1. 条件相连 JOIN
计算留存率
1
2
3
4
5
6
SHOW DATABASES;
USE s2m2_hw;
SELECT DATABASE();
SHOW TABLES;
SELECT * FROM temp_user_act;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
WITH p2 AS
(WITH p AS
(SELECT
t0.user_id AS user_id,
t0.dates AS dates0,
t1.dates AS dates1,
t2.dates AS dates2,
t3.dates AS dates3,
t7.dates AS dates7
FROM temp_user_act AS t0
LEFT JOIN temp_user_act AS t1 ON t0.user_id = t1.user_id AND DATEDIFF(t1.dates, t0.dates) = 1
LEFT JOIN temp_user_act AS t2 ON t0.user_id = t2.user_id AND DATEDIFF(t2.dates, t0.dates) = 2
LEFT JOIN temp_user_act AS t3 ON t0.user_id = t3.user_id AND DATEDIFF(t3.dates, t0.dates) = 3
LEFT JOIN temp_user_act AS t7 ON t0.user_id = t7.user_id AND DATEDIFF(t7.dates, t0.dates) = 7)
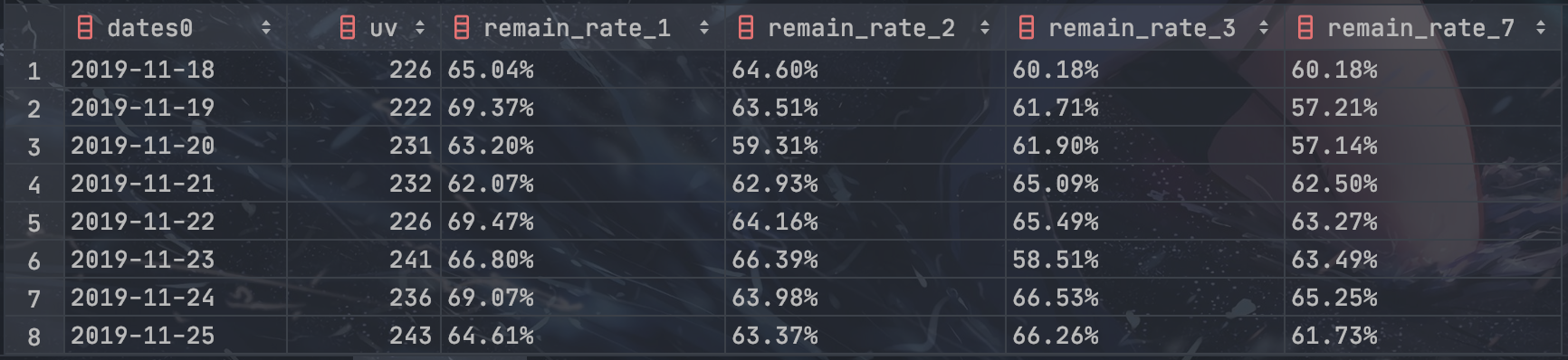
SELECT
dates0,
COUNT(DISTINCT user_id) AS uv,
COUNT(DISTINCT IF(dates1 IS NOT NULL, user_id, NULL)) AS remain_1,
COUNT(DISTINCT IF(dates2 IS NOT NULL, user_id, NULL)) AS remain_2,
COUNT(DISTINCT IF(dates3 IS NOT NULL, user_id, NULL)) AS remain_3,
COUNT(DISTINCT IF(dates7 IS NOT NULL, user_id, NULL)) AS remain_7
FROM p
GROUP BY dates0)
SELECT
dates0,
uv,
CONCAT(ROUND(remain_1 / uv * 100, 2), '%') AS remain_rate_1,
CONCAT(ROUND(remain_2 / uv * 100, 2), '%') AS remain_rate_2,
CONCAT(ROUND(remain_3 / uv * 100, 2), '%') AS remain_rate_3,
CONCAT(ROUND(remain_7 / uv * 100, 2), '%') AS remain_rate_7
FROM p2;
2. 顺序相连 LAG
计算各作者的连续更新天数:第 1 步
1
SELECT * FROM temp_author_act;
1
2
3
4
5
6
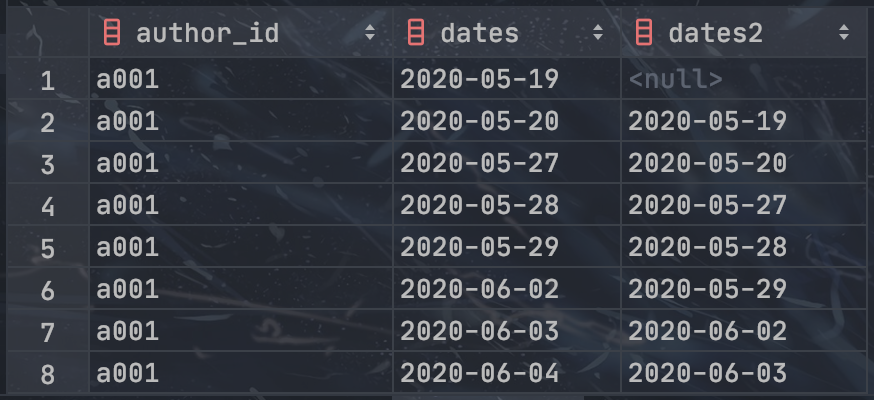
