Module 01 信任、机器和数字伦理
1. 为什么信任机器?
信任的目标
人际信任 (interpersonal trust,即两个人类之间的信任) 的社会学视角:
- 通过获得对某人的信任,我们可以使生活更加 可预测 (predictable),从而可以实现人与人之间的协作。
人类-机器 (human-machine) 的视角:
- 通过获得对机器的信任,我们可以更轻松地预测机器的决策(可预测性),从而实现人机协作。
最终目标不是信任本身。信任是一种有助于实现可预测性和协作的机制。
2. 什么是信任?
2.1 信任:社会学的视角
人类 A 信任 (trusts) 人类 B,如果:
- A 相信 B 将为 A 的 最大利益 (best interests) 行事;
- A 接受 B 行动的 脆弱性 (vulnerability);
使得 A 可以:
- 预期 (anticipate) B 行动的 影响 (impact),
因此,可以使社交生活更具 可预测性 (predictable),从而实现 协作 (collaboration)。
2.2 人类-AI 信任


H(人类)信任 M(机器),如果:
- H 相信 M 将为 H 的最大利益而行动;(信念)
- H 接受 M 行动的脆弱性;(风险)
使得 H 可以:
- 预测 M 的决策对 H 的影响(目标)
因此,可以使交互过程更加可预测,从而实现协作。
2.3 不信任和缺乏信任
不信任(Distrust):
- H 相信 M 不会 为 H 的最大利益行事。
缺乏信任(Lack of trust):
- H 不相信 M 会 为 H 的最大利益而行动;或者
- H 不接受 M 行动的脆弱性。
注意:信任的存在与 H 是否可以预期 M 行动对 H 的影响无关。
3. 合同信任
3.1 合同信任:社会学视角
