Lecture 07 马尔可夫决策过程(MDP)
不同于之前基于搜索的规划,从这节课开始,我们将学习基于强化学习的规划。我们将从基础的 马尔可夫决策过程(Markov Decision Process,MDP) 开始学习,它是所有强化学习的基础模型,我们可以利用它解决一些强化学习问题。马尔可夫过程松弛了很多之前的经典规划中的假设,之后,我们将学习一些强化学习方法,它们松弛的假设要更多。
本节主要内容如下:
- 动机
- 马尔可夫决策过程(MDP):定义
- 计算:求解 MDP
- 部分可观察 MDP
1. 动机
1.1 学习成果
- 确定在哪些情况下,马尔可夫决策过程(MDP)模型适用于我们的问题。
- 定义 “马尔可夫决策过程”。
- 比较 MDP 与经典规划模型。
- 说明 Bellman 方程(和动态规划)是如何求解 MDP 问题的。
- 应用价值迭代来手动解决小规模 MDP 问题,并编写价值迭代算法的代码来自动解决中等规模的 MDP 问题。
- 根据价值函数构造策略。
- 比较和对比价值迭代与策略迭代。
- 讨论价值迭代和策略迭代算法的优缺点。
1.2 相关阅读
- 任何概率论基础材料。
- Chapter 17 of Artificial Intelligence — A Modern Approach by Russell and Norvig.
- Chapter 4 of Reinforcement Learning: An Introduction, second edition.
1.3 移除假设
经典规划:目前为止,我们已经学习了经典规划。经典规划工具可以在大的搜索空间中快速求解,但是需要如下假设:
- 确定性事件
- 环境改变只是行动导致的结果
- 完美的知识(全知)
- 单个执行器(全能)
在本课程的其余部分,我们将研究如何放松其中的一些假设,我们将从第一个开始:确定性事件。
1.4 马尔可夫决策过程
马尔可夫决策过程(Markov Decision Processes,MDP)移除了确定性事件的假设,而是假设每个行动可能导致多个结果,其中每个结果都有一个相关的概率。
例如:
- 抛一枚硬币有 2 种结果:正面($\frac{1}{2}$)和背面($\frac{1}{2}$)
- 同时掷两个骰子有 12 种结果:2($\frac{1}{36}$), 3($\frac{2}{36}$), 4($\frac{3}{36}$), $\dots$, 12($\frac{1}{36}$)
- 当试图用一个机械臂拾取物体时,可以有 2 种结果:成功($\frac{4}{5}$)和失败($\frac{1}{5}$)
MDP 已成功应用于许多领域的规划中:机器人导航、规划在矿山的哪个区域挖掘矿物、为患者提供治疗、对车辆进行维护计划等。
1.5 典型例子:网格世界
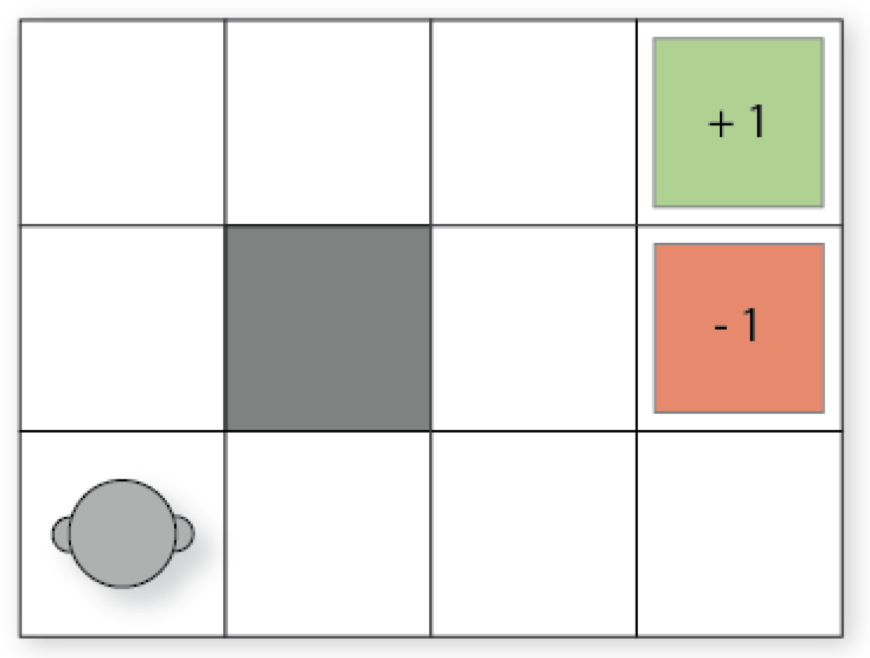
图中网格的左下角是我们的 agent,灰色方块是墙(无法通行),右上角两个带标记的格子给出了回报(reward):到达绿色方块得 $1$ 分(agent 应该到达的目标);到达橙色方块得到一个负的回报 $-1$(agent 应该避开的网格)。
但是,事情的发展可能超出我们的预期 —— 有时行动带来的效应并不是我们希望看到的:
- 如果 agent 尝试向北移动,我们假设有 $80\%$ 的时间(即 $0.8$ 的概率)它会按照计划移动(假设途中没有墙)
- 有 $10\%$ 的时间(即 $0.1$ 的概率),试图向北移动会导致 agent 向西移动(假设途中没有墙)