-- 利用 LAG() 偏移分析函数构造一个偏移日期列:
SELECT
author_id,
dates,
LAG(dates) OVER (PARTITION BY author_id ORDER BY dates) AS dates2
FROM temp_author_act;
3. 连续值统计 @
计算各作者的连续更新天数:第 2 步
注意:
- MySQL 中通过
@声明一个变量,通过:=给变量赋值,例如@r := 0。 - MySQL 中数据是逐行生成的,这里
@r相当于一个寄存器,在数据行不断生成的过程中实时更新@r,从而统计出连续值。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
-- 定义一个变量 r,初始化为 0,结合 DATEDIFF 函数,计算作者连续更新天数:
-- 如果 dates 和 dates2 相差一天,则 r = r + 1; 否则,r = 0
WITH p AS
(SELECT
author_id,
dates,
LAG(dates) OVER (PARTITION BY author_id ORDER BY dates) AS dates2,
@r := 0
FROM temp_author_act)
SELECT
author_id,
dates,
dates2,
IF(DATEDIFF(dates, dates2) = 1, @r := @r + 1, @r := 0) AS r2
FROM p;
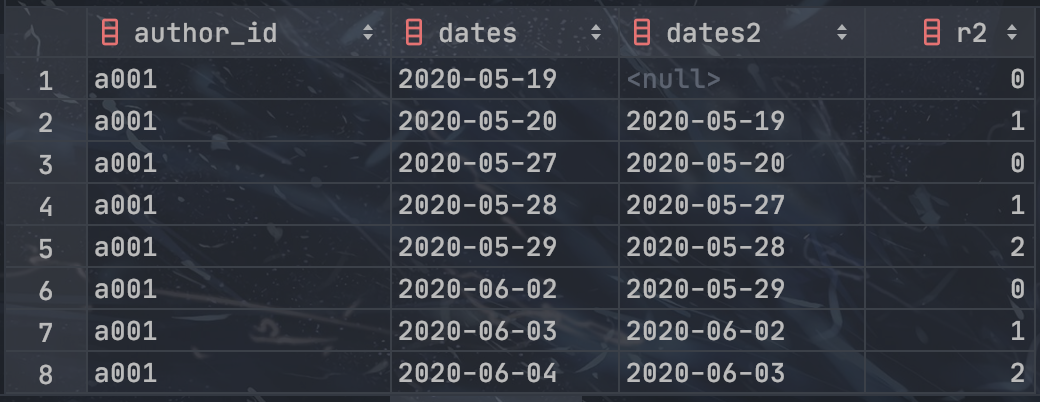
计算每个作者的最大连续更新天数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
WITH p2 AS
(WITH p AS
(SELECT
author_id,
dates,
LAG(dates) OVER (PARTITION BY author_id ORDER BY dates) AS dates2,
@r := 0
FROM temp_author_act)
SELECT
author_id,
dates,
dates2,
IF(DATEDIFF(dates, dates2) = 1, @r := @r + 1, @r := 0) AS r2
FROM p)
SELECT
author_id,
MAX(r2)
FROM p2
GROUP BY author_id;

4. 窗口排序
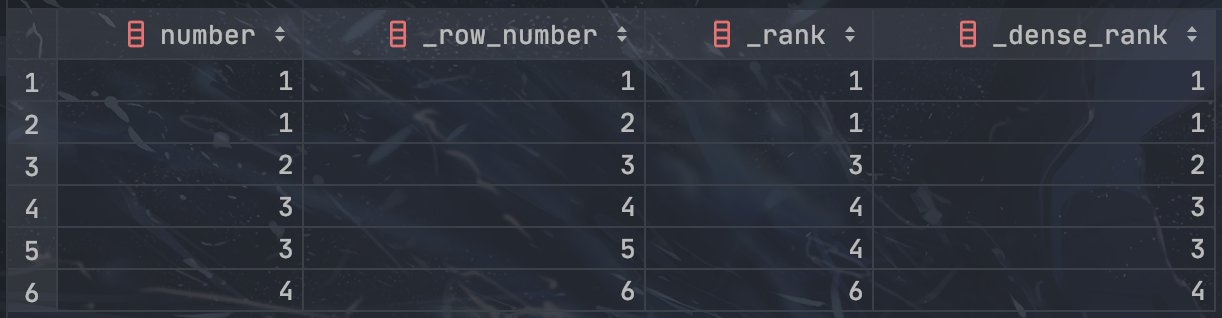
三种排序窗口函数:
ROW_NUMBER():不重复连续数字RANK():考试排名DENSE_RANK():等级排名
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
CREATE TABLE sort_func_test (
number INT
);
INSERT INTO sort_func_test VALUES (1);
INSERT INTO sort_func_test VALUES (1);
INSERT INTO sort_func_test VALUES (2);
INSERT INTO sort_func_test VALUES (3);
