Module 08 可解释性
1. 动机:为什么要问为什么?
1.1 什么是可解释人工智能?
可解释性(Explainability,以及 interpretability)就是 理解(understanding)。
可解释人工智能(Explainable AI)是人们能够理解人工智能模型和决策的能力。
解释(Explanation)是一种帮助人们理解的机制。
1.2 为什么我们关心可解释性?
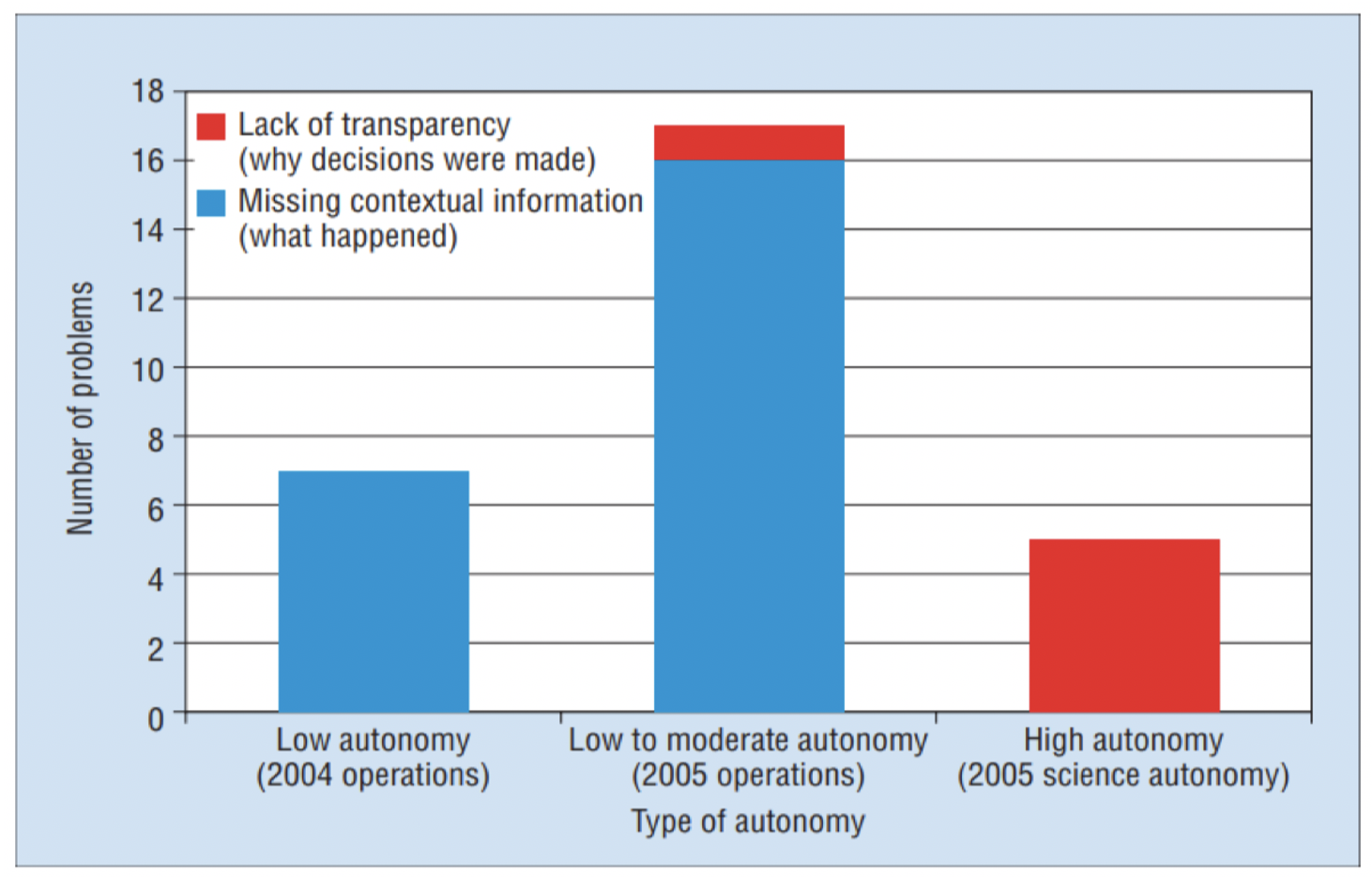
1.3 可解释人工智能的目标
为什么我们关心可解释性?