注意:合同可以是社会/规范性的,而不仅限于法律。
3.2 合同信任:人类-AI 信任视角
3.3 AI 中的合同
值得信任的 AI 模型标准:
- 我相信该模型可以保护我的隐私
- 我相信该模型在部署中表现良好
- 我相信该模型对于数据中的小噪声具有鲁棒性
3.4 重构人类-AI 信任
H(人类)信任 M(机器),如果:
- H 相信 M 将履行符合 H 最佳利益的 一组特定合同 (a particular set of contracts);
- H 接受 M 行动的脆弱性;
使得 H 可以:
- 预测 M 的决策对 H 的影响
因此,可以使交互更加可预测,从而实现协作。
4. 可信赖度与信任
4.1 可信赖的 AI
AI 模型/代理是 可信赖的 (trustworthy),如果:
- 它可以履行其一系列合同
注意,这与 信任 (trust) 无关:
- 信任并不意味着可信赖度
- 可信赖度并不意味着信任
4.2 正当信任与非正当信任
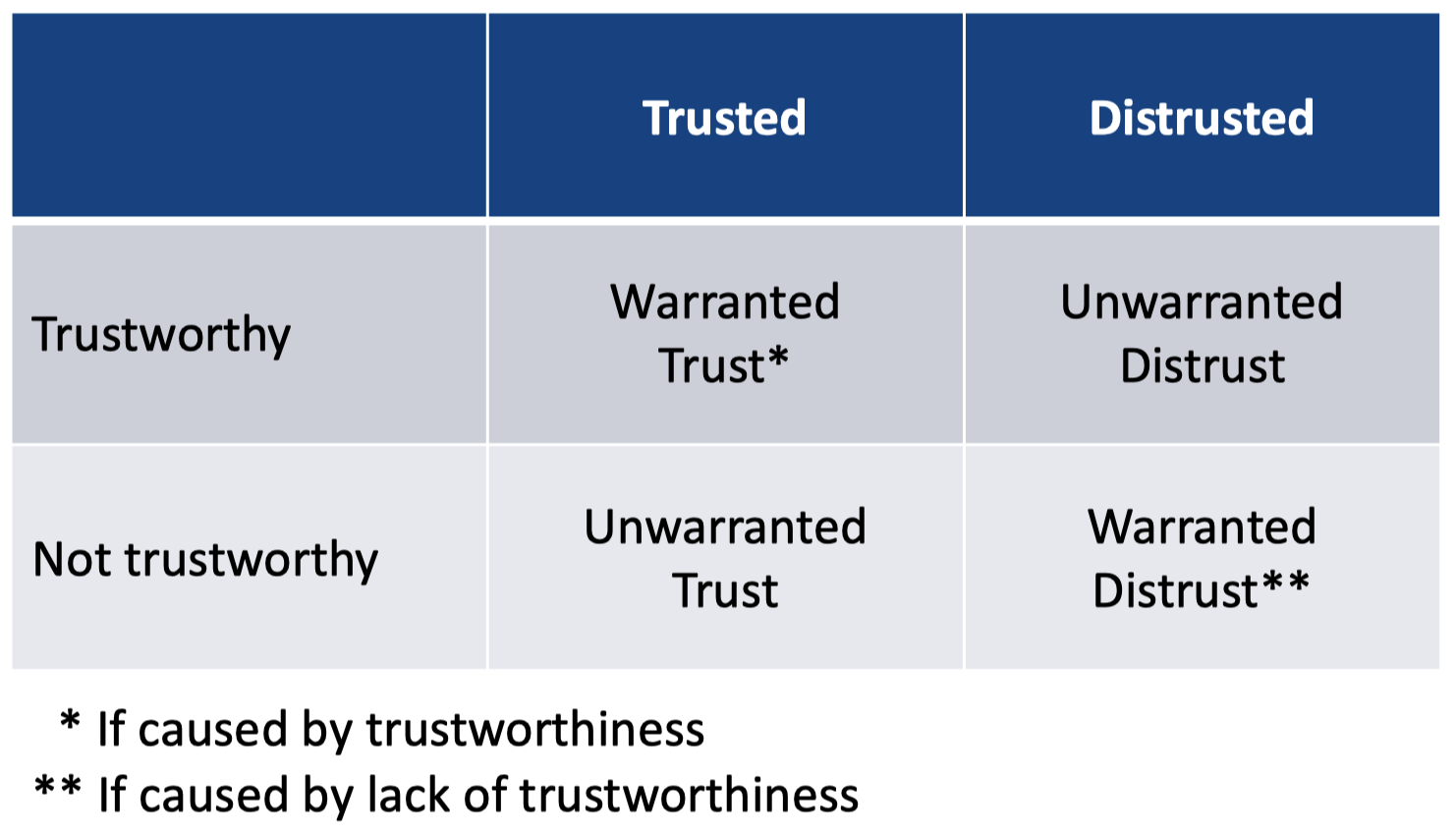
正当信任 (Warranted trust) = 信任是由 可信赖度 (trustworthiness) 引起的
非正当信任 (Unwarranted trust) = 信任是由其他原因引起的
4.3 非正当信任的例子
用户仅仅由于某系统拥有高质量的 UI 界面而相信该系统具有高性能:

注意:如果信任可以通过操纵可信赖度来改变,那么它就是正当的。
4.4 信任的理想结果
我们应该追求:
- 正当信任
- 正当不信任
我们应该避免:
- 非正当信任
- 非正当不信任
注意:非正当信任并不是由可信赖度引起的,因此我们不能依靠它来得到适当的预期。
5. 内部信任和外部信任
5.1 内部信任和外部信任
是什么 导致 了正当信任?