INSERT INTO sort_func_test VALUES (3);
INSERT INTO sort_func_test VALUES (4);
SELECT
number,
ROW_NUMBER() OVER (ORDER BY number) AS _row_number,
RANK() OVER (ORDER BY number) AS _rank,
DENSE_RANK() OVER (ORDER BY number) AS _dense_rank
FROM sort_func_test;
5. 练习:美团数据分析 SQL 笔试题
数据表:
- 商家表:有日期、商家 ID、城市、商家合作开始日期(时间戳格式)、营业时长(小时);
- 订单数据表:有订单 ID、商家 ID、订单金额、订单时间、商家所在城市、订单时段(早餐、午餐、晚餐)、运费原价金额、运费减免金额。
由于没有原始的美团面试题数据,本例中使用的是我们自己生成的一些模拟数据:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
CREATE DATABASE meituan CHARSET utf8;
USE meituan;
-- 创建商家表
CREATE TABLE stores (
`date` DATE,
storeID VARCHAR(25),
city VARCHAR(25),
beginTimestamp LONG,
businessHour INTEGER
);
-- 创建订单表
CREATE TABLE orders (
`index` INTEGER,
orderID VARCHAR(100),
storeID VARCHAR(25),
money DOUBLE,
`date` DATE,
city VARCHAR(25),
period VARCHAR(25),
freight_org INTEGER,
freight_nus INTEGER
);
1
2
-- 查看商家表中的数据
SELECT * FROM stores;
1
2
-- 查看订单表中的数据
SELECT * FROM orders;

5.1 第一题
5.1.1 题目要求
商家表:有日期、商家 ID、城市、商家合作开始日期(时间戳格式)、营业时长(小时)。
要求:
- 取每个城市本月日均营业时长(需刨除当天不营业商家,营业时长单位:小时);
- 取截止今日每个商家已合作天数。
5.1.2 解题思路
要求 1:取每个城市本月日均营业时长(需刨除当天不营业商家,营业时长单位:小时)。
首先,我们看一下 stores 表中都有哪些月份:
1
SELECT MONTH(date) FROM stores GROUP BY MONTH(date);
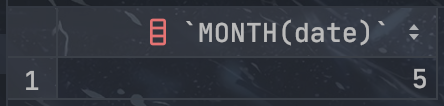
可以看到,stores 数据表中所有数据都来自 5 月份,所以我们假设这里要求的本月是指 5 月份:
1
2
3
4
5
6
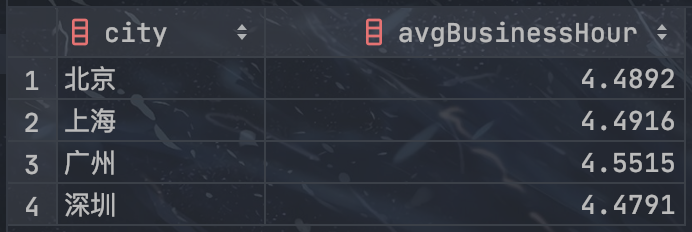
SELECT
city,
AVG(businessHour) AS avgBusinessHour
FROM stores
WHERE MONTH(date) = 5 AND businessHour > 0
GROUP BY city;
要求 2:取截止今日每个商家已合作天数。