- 信任:合同中的正当信任和不信任
- 伦理:通过产生信任来提高应用程序的伦理适用性
如果某些人无法理解一个算法生成某种决策的原因,那么让他们对基于该算法辅助的决策负责是否合理?
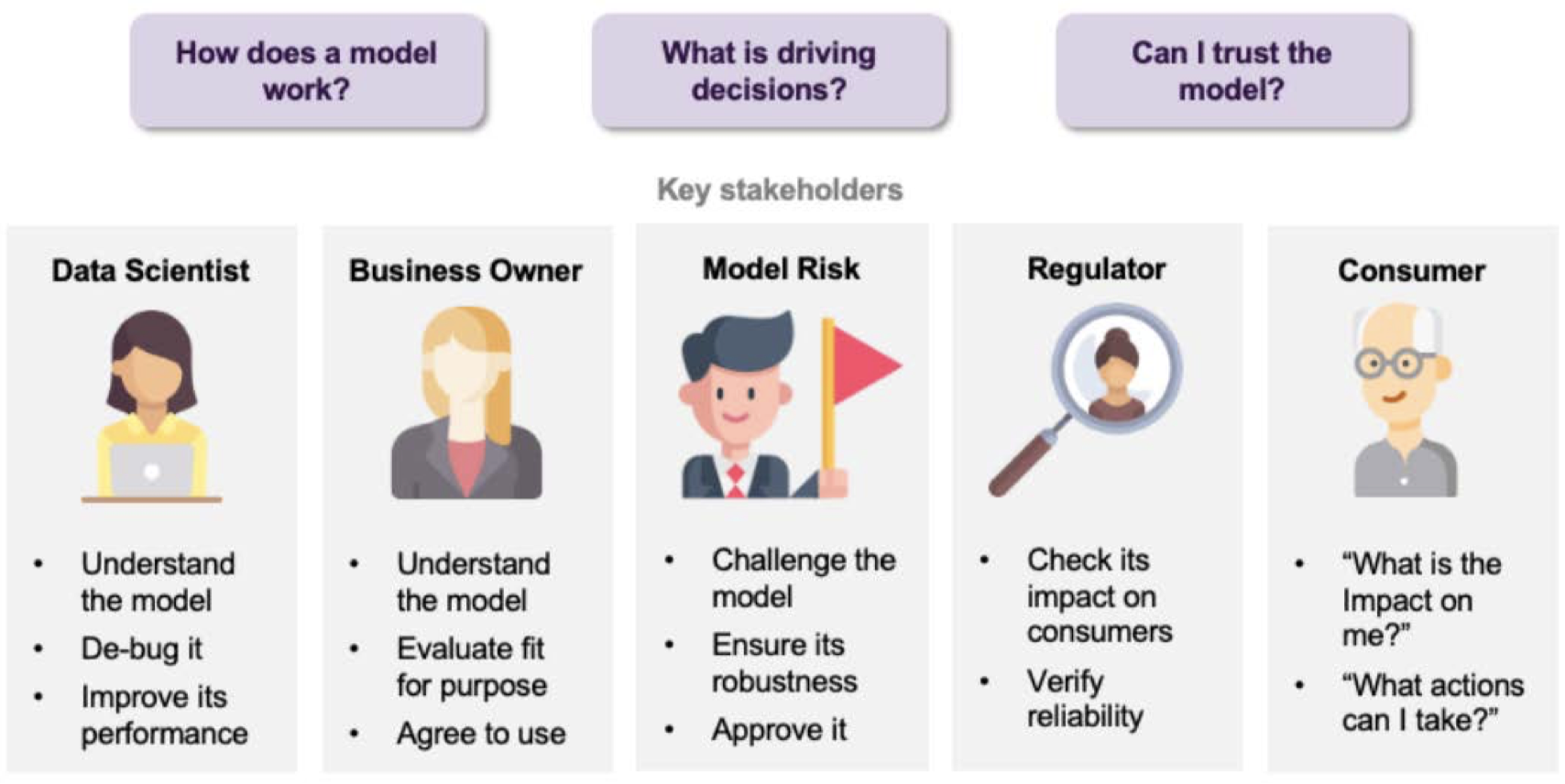
1.4 哪些人关心可解释性 AI?在什么阶段关注?
