 共享 |
| 处理时间 | 长 | 长 | 很短 | 长 | 短 |
| 可靠性保证 | 一般 | 一般 | 很高 | 一般 | 很高 |
| 一致性保证 | 无 | 无 | 无 | 无 (?) | ACID |
| 工作模式 | 规则 | 规则 | 随机 | 随机 | 随机 |
| 工作源数量/目的 | $10^1$ | $10^2$ | $10^3$ | $10^2$ | $10^5$ |
| 提供的服务 | 虚拟处理器 | 虚拟处理器 | 简单功能 | 简单请求 | 简单或复杂功能 |
| 性能指标 | 吞吐量 | 响应时间 | 响应时间 | 吞吐量和响应时间 | 吞吐量和响应时间 |
| 可用性 | 一般 | 一般 | 高 | 高 | 高 |
| 授权单位 | 作业 | 用户 | 无 (?) | 请求 | 请求 |
3.3 事务处理服务 (TP services)
-
异构性 (Heterogeneity)
如果应用程序需要访问其他数据库系统,则单个数据库系统的本地 ACID 属性是不够的。本地 TP 监视器需要与其他 TP 监视器进行交互,以确保总体 ACID 属性。为此,必须采用一种两阶段提交协议 (稍后将对此进行讨论)。
-
控制通信 (Control communication)
如果应用程序与其他远程进程进行通信,则本地 TP 监视器应维持进程之间的通信状态,以使其能够从崩溃中恢复 (这一点在前面已经讨论过了)。
-
终端管理 (Terminal management)
由于许多终端都运行客户端软件,因此 TP 监视器应在客户端和服务器进程之间提供适当的 ACID 属性。
-
演示服务 (Presentation service)
从某种意义上说,它类似于终端管理,必须处理不同的演示 (用户界面) 软件,例如:X 视窗。
-
上下文管理 (Context management)
