1. 海量数据的形成
首先我们看一下什么是大数据。
大数据中的 “大” 主要体现在以下两个方面:
-
记录条数多
-
维度多
记录条数多就是说我们收集的数据行数比较多,比如我们可以收集全国十几亿人的姓名,这里的十几亿就是记录条数,姓名就是一个维度。当然,如果仅仅只是收集姓名这一维度,得到的数据没有任何价值。如果我们对维度进行扩充,即同时收集这些人的年龄、性别、地区、家庭收入情况等信息,这样收集到的数据就产生了一定的商业价值。例如,对于互联网电商,我们可以根据用户收入的高低将其分为高消费能力人群和低消费能力人群,然后我们就可以将不同价格的商品分别推送给这两类人群;又例如对于零食商家,我们知道国人在饮食上存在 “南甜北咸” 的习惯,这样就可以根据用户的地区向其推送不同口味的零食。
1.1 海量数据的形成
随着大数据时代的来临,如今基本上每个公司无论大小都特别注重数据了,以至于在刚开始运营网站或者 APP 的时候就做了很多埋点并收集了尽可能多的数据信息。比如可能收集了二十个维度的数据,但只用到了其中两三个维度的数据,这是由于成熟企业和发展中企业的定位不同造成的。对于互联网公司,在初创时会集中精力研发产品;随着产品的发布,公司希望用户越来越多;当产品稳定下来并且用户达到一定量级后, 就需要产生一定的商业价值,促使这些用户在该产品上进行消费。因此,随着企业发展到不同阶段,其所关注的数据的部分是不同的,如果在产品初期就收集了很多数据,就造成了部分数据在当时的场景下是没有价值的,这种现象被称为 “价值密度低”。由于大数据存在这种价值密度低的情况,所以数据分析师需要从海量数据中找出有价值的信息,而这也是作为数据分析师能力的一种体现。