2. 可解释性 AI 的挑战
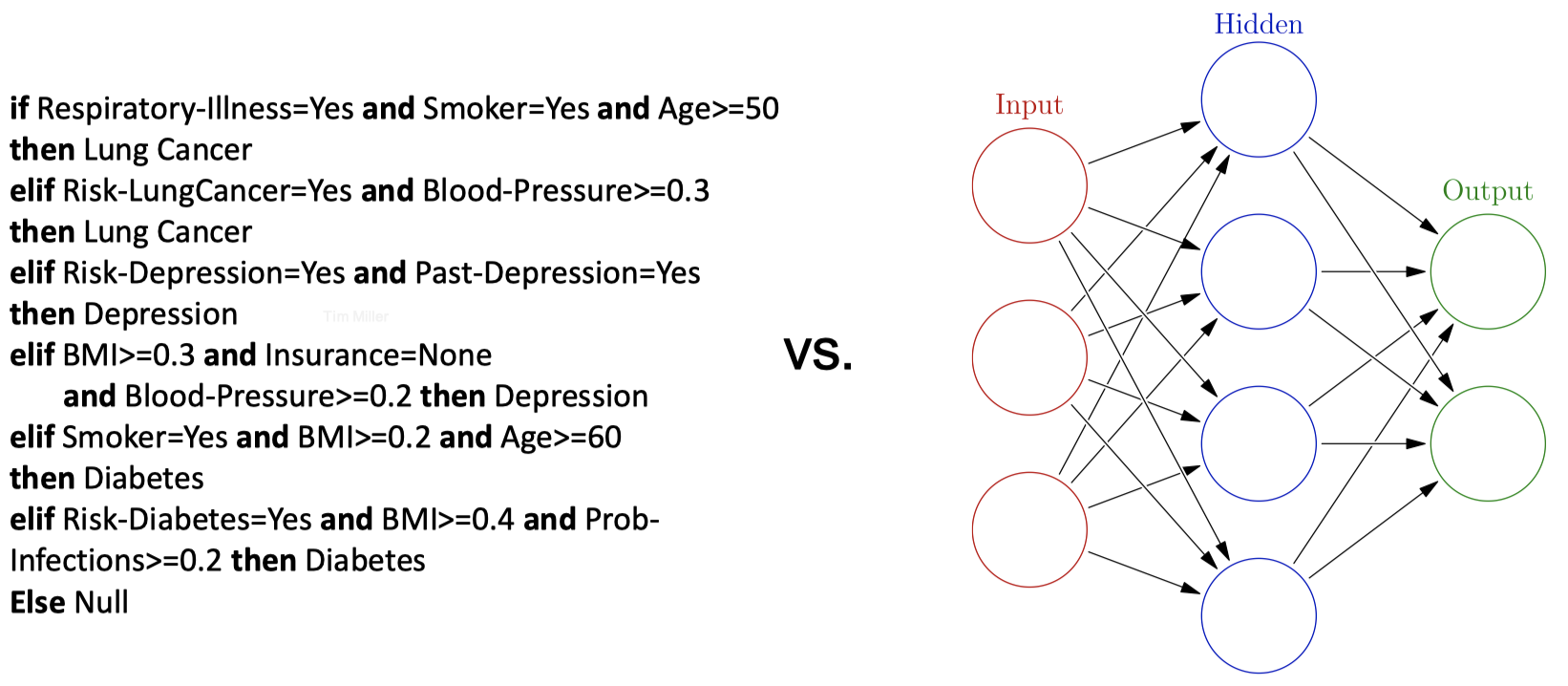
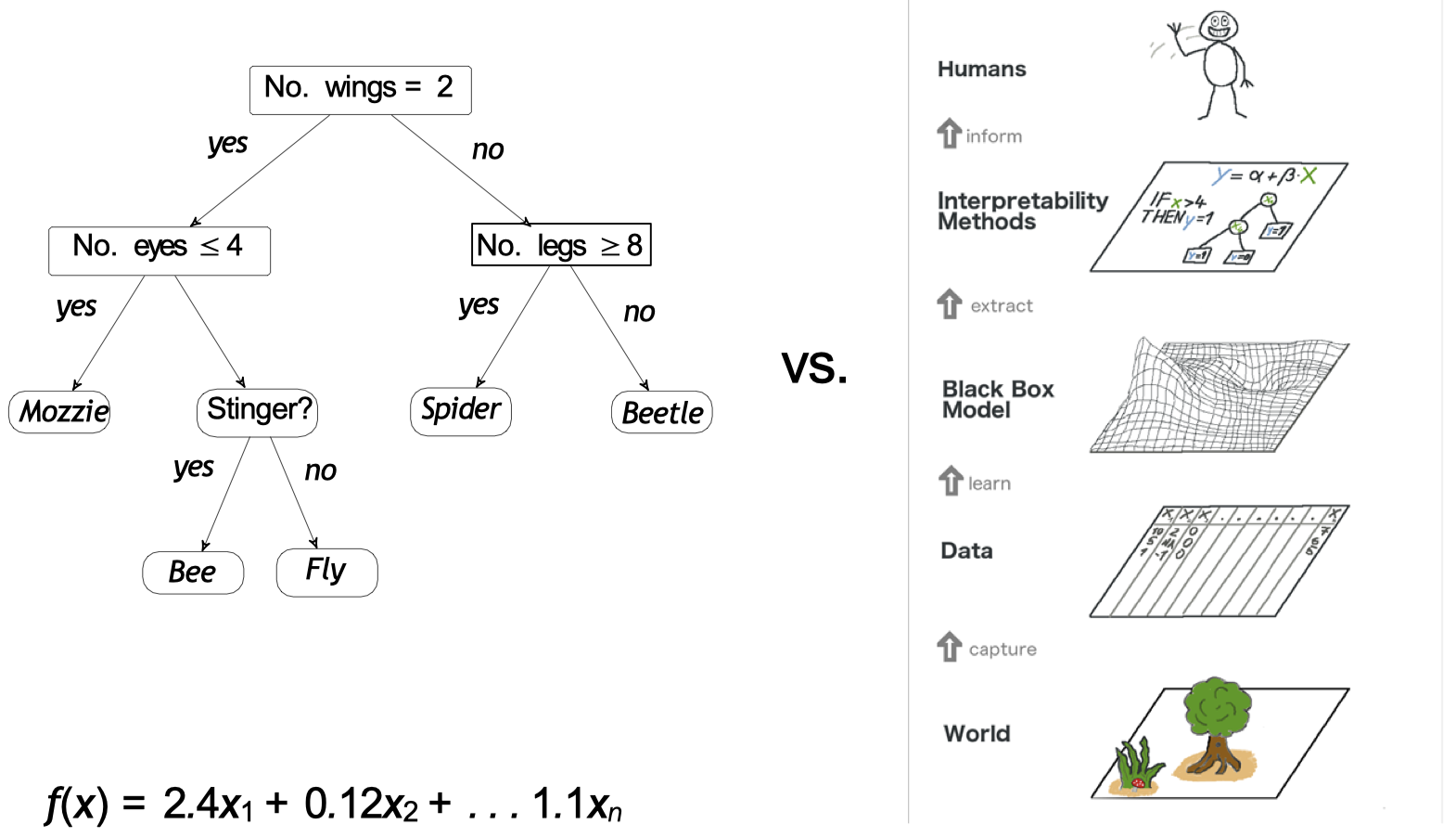
2.1 挑战:不透明度 (Opacity)
决策树 vs. 神经网络模型
2.2 挑战:因果关系(Casuality)