例如维持会议等。
-
启动/重新启动 (Start/Restart)
在基于 TP 的系统中,启动和重启动之间没有区别。
3.4 TP 进程结构
相关术语
- 一个 终端 (客户端) 希望由应用服务器执行某些功能,而应用服务器又需要数据库中的一些数据。
- 对于每个终端,必须通过一个 进程 来最终得到输入、了解功能请求并确保功能得以执行 (或执行功能本身)。
- 一个进程可以处理多个终端请求,或者也可以每个终端都有一个进程。
每个终端都有一个进程来处理所有可能的请求:
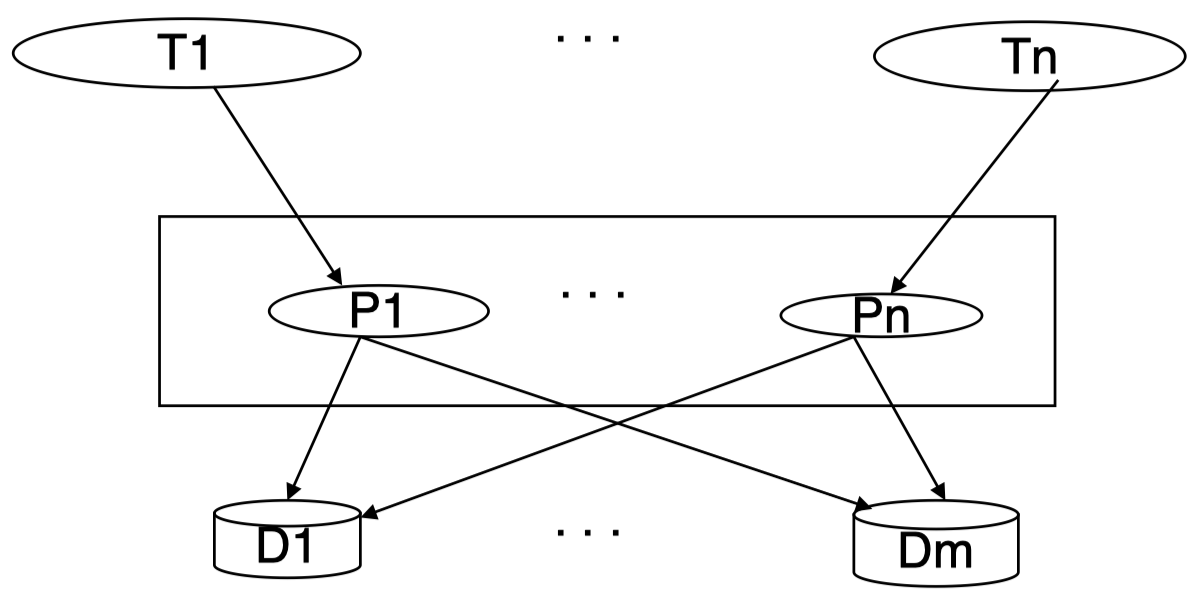
如果我们有 $20000$ 个终端,$1000$ 个文件 (关系),并且每个进程大约需要 $50$ 个数据块,那么计算成本将非常高:$20000 \times 1000 \times 50 = 10^9$ 个数据块。
所有终端共用一个进程来处理所有可能的请求:
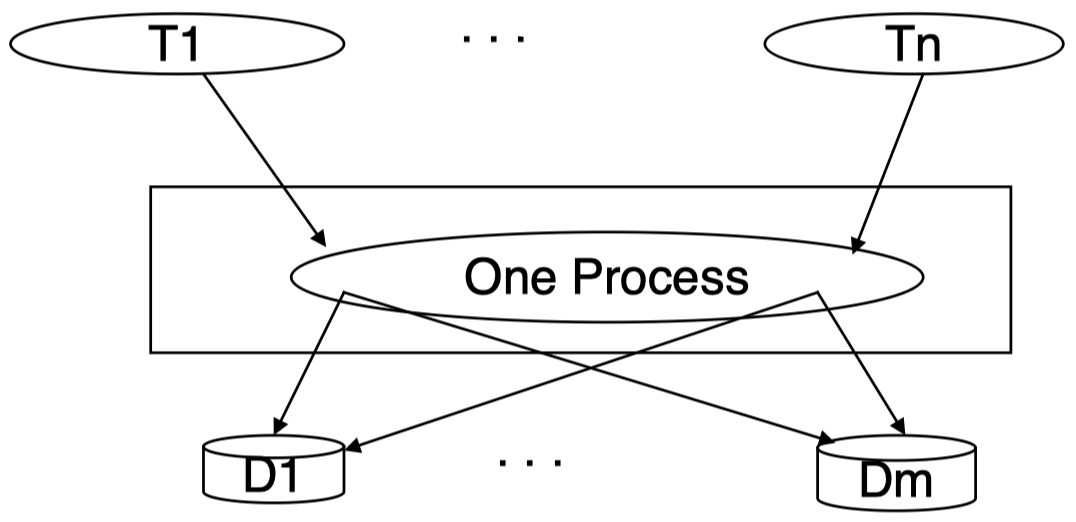
对于某些情况,这种模型可能会出现问题:由于调度而产生的上下文切换可能导致较差的响应;必须处理所有各种终端的大型程序。
多通信进程和服务器:
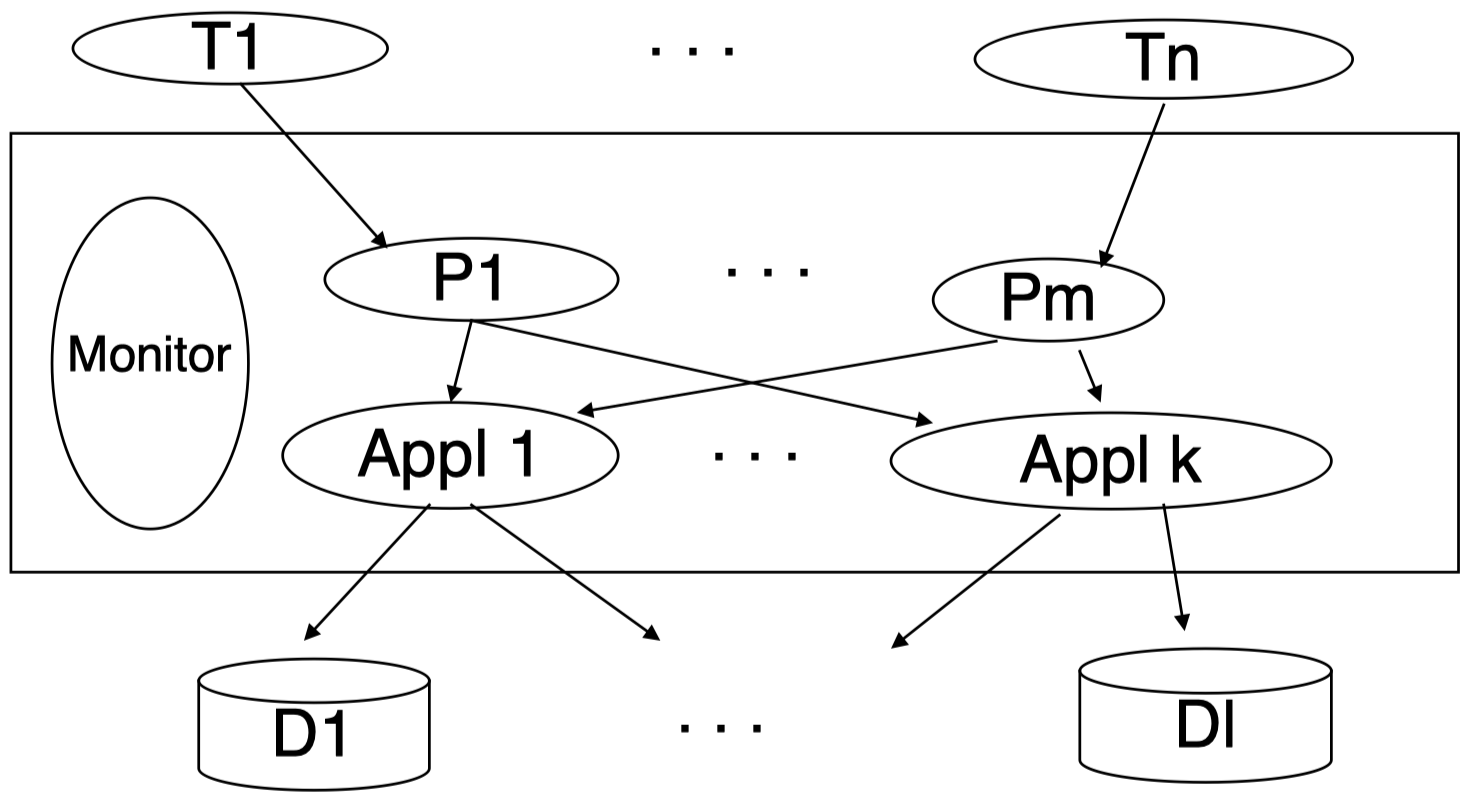
这是一种通用的结构策略,该结构包含很多进程,每个进程可以处理多个终端请求,因此,进程必须是可扩展的 (即单个进程必须能够处理可变数量的终端请求)。可以看到,图中一共有 $n$ 个终端,但是进程数量为 $m$ 个。进程可以和应用进行通信,以保证功能请求得以执行。而应用将从数据库中访问相应数据。
下节内容:并发控制
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。 欢迎转载,并请注明来自:YEY 的博客 同时保持文章内容的完整和以上声明信息!