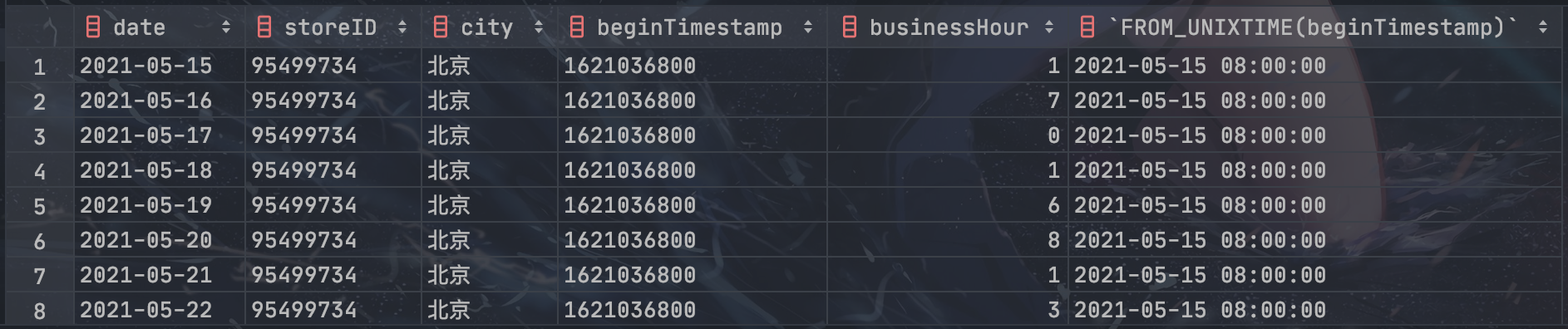
首先,使用 FROM_UNIXTIME() 函数将时间戳转换成 “日期 + 时间” 格式:
1
SELECT *, FROM_UNIXTIME(beginTimestamp) FROM stores;
使用 DATEDIFF() 和 NOW() 函数计算各商家加入美团至今的天数。由于我们使用了 GROUP BY 按照 storeID 进行分组,所以在转换时间戳时需要使用聚合函数(可以看到,同一 storeID 对应的 beginTimeStamp 都是一样的,所以这里我们使用 MIN()、 MAX() 或者 AVG() 都可以):
1
2
3
4
5
SELECT
storeID,
DATEDIFF(NOW(), FROM_UNIXTIME(MIN(beginTimestamp))) AS "加入美团的天数"
FROM stores
GROUP BY storeID;

5.2 第二题
5.2.1 题目要求
订单数据表:有订单 ID、商家 ID、订单金额、订单时间、商家所在城市、订单时段(早餐、午餐、晚餐)、运费原价金额、运费减免金额。
要求:
- 取每个城市当月订单量排名前 10 名商家,需要商家 ID、订单量、订单量对比上月增速(月环比增长率)、对比大盘订单量(大盘:整体商家汇总)的增速差;
- 取每个城市当月订单量排名前 10% 商家的总数,以及其中早餐商家总数、晚餐商家总数、运费全免商家总数(运费全免商家:只要有一单全免就是运费全免商家)。
5.2.2 解题思路
要求 1:取每个城市当月订单量排名前 10 名商家,需要商家 ID、订单量、订单量对比上月增速(月环比增长率)、对比大盘订单量(大盘:整体商家汇总)的增速差。
首先,我们看一下 orders 表中都有哪些月份:
1
SELECT MONTH(date) FROM orders GROUP BY MONTH(date);
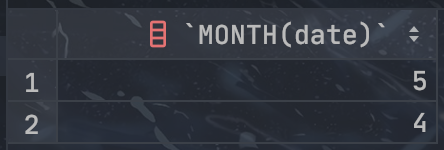
可以看到,orders 表中所有数据都来自 4、5 月份,所以我们假设这里的当前月份是指 5 月份:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
-- 获取当月(5月)数据,保存到视图 this_month 中
CREATE VIEW this_month AS
SELECT * FROM orders WHERE MONTH(date) = 5;
-- 获取上月(4月)数据,保存到视图 last_month 中
CREATE VIEW last_month AS
SELECT * FROM orders WHERE MONTH(date) = 4;
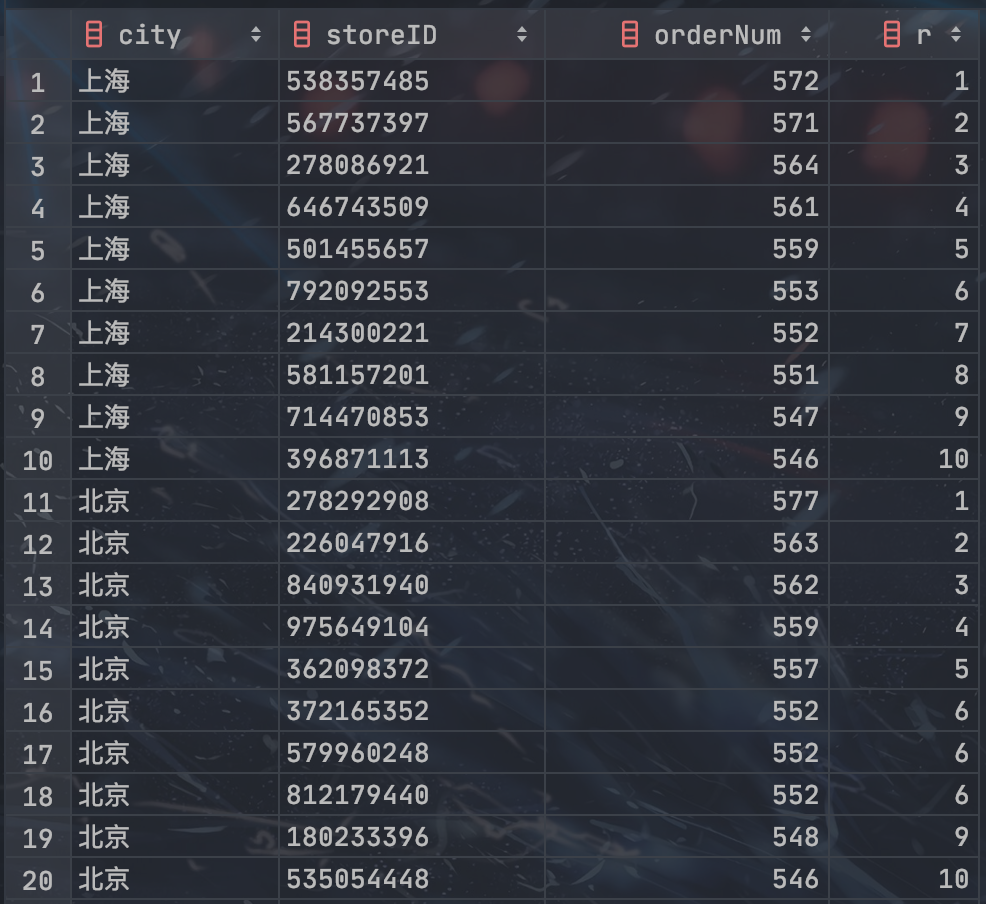
-- 获取每个城市当月订单量排名前 10 名商家的商家 ID、订单量和排名
SELECT *
FROM
(SELECT
*,
RANK() OVER (PARTITION BY city ORDER BY orderNum DESC) AS r
FROM
(SELECT
city,
storeID,
COUNT(DISTINCT orderID) AS orderNum
FROM this_month
GROUP BY city, storeID
) AS f1
) AS f2