- 有 $10\%$ 的时间(即 $0.1$ 的概率),试图向北移动会导致 agent 向东移动(假设途中没有墙)
- 如果碰到墙,则 agent 会停在原地。
这和之前的经典规划不同,在经典规划中,当我们执行一个行动时,我们可以确切地知道它将导致的后继状态是什么。但是,在这个例子中,我们并不知道向北移动这一行动将导致的后继状态是什么,我们只知道 3 种可能的结果状态以及它们各自的概率分布,但是我们并不知道最终结果会是其中的哪一个,直到行动已经完成,然后我们可以观察 agent 到底处于哪种后继状态。
上面是马尔可夫决策过程的一个经典例子。MDP 可以应用在很多场景中,例如:我们试图模拟连接网络服务器,$99\%$ 的时间,能够成功连接网络服务器,而 $1\%$ 的时间,会发生连接失败。
2. 马尔可夫决策过程(MDP):定义
2.1 折扣回报马尔可夫决策过程(Discounted Reward MDP)
MDP 是 完全可观测的、概率的 状态模型。MDP 的最常见表述是 折扣回报 马尔可夫决策过程:
- 一个状态空间 $S$
- 初始状态 $s_0\in S$
- 行动 $A(s)\subseteq A$ 可应用于每个状态 $s\in S$
- 转移概率 $P_a(s’\mid s)$,对于 $s\in S$ 和 $a\in A(s)$
- 回报 $r(s,a,s’)$ 可以为正或负,采取行动 $a$ 从状态 $s$ 转换为状态 $s’$
- 一个 折扣因子 $0\le \gamma <1$
和经典规划相比,有哪些不同之处?主要有以下四点:
- 转移函数不再是确定性的。每个行动有 $P_a(s’\mid s)$ 的概率达到状态 $s’$,如果行动 $a$ 执行之前的状态为 $s$。
- 没有目标。每个行动在采取之后都会接受一个回报。回报的值取决于其采用的状态。
- 没有行动代价,它们被建模为负的回报。
- 我们有一个折扣因子。
MDP 可以视为经典规划的一种扩展,它使得我们可以模拟更多的问题,但是也会使得求解过程和经典规划非常不一样。
2.2 折扣回报
折扣因子 $\gamma$ 决定了与当前回报相比,未来回报应该打多少折扣。
例如,你是希望今天就能拿到 100 美元还是一年后拿到 100 美元?我们(人类)通常会对未来回报打折,并为近期回报赋予更高的价值。
假设我们的 agent 按照 $r_1,r_2,r_3,r_4,\dots$ 的顺序接受回报。 如果 $\gamma$ 是折扣因子,那么 折扣回报(discounted reward) 为:
\[\begin{align} V &= r_1+\gamma r_2 + \gamma^2 r_3 +\gamma^3 r_4 + \dots \\ &= r_1 + \gamma(r_2+\gamma(r_3+\gamma(r_4+\dots))) \end{align}\]如果在时间步 $t$ 接受的回报为 $V_t$,那么 $V_t=r_t + \gamma V_{t+1}$
与折扣回报相对的另外一种方式是 累加回报(addictive reward):
\[V = r_1+r_2 + r_3 + r_4 + \dots\]前面 1.5 小节网格世界的例子使用的就是累加回报。注意,在我们用于启发式搜索算法的路径耗散函数中,也隐式地使用了累加性。
折扣因子 $\gamma$ 的取值范围为 $[0,1)$,区间右边没有包含 $1$ 意味着我们总是选择对未来回报打折:当 $\gamma$ 接近 $0$ 时,我们认为未来回报无关紧要;当 $\gamma$ 接近 $1$ 时,未来回报和累加回报完全等价。