下面我们通过一些简单例子来看一下 海量数据的形成:
- 2021年第一季度抖音日活(DAU)数据:峰值约7亿、平均值超6亿
- 2020年拼多多 APP 平均月活(MAU)跃用户数达7.199亿
- 2020年爱奇艺月活跃用户超5.6亿
- 2019支付宝的日活突破3亿
1.2 传统数据库面临的挑战
我们再看一下一些常见的 传统数据库的存储容量:
| 数据库 | 单表建议存储量(条) |
|---|---|
| ACCESS | 小于 10W |
| MySQL | 小于 500W(数据量多可分区) |
| Oracle | 小于 500W(数据量多可分区) |
可以看到,上面这些 APP 每天或者每个月的独立访客数量多达数亿。想象一下,如果某天某个用户第一次登陆 APP 并浏览了很多页面,然后当天第二次登陆又浏览了很多页面,这样每一次浏览行为都会被记录:某用户几点几分浏览了哪个页面、停留时长多久、是否点赞、刷礼物等等。可想而知,几亿的用户会产生多大的数据量,而这种体量的数据存储对于上面这些传统数据库而言是非常大的挑战,这将导致这些数据库的性能受到严重影响甚至瘫痪。例如,当 Excel 单表存储超过 20W 条数据后,打开文件都会变得异常卡顿。另外,传统数据库一般存储的都是结构化数据,随着目前移动互联网的迅速发展,诸如图片、音频、视频这类非结构化数据也有存储需求,而传统数据库通常只能存储这些文件的路径而无法存储其中的内容。
传统数据库面临的挑战:
- 无法满足快速增长的海量数据存储需求;
- 无法有效处理不同类型的数据(图片、音频、视频等);
- 计算和处理能力不足。
1.3 数据仓库的作用