WHERE r <= 10;
1
2
3
4
5
6
7
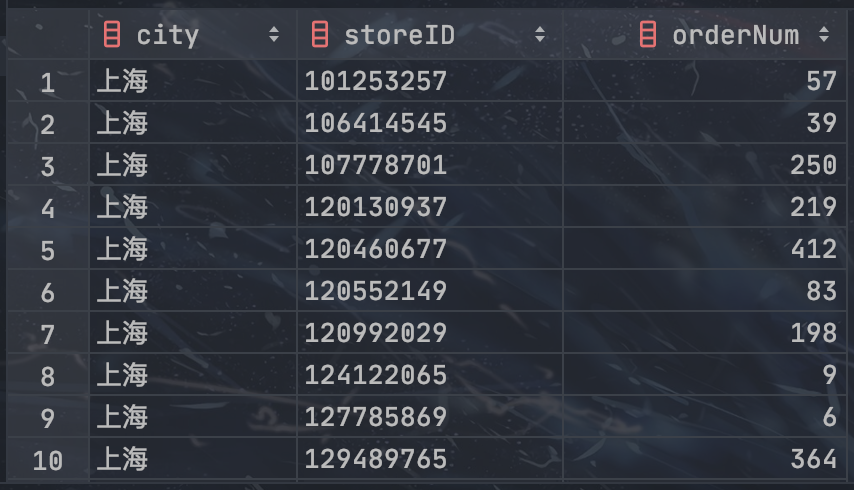
-- 获取上月每个城市全部商家的订单量数据
SELECT
city,
storeID,
COUNT(DISTINCT orderID) AS orderNum
FROM last_month
GROUP BY city, storeID;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
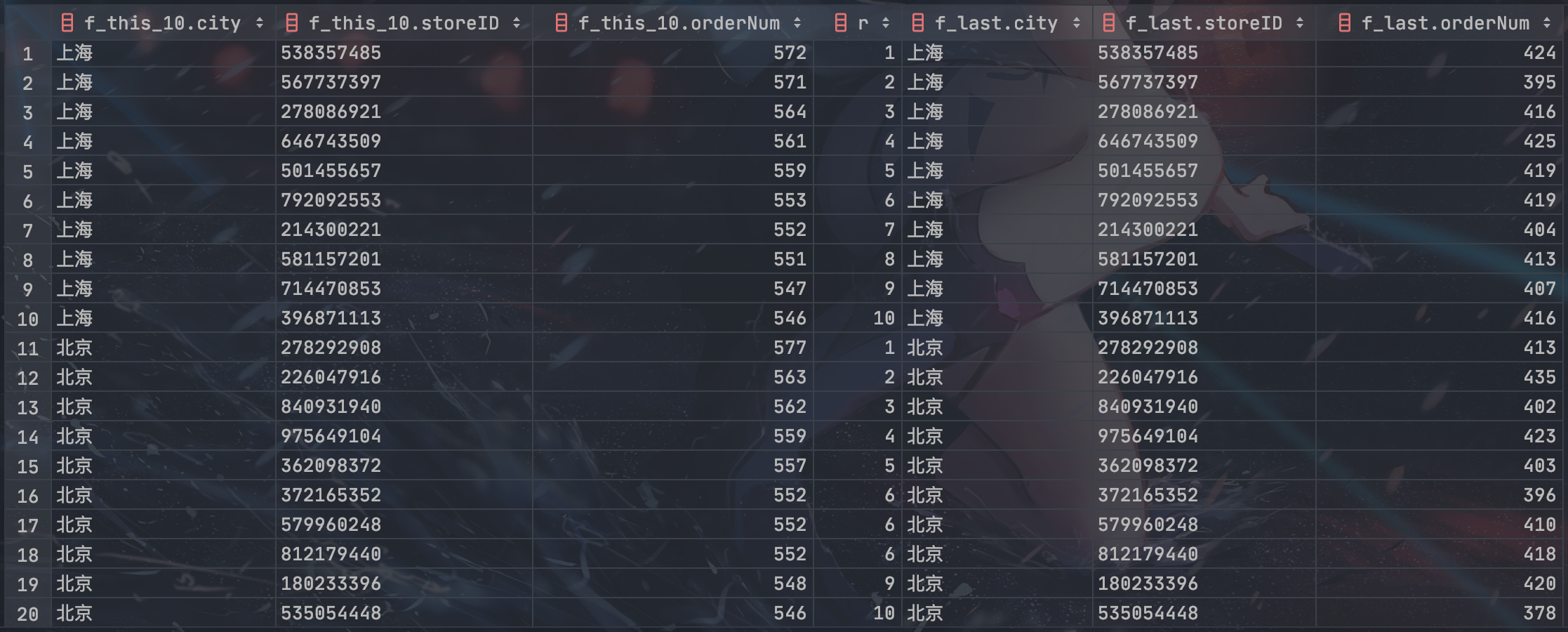
-- 使用 LEFT JOIN 连接每个城市当月订单量排名前 10 名商家的订单量数据和每个城市各商家上月订单量数据
SELECT *
FROM
-- 每个城市当月订单量排名前 10 名商家的订单量数据
(SELECT *
FROM
(SELECT
*,
RANK() OVER (PARTITION BY city ORDER BY orderNum DESC) AS r
FROM
(SELECT
city,
storeID,
COUNT(DISTINCT orderID) AS orderNum
FROM this_month
GROUP BY city, storeID
) AS f1
) AS f2
WHERE r <= 10
) AS f_this_10
LEFT JOIN
-- 每个城市各商家上月订单量数据
(SELECT
city,
storeID,
COUNT(DISTINCT orderID) AS orderNum
FROM last_month
GROUP BY city, storeID
) AS f_last
ON f_this_10.storeID = f_last.storeID;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
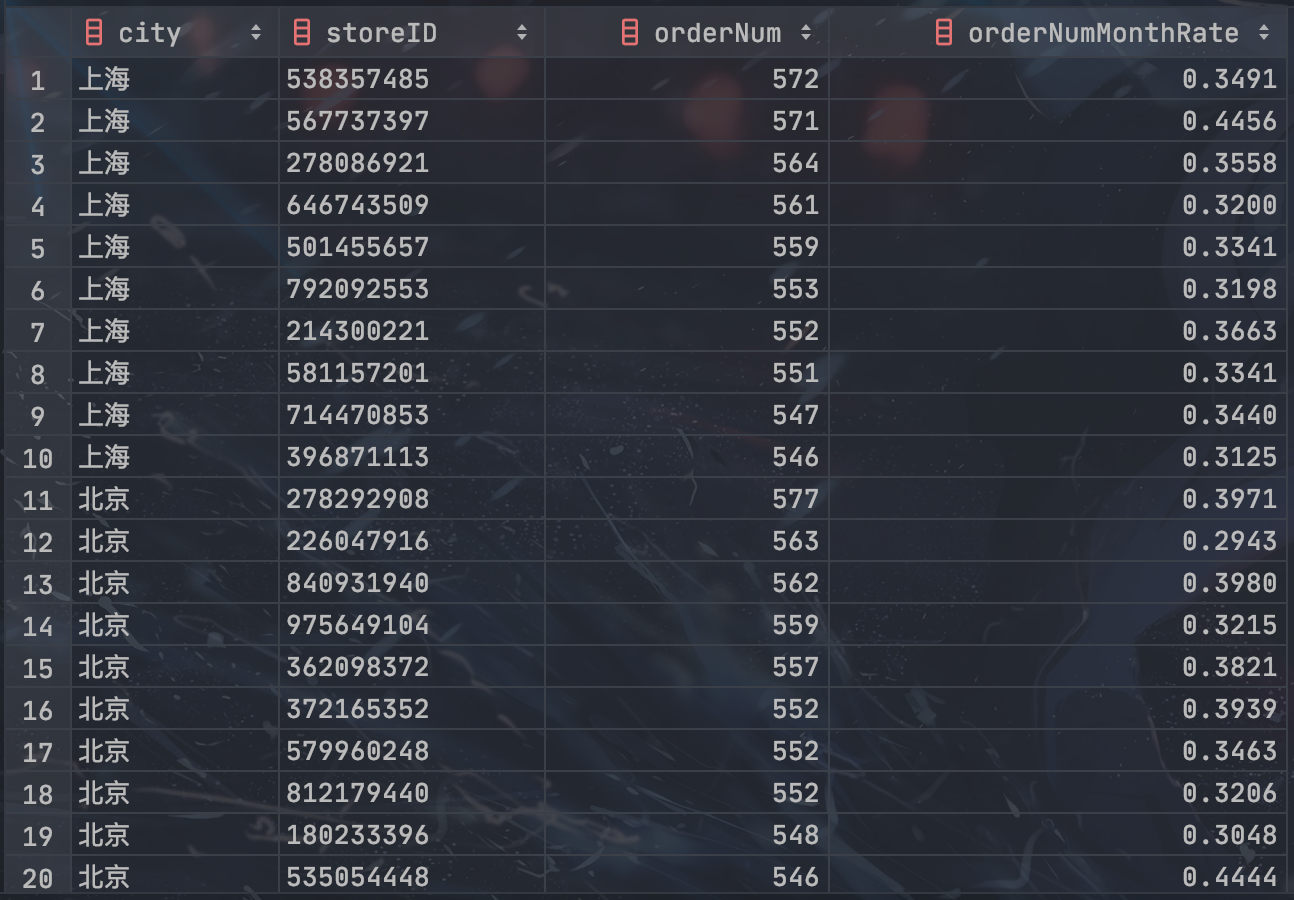
-- 整理上面的结果,选取每个城市当月订单量排名前 10 名商家的商家 ID、订单量、订单量对比上月增速(月环比增长率)
SELECT
f_this_10.city AS city,
f_this_10.storeID AS storeID,
f_this_10.orderNum AS orderNum,
(f_this_10.orderNum - f_last.orderNum) / f_last.orderNum AS orderNumMonthRate
FROM
-- 每个城市当月订单量排名前 10 名商家的商家 ID、订单量
(SELECT *
FROM
(SELECT
*,
RANK() OVER (PARTITION BY city ORDER BY orderNum DESC) AS r
FROM
(SELECT
city,
storeID,
COUNT(DISTINCT orderID) AS orderNum
FROM this_month
GROUP BY city, storeID
) AS f1
) AS f2
WHERE r <= 10
) AS f_this_10
LEFT JOIN
-- 每个城市各商家上月订单量
(SELECT
city,
storeID,
COUNT(DISTINCT orderID) AS orderNum