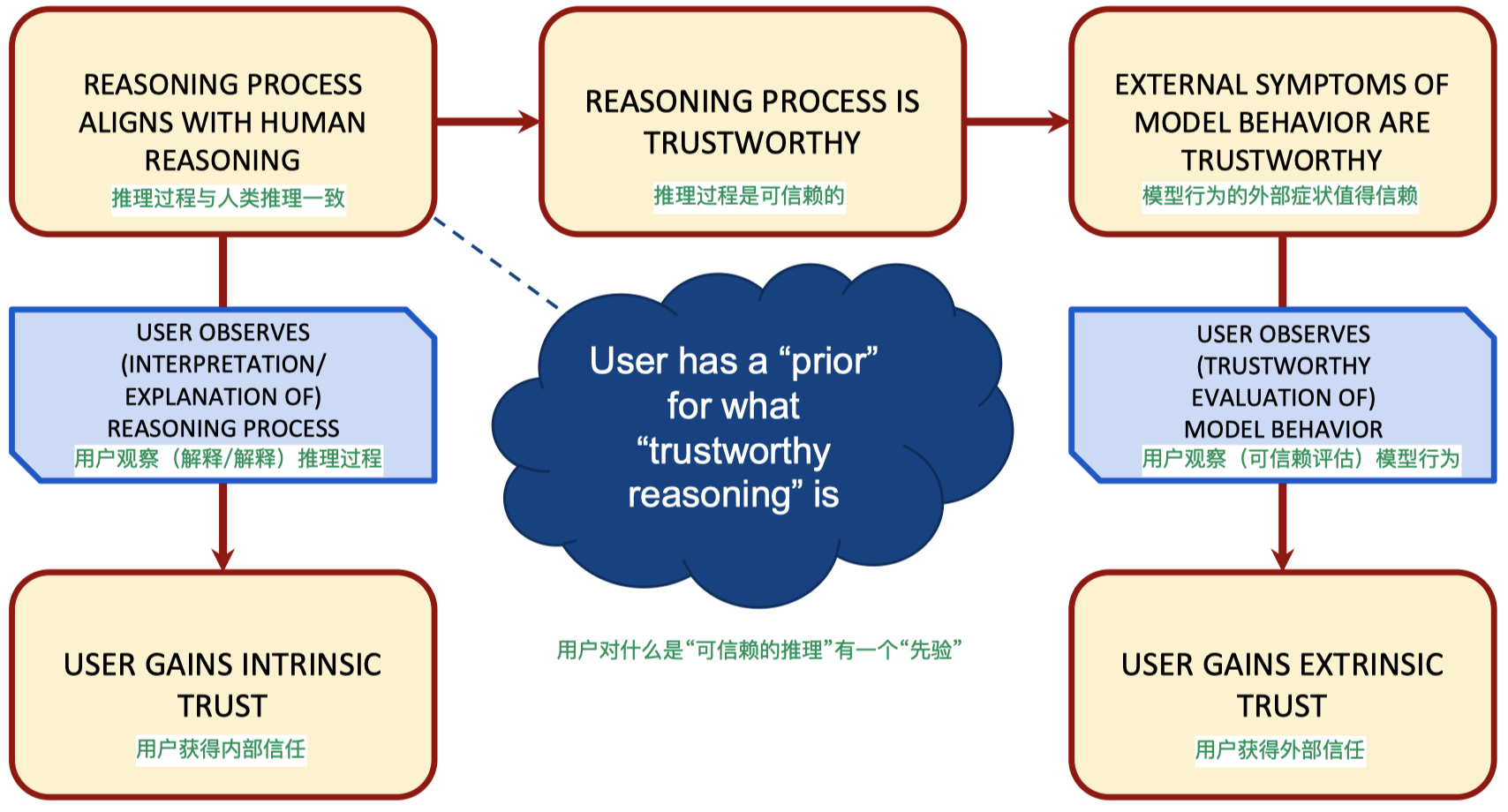
5.2 正当内部信任
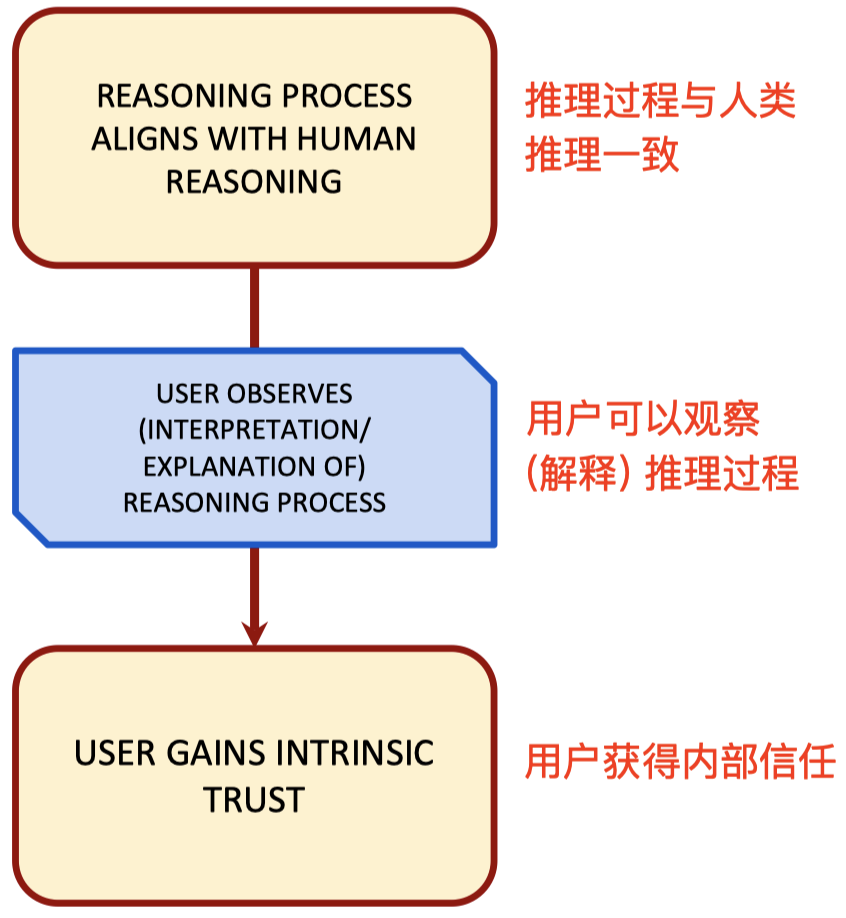
是什么 导致 了正当内部信任?
例子:
- 我们相信医学专家在解释导致其诊断的各种因素时会引用可敬的研究来证明他们的主张是正确的。