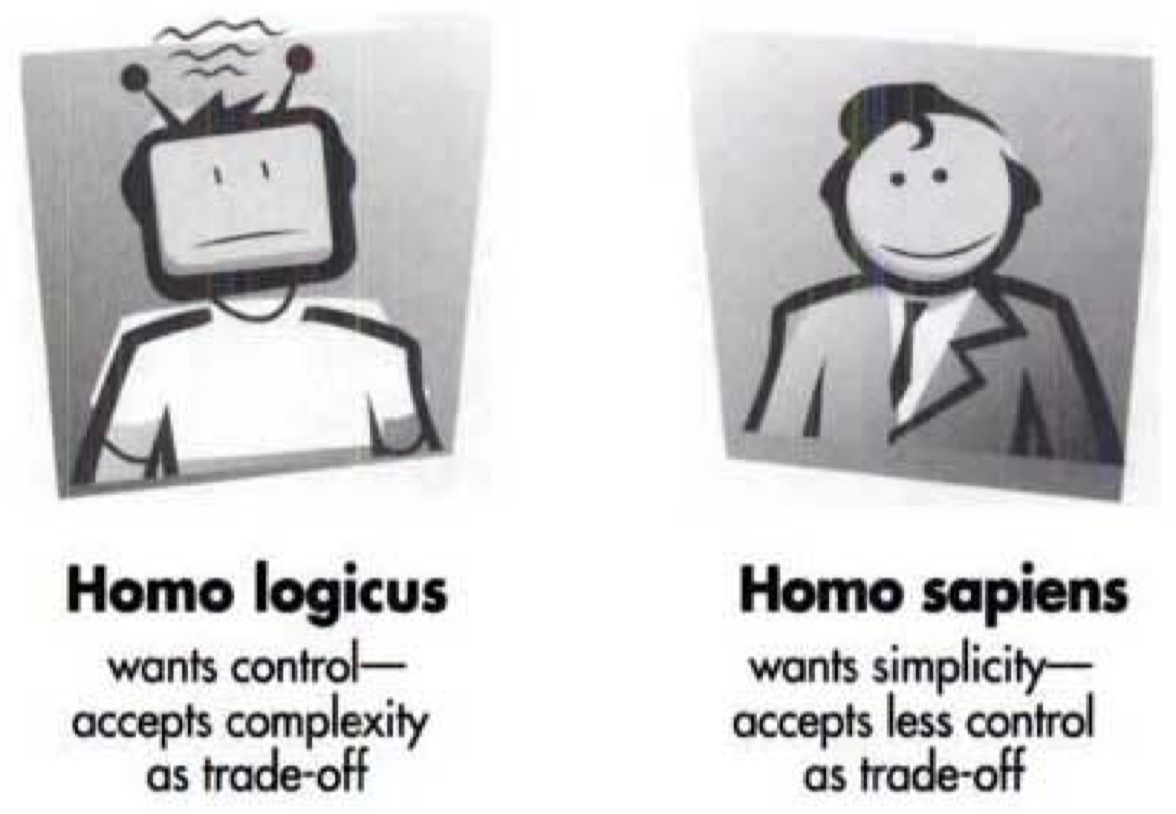
2.3 挑战:人的问题
3. 可解释 AI 方法的特性
3.1 全局 vs. 局部
3.2 固有(Intrinsic)vs. 事后(post-hoc)
3.3 模型不可知(Model-agnostic)vs. 模型特定(model-specific)