2.3 MDP 建模:概率 PDDL
概率 PDDL 是表示 MDP 的一种方法。它通过其他一些构造扩展了 PDDL。其中最相关的是,结果可以与概率联系起来。以下代码描述了 “炸弹和厕所” 问题,其中两个包裹中的一个装有 “炸弹”。“炸弹” 可以通过浸入的方式来疏通厕所,但有 $0.05$ 的概率会使得 “炸弹” 堵塞厕所。
1
2
3
4
5
6
7
8
(define (domain bomb-and-toilet)
(:requirements :conditional-effects :probabilistic-effects)
(:predicates (bomb-in-package ?pkg) (toilet-clogged) (bomb-defused))
(:action dunk-package
:parameters (?pkg)
:effect (and (when (bomb-in-package ?pkg) (bomb-defused))
(probabilistic 0.05 (toilet-clogged))))
2.4 MDP 问题的解:策略
折扣 MDP 的规划问题与经典规划不同,因为行动导致的结果是不确定的。所以,相比经典规划中生成一个行动序列,MDP 生成的是一个 策略 (policy)。
策略 $\pi$ 是一个函数,它告诉 agent 在每种状态下采取哪种行动是最好的选择。策略可以是 确定性的 (deterministic),也可以是 随机的 (stochastic)。
确定性策略(deterministic policy)$\pi:S\to A$ 是一个从状态到动作的映射。它指定了在每种可能的状态下选择哪种行动。因此,如果我们处于状态 $s$,我们的 agent 应该选择由 $\pi(s)$ 所定义的行动。
回到前面网格世界的例子,我们希望从左下角的初始位置移动到右上角的绿色目标方格:
在经典规划中,我们可能得到一个这样的行动序列:
\[[\texttt{move_up},\texttt{move_up},\texttt{move_right}, \texttt{move_right}, \texttt{move_right}]\]但是,在 MDP 中,行动导致的后继状态是不确定的,所以,我们选择用策略将状态映射到行动。
一个网格世界的策略的图表示为:
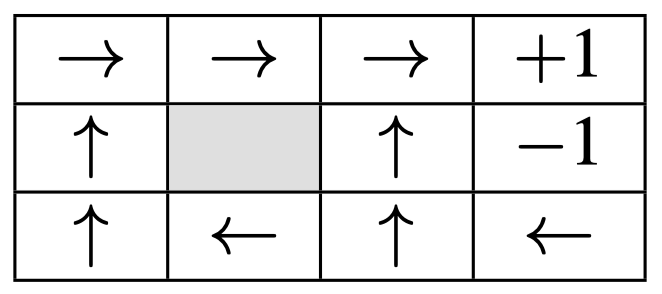
所以,在初始状态(左下角网格),agent 遵循该策略应当向上移动。
当然,agent 无法直接使用图策略,MDP 规划器的输出看上去可能是下面这样的:
- $at(0,0) \; \Longrightarrow \; \texttt{move_up}$
- $at(0,1) \; \Longrightarrow \; \texttt{move_up}$
- $at(0,2) \; \Longrightarrow \; \texttt{move_right}$
- $at(1,0) \; \Longrightarrow \; \texttt{move_left}$
- $at(1,2) \; \Longrightarrow \; \texttt{move_right}$
- $at(2,0) \; \Longrightarrow \; \texttt{move_up}$
- $at(2,1) \; \Longrightarrow \; \texttt{move_up}$
- $at(2,2) \; \Longrightarrow \; \texttt{move_right}$