针对传统数据库面临的这些问题,我们可以通过 数据仓库 解决。例如,抖音的用户播放记录、拼多多的用户行为日志、爱奇艺的用户行为日志、支付的支付记录,不会发生变更的实时数据以及历史存档数据都可以放入到数仓中。
数据仓库作用:
- 解决历史数据积存以及处理能力的问题(分布式存储与处理);
- 将各种数据源整合到一个统一的数据中心,解决数据壁垒(仓库的集成性特点);
- 规范表、字段名称,统一字段数据格式,完善注释内容;
- 生产适合 OLAP 的大宽表,方便用户多维度快速分析(仓库的主题性特点);
- 数据质量的保证和指标口径的一致性。
1.4 常见的数据仓库产品
我们来看一下目前市面上常见的数据仓库产品都有哪些:
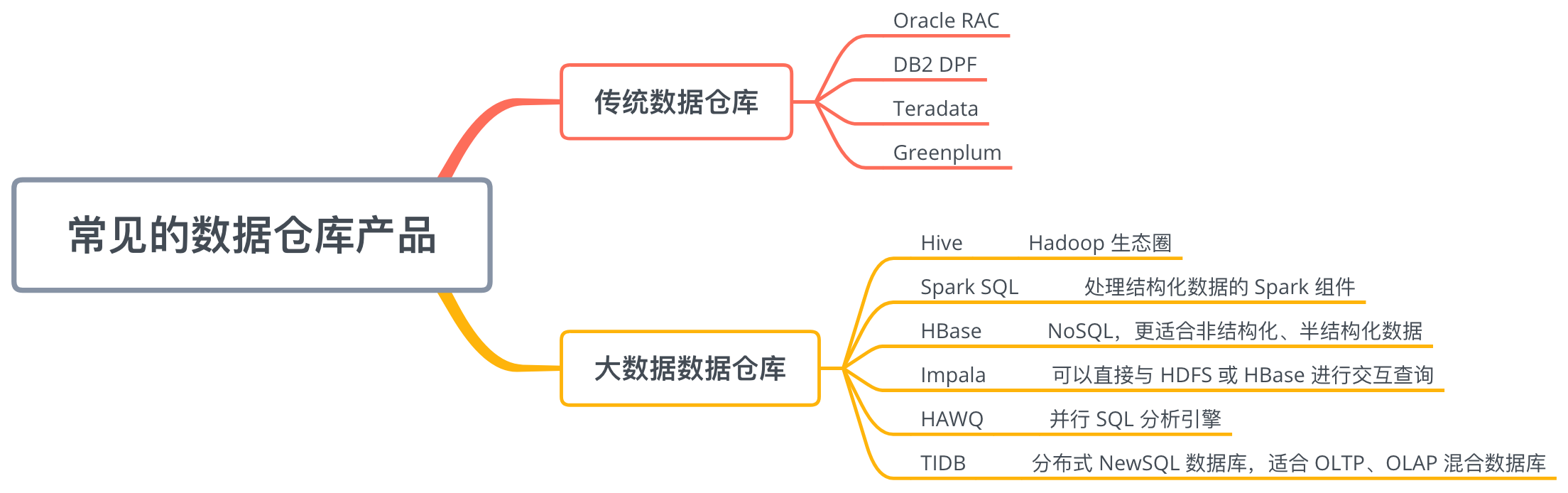
传统的数据仓库,像以往的淘宝、京东用的都是 Oracle RAC,另外 DB2 DPF 也比较常见。现在很多企业都使用的是面向大数据的数据仓库,其中 Hive 和 Spark SQL 最为常见。本系列教程我们主要学习 Hive,它是基于 Hadoop 生态圈的。
至此,我们介绍了大数据是如何形成的,以及数据分析师需要从低价值密度的海量数据中挖掘出有价值的信息。我们还介绍了传统数据库在面对海量数据时的存储、处理等方面的挑战,以及数据仓库是如何解决这些问题的。
2. 学习内容
2.1 数据仓库分层设计
根据公司业务的不同,数据仓库需要进行分层设计,其实就是为公司的数据存储和处理制定一个规范。
数据仓库分层设计:
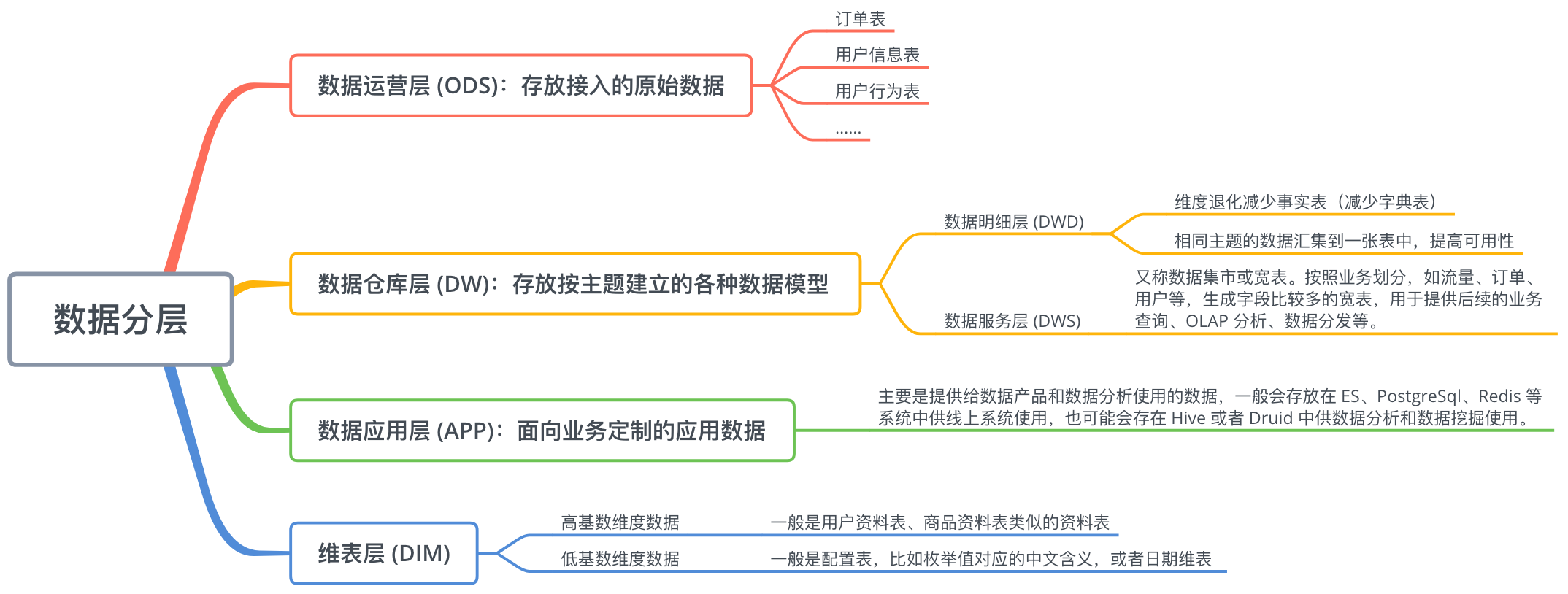
一般可以将数据仓库分为 4 层:
-
数据运营层 (ODS):存储的原始业务数据,便于回溯。
-
数据仓库层 (DW):按照分析主题或者部门进行划分,可以细分为明细层(DWD)和服务层(DWS)。
- 数据明细层 (DWD):DWD 层会减少来自 ODS 层的业务数据中的非必要数据,因为到这里已经与分析主题相关了,所以需要减少一些不必要字段;另外,在诸如 MySQL 这类传统数据库中,由于其存储能力有限,我们通过多表关联来解决数据冗余问题,而在 DWD 层则会将这些数据整合到一张表中。例如,订单表中的 “地区” 字段存储的是每个地区的 ID,而在地区表中这些 ID 都有对应的城市名,因此在 DWD 中就会将这些城市名还原到订单表中。
- 数据服务层 (DWS):DWS 层会按照业务将数据进行整合,形成宽表。例如,某个宽表是用于日报业务的,另一个宽表是用于周报业务的等等。所以,到这里我们实际上完成了对数据的一个轻度汇总。
-
数据应用层 (APP):在这里,主要是提供给数据产品和数据分析使用的数据,一般会存放在 ES、PostgreSql、Redis等系统中供线上系统使用,也可能会存在 Hive 或者 Druid 中供数据分析和数据挖掘使用。比如我们经常说的报表数据,一般就放在这里。
-
维表层 (DIM):维表层主要包含两部分数据:
-
高基数维度数据:一般是用户资料表、商品资料表类似的资料表。数据量可能是千万级或者上亿级别。
-
低基数维度数据:一般是配置表,比如枚举值对应的中文含义,或者日期维表。数据量可能是个位数或者几千几万。
-
2.2 数据分析师常用的 Hive 功能
作为数据分析师,通常会用到 Hive 的以下功能:
-
数据导入
-
数据查询
-
数据导出
其中,对于数据查询部分,我们将着重学习 Hive 中的 HQL 与 MySQL 的差异:
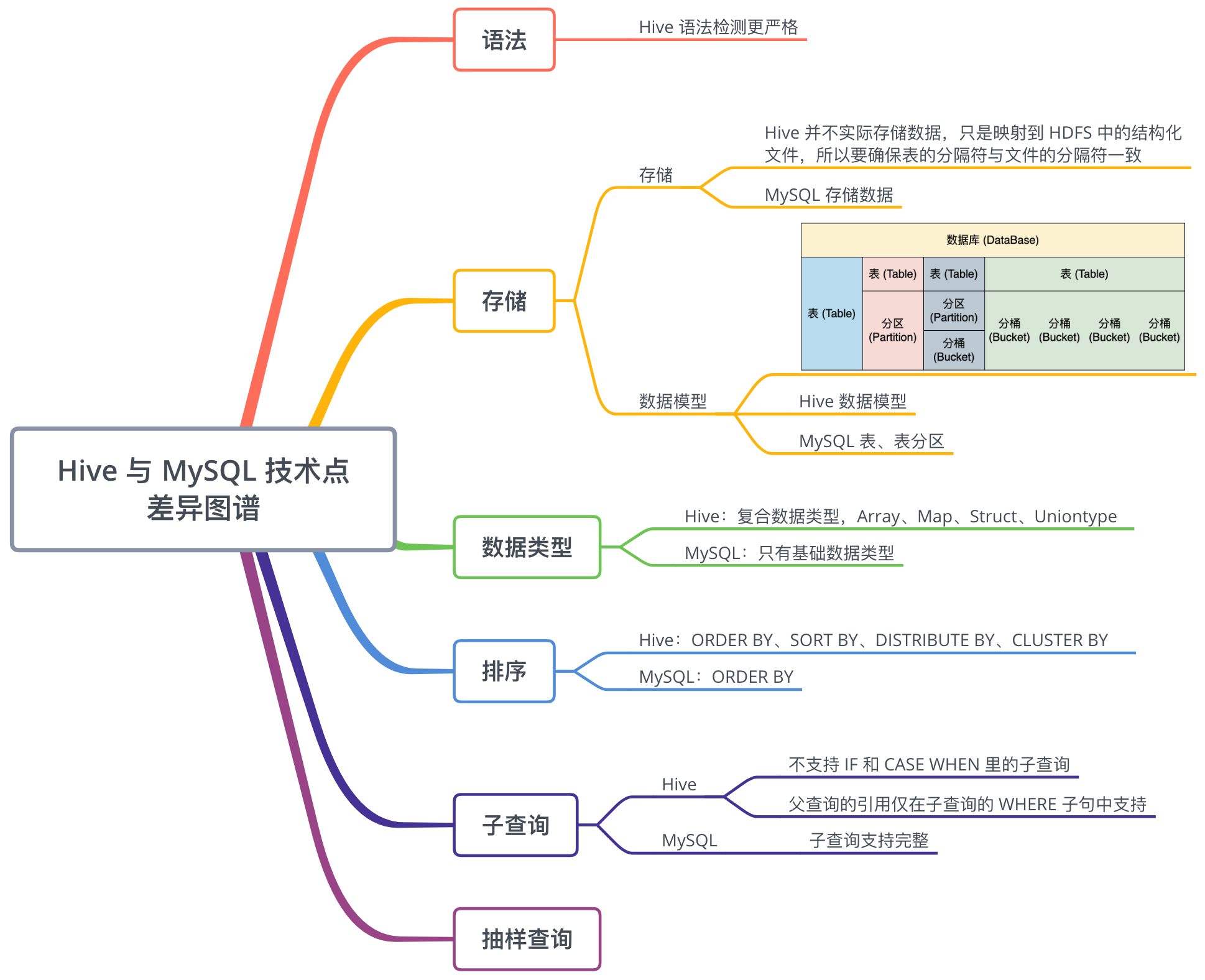
2.3 案例学习
我们还会进行案例学习,模拟实际工作场景(数据量级高达上亿)。
2.3.1 案例 1:用户产品推荐
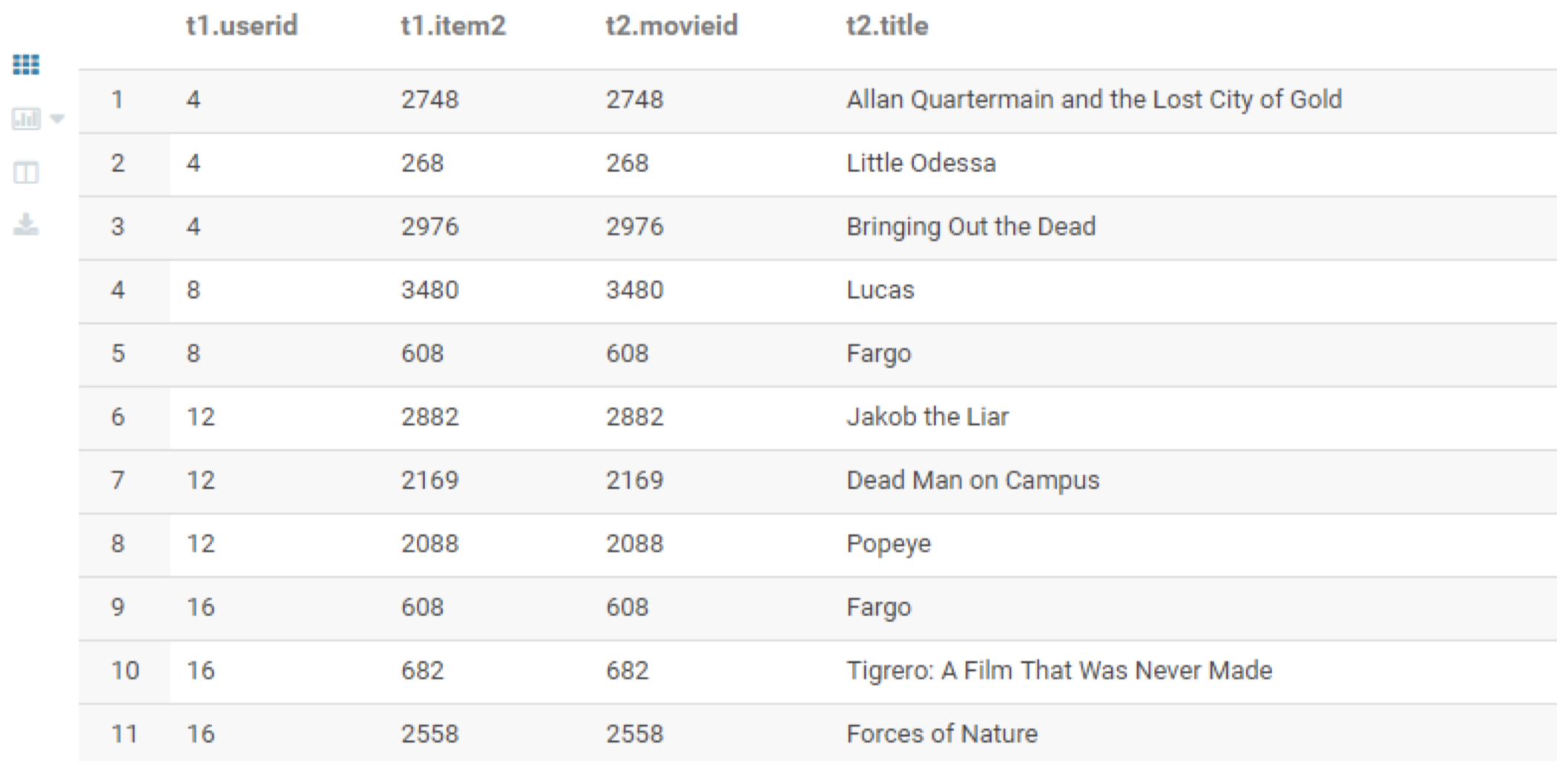
针对每个用户,推荐 3 部电影。
2.3.2 案例 2:用户分层观察产品

对于增长运营部门而言,最关心的是用户池里到底有多少实际用户。某些情况下,即使用户数很多,但实际上很多都已经流失了(只是信息还保留着),或者都是一些不活跃的睡眠用户,而这类用户对于做增长的运营人员来说其实是没有任何意义的。我们希望进入用户池的用户都是活跃的、不流失的用户,因此我们要观察每种用户的趋势变化来及时调整运营方案或者进行人员干预。这里我们绘制了未激活用户、新增用户与睡眠用户的趋势图,从上图中可以看到未激活用户越来越少,这说明这些用户都激活了呢?还是沦为睡眠/流失了呢?从下图中可以看到睡眠用户是呈上升趋势的,说明未激活用户随着时间推移会转变为睡眠用户。
2.4 相关模块
- 第一模块:Hadoop 及 Hive 环境介绍
- 第二模块:Hive 与 Mysql差异点
- 第三模块: 视频网站提高广告曝光量
- 第四模块: 电商用户增长监控
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。 欢迎转载,并请注明来自:YEY 的博客 同时保持文章内容的完整和以上声明信息!