模型特定(Model specific):
- 使用模型的内部工作原理和特性来推导出可解释性机制。
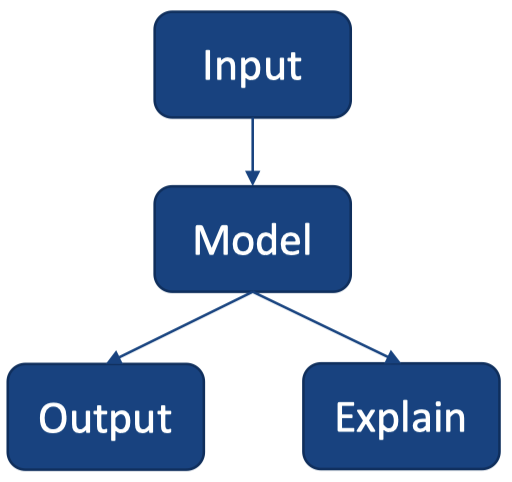
模型不可知(Model-agnostic):
- 仅使用输入和输出来推导出可解释性机制。
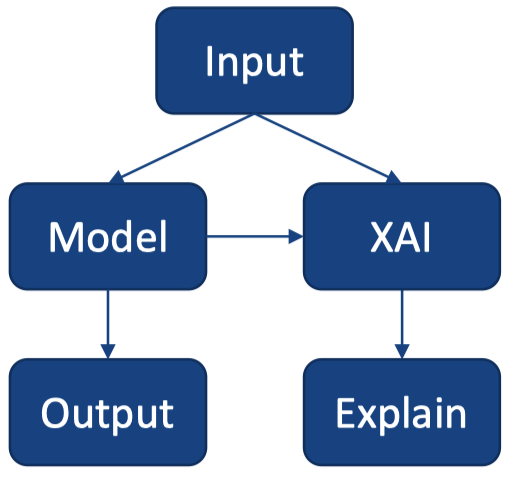
4. 可解释 AI 的基本方法
4.1 基于归因(Attribution-based)的解释

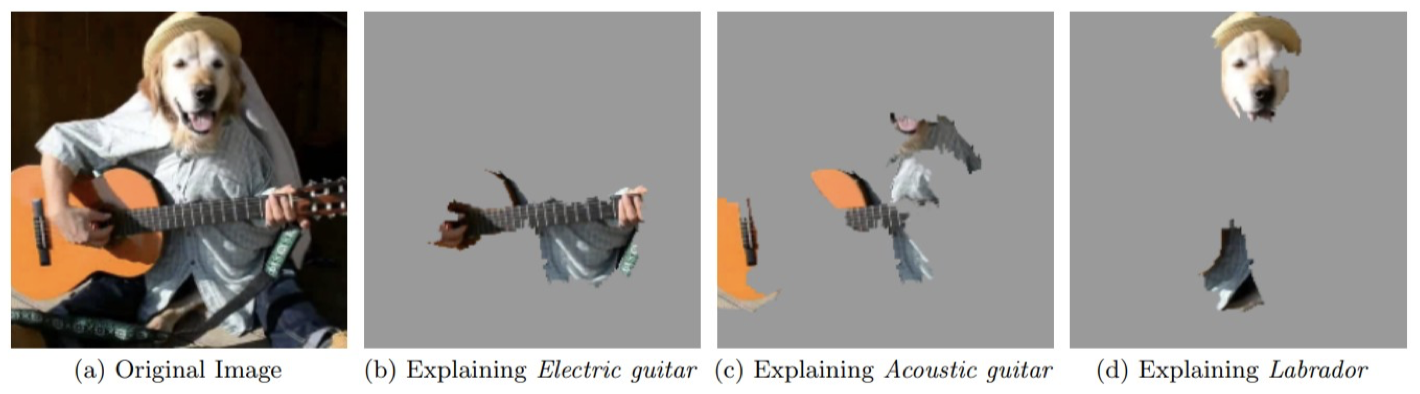
4.2 LIME:局部可解释、模型不可知的解释