- 我们信任基于 AI 的信用评分模型,因为我们对每个决策的重要特征都有解释,并建议如何更改决策。
5.3 正当外部信任
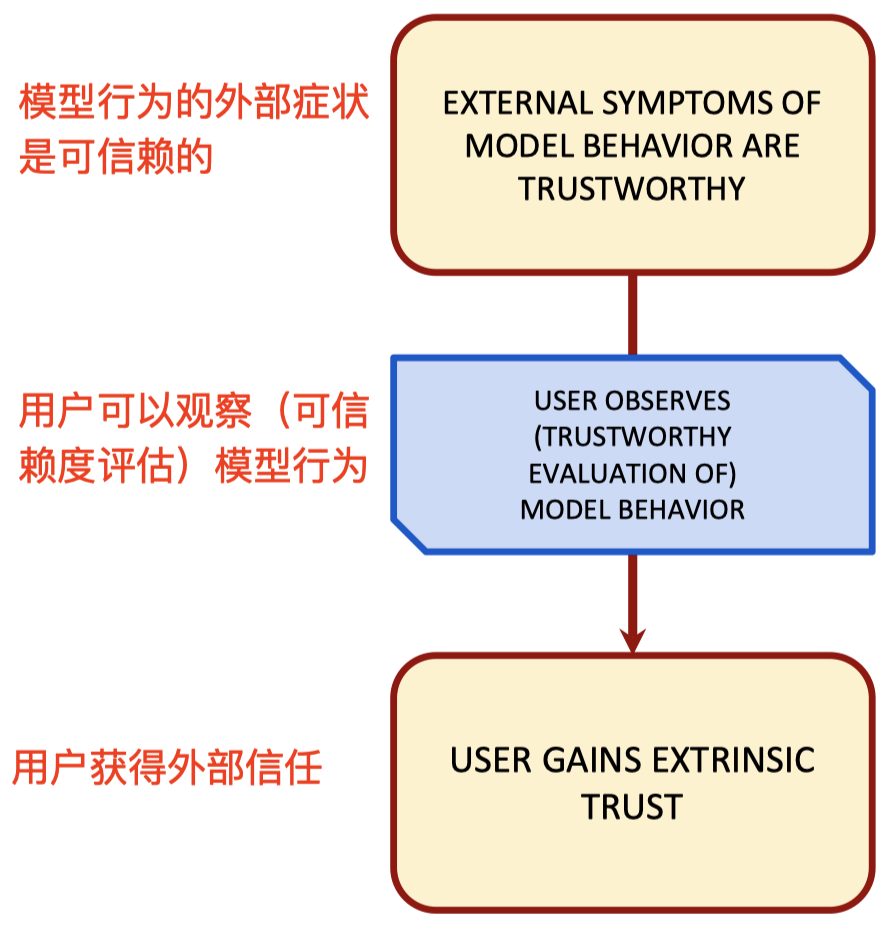
是什么 导致 了正当外部信任?