- $at(3,0) \; \Longrightarrow \; \texttt{move_left}$
然后,agent 可以对其解析并使用:方法是先确定其所处的状态,查看该状态对应的行动,并执行该行动。然后重复该过程,直到达到目标状态。
这种策略被称为 确定性策略,因为尽管行动导致的结果状态是不确定的,但是对于同一状态,我们始终采取一样的行动,即 $\pi(s)\to A$。例如,当 agent 位于 $(0,0)$ 处时,我们始终选择 $\texttt{move_up}$。
相应地,另外一种被称为 随机性策略,即 $\pi(s,a)\in [0, 1]$,对于同一种状态,我们可能以不同的概率采取不同的行动。
随机性策略(stochastic policy)$\pi:S\times A \to \mathbb R$ 指定了 agent 应当选择行动的概率分布。直观地,$\pi(s,a)$ 指定了在状态 $s$ 下执行行动 $a$ 的概率。
为了执行随机策略,我们可以简单地采取具有最大 $\pi(s,a)$ 的行动。但是,在许多域中,更好的做法是根据概率分布来选择一个行动;也就是说,我们以概率的方式选择行动,使得某个行动被选择的概率与该行动本身相应的概率成正比。
在本课程中,我们将仅关注确定性策略,但是随机策略在 MDP 问题中也有着很重要的位置。
2.5 折扣回报 MDP 策略的期望价值
对于折扣回报 MDP,最优解将最大化从初始状态 $s_0$ 开始的 期望折扣累积回报(expected discounted accumulated reward)。但是,什么是期望折扣累积回报呢?
在折扣回报 MDP 中,从 $s$ 开始的 期望折扣回报(expected discounted reward)为:
\[V^{\pi}(s)=E_{\pi}\left[\sum_i \gamma^i r(a_i,s_i) \;\bigg \vert \; s_0=s,a_i=\pi(s_i) \right]\]因此,$V^{\pi}(s)$ 定义了从状态 $s$ 开始遵循策略 $\pi$ 的期望价值。
所以,对于我们网格世界的例子,假设只有 $-1$ 和 $+1$ 状态具有回报,期望价值为:
- $\gamma^5 \times 1\times (0.8^5)$ (最优行动)
- $\gamma^7 \times 1\times (0.8^7)$ (只有第一步行动没有达到预期结果,即向左或者向右移动了)
- $\dots$
3. 计算:求解 MDP
3.1 贝尔曼方程(折扣回报 MDP)
贝尔曼方程(Bellman equations),以 Richard Bellman 的姓命名,描述了一个策略达到最优需要满足的条件。它将 MDP 推广到其他问题,但是这里,我们只关注 MDP 问题。
对于折扣回报 MDP,其贝尔曼方程被递归地定义为:
\[V(s)=\max \limits_{a\in A(s)}\sum_{s'\in S} P_a(s'\mid s)[r(s,a,s')+ \gamma V(s')]\]因此,如果对于所有状态 $s$,$V(s)$ 描述了在不确定 / 无限范围内以最高回报采取行动的总折扣回报,则 $V$ 是最优的。
一次行动的回报是:该行动产生的所有状态的即时回报与它们的折扣未来回报之和;乘以该行动发生的概率。
3.2 贝尔曼方程 —— 替代公式
有时,使用所谓的 $Q$-函数 对贝尔曼方程的描述略有不同。