FROM last_month
GROUP BY city, storeID
) AS f_last
ON f_this_10.storeID = f_last.storeID;
1
2
3
4
5
-- 查看当月大盘订单量(大盘:整体商家汇总)对比上月的增速
SELECT (f1.orderNum - f2.orderNum) / f2.orderNum AS totalOrderNumMonthRate
FROM
(SELECT COUNT(DISTINCT orderID) AS orderNum FROM this_month) AS f1,
(SELECT COUNT(DISTINCT orderID) AS orderNum FROM last_month) AS f2;

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
-- 用笛卡尔积连接前两步的结果,并计算每个城市当月订单量排名前 10 名商家的订单量增速对比大盘订单量的增速差。
SELECT
city,
storeID,
orderNum,
CONCAT(ROUND(orderNumMonthRate * 100, 2), '%') AS orderNumMonthRate,
CONCAT(ROUND((orderNumMonthRate - totalOrderNumMonthRate) * 100, 2), '%') AS deltaOrderNumMonthRate
FROM
-- 每个城市当月订单量排名前 10 名商家的订单量相关数据
(SELECT
f_this_10.city AS city,
f_this_10.storeID AS storeID,
f_this_10.orderNum AS orderNum,
(f_this_10.orderNum - f_last.orderNum) / f_last.orderNum AS orderNumMonthRate
FROM
(SELECT *
FROM
(SELECT
*,
RANK() OVER (PARTITION BY city ORDER BY orderNum DESC) AS r
FROM
(SELECT
city,
storeID,
COUNT(DISTINCT orderID) AS orderNum
FROM this_month
GROUP BY city, storeID) AS f1
) AS f2
WHERE r <= 10
) AS f_this_10
LEFT JOIN
(SELECT
city,
storeID,
COUNT(DISTINCT orderID) AS orderNum
FROM last_month
GROUP BY city, storeID
) AS f_last
ON f_this_10.storeID = f_last.storeID
) AS f_10,
-- 当月大盘订单量(大盘:所有城市全部商家汇总)对比上月的增速
(SELECT
(f1.orderNum - f2.orderNum) / f2.orderNum AS totalOrderNumMonthRate
FROM
(SELECT COUNT(DISTINCT orderID) AS orderNum FROM this_month) AS f1,