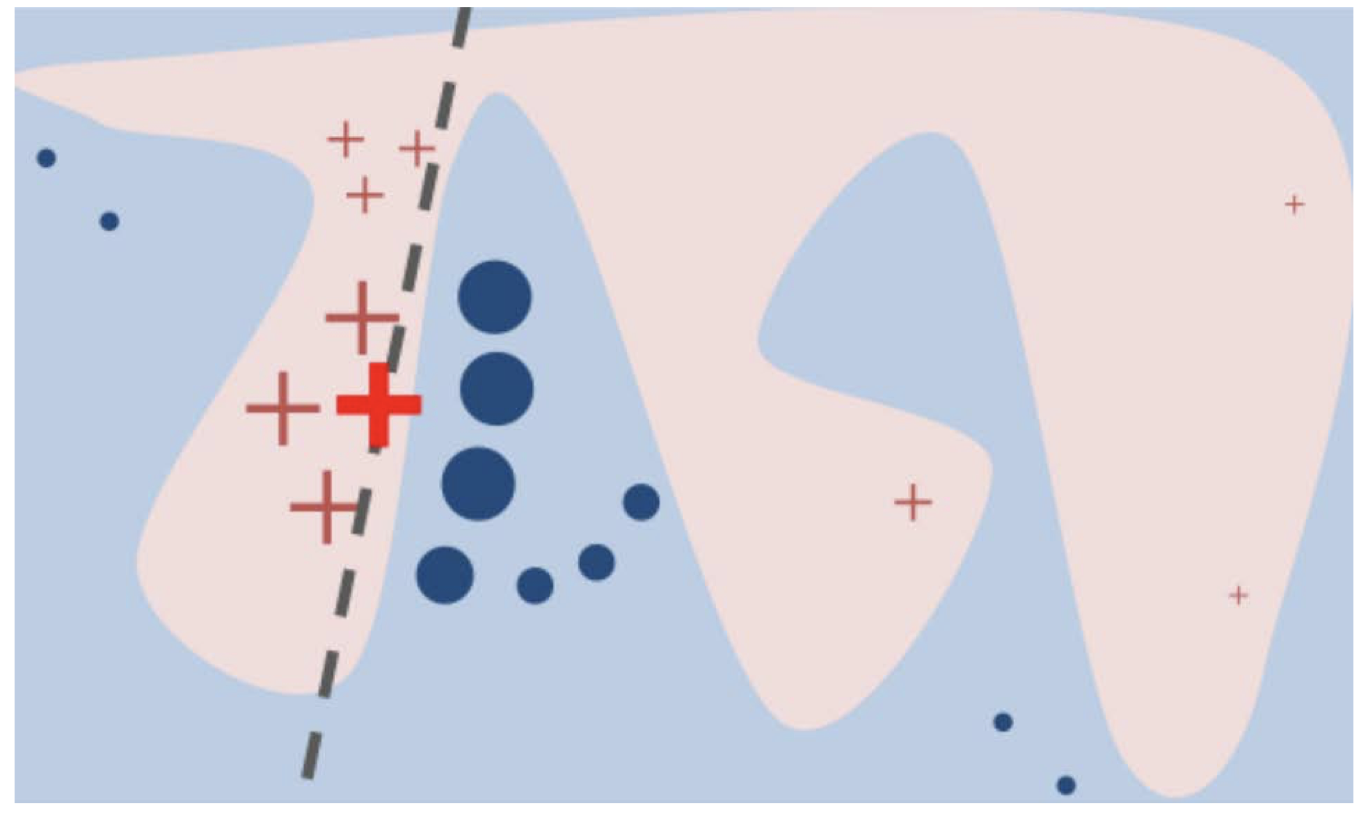
4.3 基于示例的解释:Prototypes

4.4 基于规则的解释
事后提取规则或直接学习可解释的规则:

4.5 对比解释
“关键的洞察力是认识到,一个人并不能解释事件本身,而是一个人解释了为什么令人费解的事件发生在目标案例中,而不是在一些反事实对比案例中。”