例子:
- 我们信任医学专家,因为他们已经通过了几项有关其能力的检查,并且具有为我们做出正确诊断的悠久历史。
- 我们信任基于 AI 的信用评分模型,因为我们已经看到了测试数据的结果,并且已经在部署中很好地工作了。
5.4 增加 AI 中的信任
增加内部信任:
- 可解释性 (Explainability)
- 简洁性 (Simplicity)
- 透明度 (Transparency)
- 解释 (Explanation)
增加外部信任:
- 通过代理 (By proxy):可信赖的专家判断 AI 模型
- 部署后数据 (Post-deployment data):在实际环境中部署后维护合同的示例
- 测试集 (Test sets):以特定方式分发的示例
6. 使用、误用、弃用、滥用:不正当的信任和不信任
6.1 决定自动化使用的因素
根据 Parasurman 和 Riley(1997)的研究,有三个主要因素决定某人是否会使用 AI /自动化:
- 精神工作量 (Mental workload)
- 认知开销 (Cognitive overhead)
- 信任 (Trust)
6.2 自动化的误用 (Misuse)
定义:在不应该使用自动化时使用自动化。 原因:非正当信任,由于:
- 对自动化的过度依赖(例如精神工作量大)
- 启发式决策中的决策偏见
- 人为监控错误(例如,不清楚的错误消息,高误报率)
- 机器监控错误
- 自动化偏差
影响:由自动化引起且未被人察觉的问题(例如自满)。
6.3 自动化的弃用 (Disuse)
定义:应该使用自动化时不使用自动化。
原因:非正当的不信任,由于:
- 人为监控错误(误报率低)
- 机器监控错误
- 人为偏见
影响:禁用/忽略警报,导致人为检测不到的问题。
6.4 自动化的滥用 (Abuse)
定义:在不应该使用自动化时进行部署(例如,设计时没有考虑到操作者的情况)。
原因:来自 设计者 的非正当信任,由于:
- 对人类操作员的不信任
- 自动化偏差
- 傲慢
影响:人机界面不匹配,操作员缺乏态势感知。
6.5 例子:Therac-25
Therac-25 是一台放射治疗机,由软件控制
结果:Therac-25 给六名患者带来了过量的辐射,导致其死亡。
原因:软件错误,来自:
- 误用:放射线师的不正当信任? 错误代码对操作员毫无意义:例如 “故障16”
- 弃用 (?):已从 Therac 早期版本中删除但未由软件代替的硬件互锁。
- 滥用:设计 Therac-25 的过程中,几乎没有放射线师的参与; 当烧伤和早期死亡被报道时,来自设计师的狂妄自大。
7. AI 中的信任和伦理
7.1 信任和伦理
7.2 用户信任

7.3 AI 中的伦理问题

7.4 信任、机器和伦理:总结
信任:
-
相信行事“符合我的利益”
接受风险
预测决策的影响
-
合同信任
-
正当和非正当的信任和不信任
-
信任的原因
-
内部信任(推理)
-
外部信任(行为)
-
关键要点:
-
明确哪些合同适用于您的模型/系统
- 信任只有在正当的情况下才是(道德上)可取的
- 不信任如果是正当的,那么它就是可取的
- 不正确校准的信任会导致现实问题
- 人工智能中的伦理问题源于人与人之间的利益不同,因此信任程度不同
8. 推荐阅读
- Formalizing Trust in Artificial Intelligence: Prerequisites, Causes and Goals of Human Trust in AI.
- Human and Automation: Use, Misuse, Disuse, Abuse.
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。 欢迎转载,并请注明来自:YEY 的博客 同时保持文章内容的完整和以上声明信息!