(SELECT COUNT(DISTINCT orderID) AS orderNum FROM last_month) AS f2
) AS f_total;

要求 2:取每个城市当月订单量排名前 10% 商家的总数,以及其中早餐商家总数、晚餐商家总数、运费全免商家总数(运费全免商家:只要有一单全免就是运费全免商家)。
1
2
3
4
5
6
7
-- 查看每个城市当月的商家数量和前 10% 的商家数量(取少不取多)
SELECT
city,
COUNT(DISTINCT storeID) AS storeNum,
FLOOR(COUNT(DISTINCT storeID) / 10) AS top10StoreNum
FROM this_month
GROUP BY city;

1
2
3
4
5
6
7
-- 查看每个城市当月各商家的订单量
SELECT
city,
storeID,
COUNT(DISTINCT orderID) AS orderNum
FROM this_month
GROUP BY city, storeID;

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
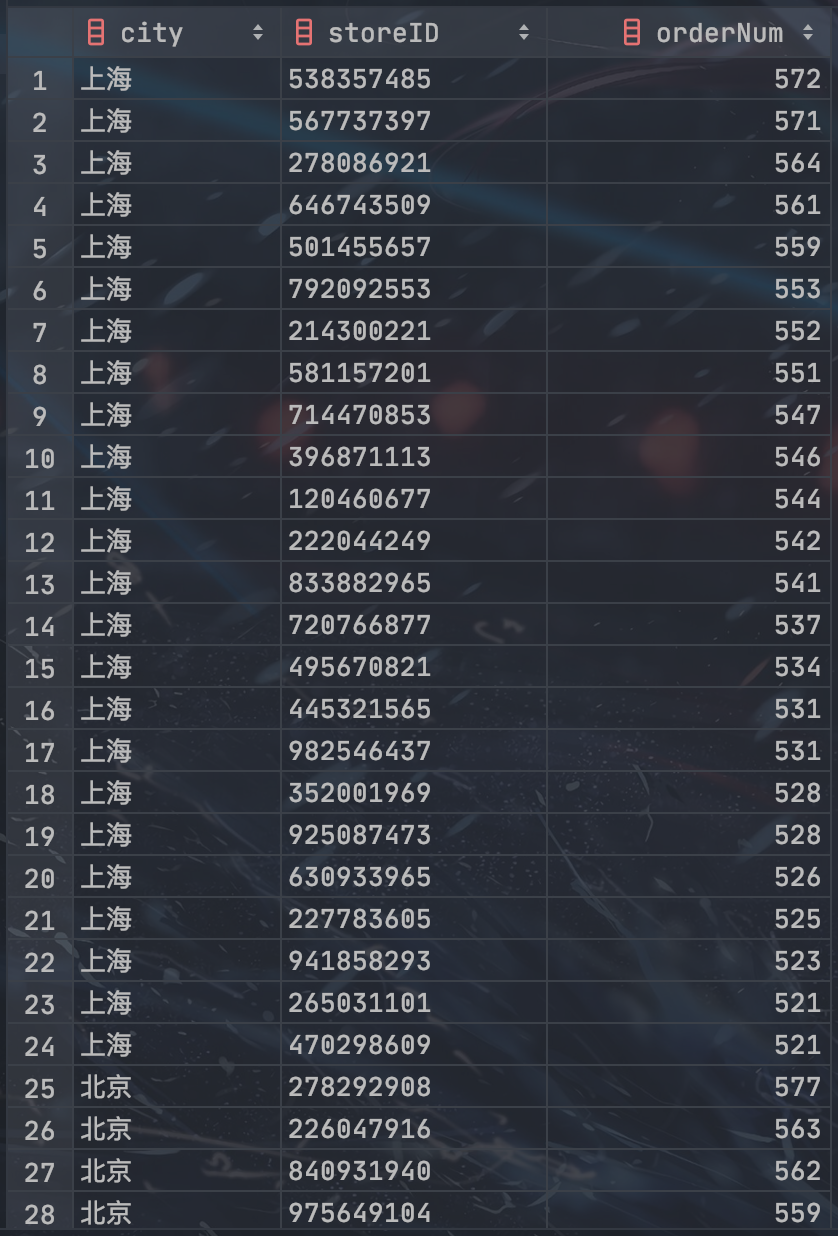
-- 方法 1:连接上面两个表结果,查看每个城市当月订单量排名前 10% 商家的 ID 和订单量
SELECT
city,
storeID,
orderNum
FROM
(SELECT
f1.city AS city,
storeID,
orderNum,
storeNum,
ROW_NUMBER() OVER (PARTITION BY f1.city ORDER BY orderNum DESC) / storeNum AS rate
FROM
-- 每个城市当月各商家的订单量
(SELECT
city,
storeID,
COUNT(DISTINCT orderID) AS orderNum
FROM this_month
GROUP BY city, storeID) AS f1
LEFT JOIN
-- 每个城市当月的商家数量
(SELECT
city,
COUNT(DISTINCT storeID) AS storeNum
FROM this_month
GROUP BY city) AS f2
ON f1.city = f2.city) AS f
WHERE rate <= 0.1;
或者,我们可以使用分组排序窗口函数 NTILE() 获取每个城市当月订单量排名前 10% 商家。
注意:
-
NTILE(n),用于将分组数据按照顺序切分成 n 片,返回当前切片值 NTILE()不支持ROWS BETWEEN的用法- 切片如果不均匀,默认增加第一个切片的分布
NTILE()函数的分组依据(约定):- 每组的记录数不能大于它上一组的记录数,即编号小的桶放的记录数不能小于编号大的桶。也就是说,第 1 组中的记录数只能大于等于第 2 组及以后各组中的记录数;
- 所有组中的记录数要么都相同,要么从某一个记录较少的组(命名为 X)开始后面所有组的记录数都与该组(X组)的记录数相同。也就是说,如果有个组,前三组的记录数都是 9,而第四组的记录数是 8,那么第五组和第六组的记录数也必须是 8。