D. J. Hilton, Conversational processes and causal explanation, Psychological Bulletin. 107 (1) (1990) 65–81.
4.6 对比解释 —— 差异条件
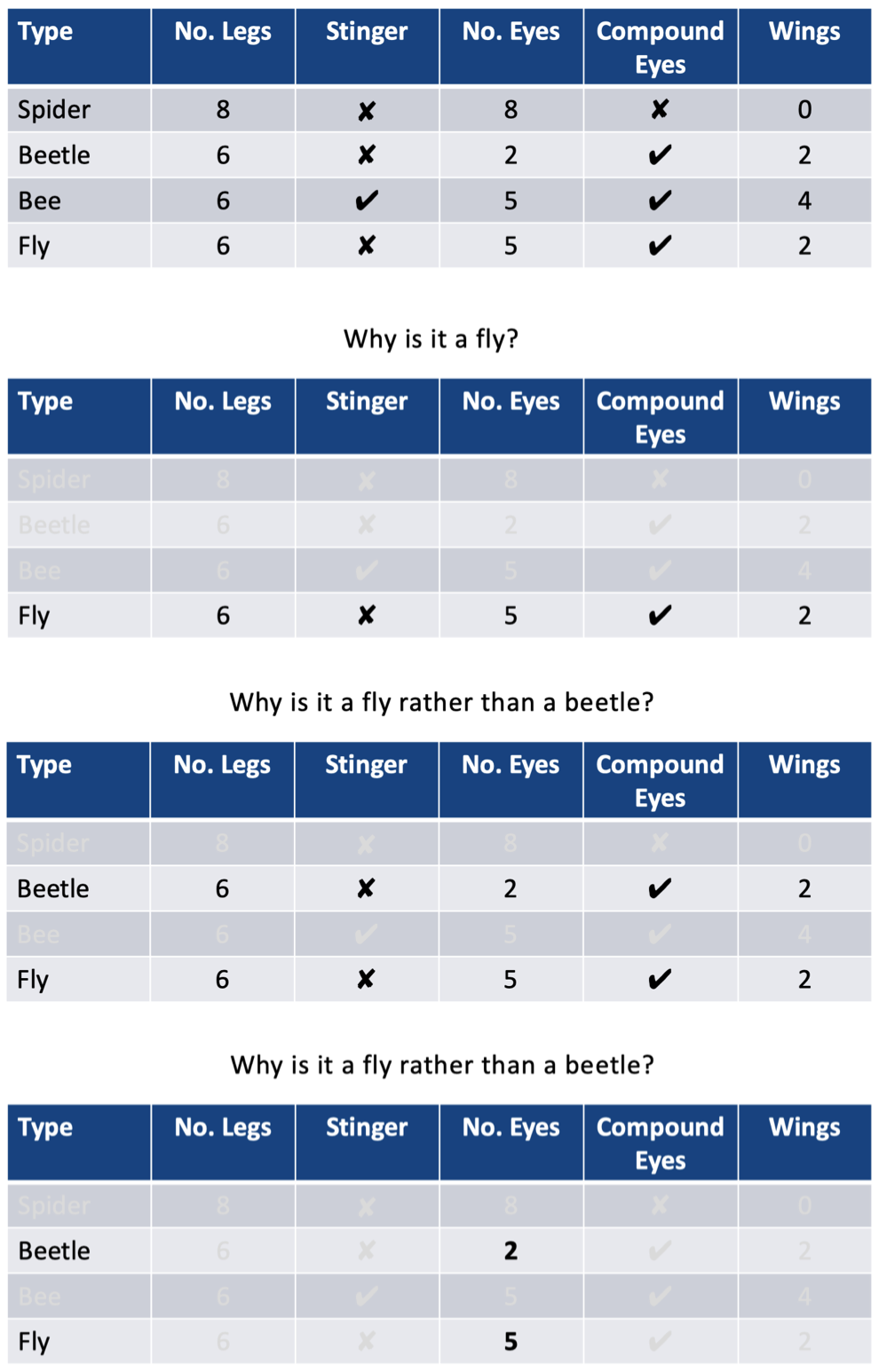
4.7 可解释性:总结
可解释性:
- 不同的人有不同的可解释性需求
- 信任与伦理
- 人和技术方面的挑战
- 不透明度
- 因果关系
- 人类解释
可解释性方法:
- 分类
- 局部 vs. 全局
- 可解释 vs. 事后
- 模型不可知 vs. 模型特定
- 关键方法
- 归因
- 示例
- 规则
- 对比
5. 推荐阅读
- Principles and Practice of Explainable Machine Learning.
- “But Why?” Understanding Explainable Artificial Intelligence.
- Interpretable Machine Learning.
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。 欢迎转载,并请注明来自:YEY 的博客 同时保持文章内容的完整和以上声明信息!