由于这里我们要取的是前 10%,所以我们应该将每个城市的商家按照订单量分成 10 组切片,并且如果切片不均匀,则将多余记录放在订单量最少的组中(即取少不取多)。也就是说,我们在使用 NTILE(10) 时,OVER() 内部的 ORDER BY 可以选择按照订单量升序排列,然后取最后一组(第 10 组)切片。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
-- 方法 2:查看每个城市当月订单量排名前 10% 商家的 ID 和订单量,并保存到视图 v_top10 中
CREATE VIEW v_top10 AS
SELECT
city,
storeID,
orderNum
FROM
(SELECT
*,
NTILE(10) OVER (PARTITION BY city ORDER BY orderNum) AS n
FROM
(SELECT
city,
storeID,
COUNT(DISTINCT orderID) AS orderNum
FROM this_month
GROUP BY city, storeID) AS f
) AS f1
WHERE n = 10
ORDER BY city, orderNum DESC;
SELECT * FROM v_top10;
接下来,我们来看一下各商家是否属于早餐商家、晚餐商家或者运费全免商家。注意这里我们对这三类商家的定义:
- 早餐商家:只要该商家订单数据中的
period出现过一次早餐,则记为早餐商家; - 晚餐商家:只要该商家订单数据中的
period出现过一次晚餐,则记为晚餐商家; - 运费全免商家:只要该商家订单数据中出现过一次
freight_org与freight_nus相等的情况 ,则记为运费全免商家。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
-- 取每个城市当月订单量排名前 10% 商家的总数,以及其中早餐商家总数、晚餐商家总数、运费全免商家总数
-- 注意:运费全免商家分两种情况:1. 减免运费金额 = 原始运费金额;2. 原始运费金额 = 0
WITH p AS (
SELECT
v_top10.city AS city,
v_top10.storeID AS storeID,
orderNum,
period,
freight_org,
freight_nus
FROM v_top10 LEFT JOIN orders ON v_top10.storeID = orders.storeID)
SELECT
city,
COUNT(DISTINCT storeID) AS storeNum,
COUNT(DISTINCT IF(period = '早餐', storeID, NULL)) AS breakfastStoreNum,
COUNT(DISTINCT IF(period = '晚餐', storeID, NULL)) AS dinnerStoreNum,
COUNT(DISTINCT IF(freight_org = freight_nus OR freight_org = 0, storeID, NULL)) AS freeStoreNum
FROM p
GROUP BY city;

本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。 欢迎转载,并请注明来自:YEY 的博客 同时保持文章内容的完整和以上声明信息!