如果 $V(s)$ 是处于状态 $s$ 并根据我们的策略最优执行的期望价值,那么我们也可以描述处于状态 $s$,并选择行动 $a$ 然后根据我们的策略最优执行的 $Q$-值。
对于折扣回报 MDP,贝尔曼方程被递归地定义为:
\[Q(s,a)=\sum_{s'\in S} P_a(s'\mid s)[r(s,a,s')+ \gamma V(s')]\]$Q(s,a)$ 只是贝尔曼方程中 $\max$ 内部的表达式,它表示在状态 $s$ 采取行动 $a$ 获得的期望回报,即该行动的 质量(Quality)。使用此方法,有时你可能会看到贝尔曼方程被定义为:
\[V(s)=\max \limits_{a\in A(s)} Q(s,a)\]这两个定义是等价的,但是我们可以用两种方式定义它们。但是,在后面的强化学习中,我们将更显式地使用 $Q$ 函数。
3.3 利用贝尔曼方程:价值迭代
价值迭代(Value Iteration)寻找最优价值函数 $V^*$ 迭代求解贝尔曼方程方程,它使用了以下算法:
价值迭代算法:
- 对于 $S$ 中的所有状态 $s$,将 $V_0$ 设为任意价值函数(例如:$V_0=0$)
- $\mathbf {while}\; \textit{diff}>=\epsilon$:
$\quad$a. $\mathbf {for}\;\text{each} \; s\; \text{in}\; S\;\mathbf {do}$:
$\quad \qquad$i. $V_{t+1}(s):= \max \limits_{a\in A(s)} \sum_{s’\in S} P_a(s’\mid s)[r(s,a,s’)+ \gamma V_t(s’)]$ - 选择策略
注意:
- 将 $V_0$ 设为任意价值函数;例如:$V_0=0$ 对于所有的 $s$。
- 将 $V_{i+1}$ 设为将贝尔曼方程 等式右边 的 $V$ 用 $V_i$ 代替的结果:
随着迭代过程的继续,它将以指数形式快速收敛到最优策略。
定理:随着迭代次数 $i \to \infty$,价值函数 $V_i \to V^*$。即给定无限迭代次数,价值函数将达到最优。
每次迭代的时间复杂度为 $O(|S|^2|A|)$。在每次迭代中,我们在一个外部循环中迭代 $S$ 中的所有状态,并且在每个外部循环迭代中,我们都需要迭代所有状态 $\sum_{s’\in S}$,这意味着 $|S|^2$ 次迭代。但是,在每次外部循环迭代中,我们都需要计算每个行动的价值以找出其最大值。
3.4 实践中的价值迭代
价值迭代将渐近收敛于最优价值函数 $V^*$,但在实践中,当 残差 $R=\max_s |V_{i+1}(s)-V_i(s)|$ 达到某个预定义的阈值 $\epsilon$ 时,该算法将停止。即,两次迭代之间的价值的最大变化是 “足够小”。
由此产生的贪婪策略 $\pi_V$ 的 损失 为 $\frac{2\gamma R}{1-\gamma}$。
显然,我们可以通过一次更新许多状态的价值来轻松实现价值迭代的并行化:时间步 $t+1$ 的状态的价值仅取决于时间步 $t$ 的其他状态的价值。
现在我们可以很容易地定义一个策略:在状态 $s$ 中,给定 $V$,选择具有最高期望回报的行动。
3.5 价值迭代的例子:网格世界
假设折扣因子 $\gamma=0.9$。
在迭代开始之前,所有网格的价值都被初始化为 $V_0=0$,在第一次迭代之后,绿色目标网格价值被设为 $+1$,而橙色网格价值设为 $-1$。假设现在是第 2 次迭代,我们想计算绿色目标网格左边相邻的网格的价值。当机器人位于该网格时,和之前一样,当它试图朝某个方向移动时,它有 $0.8$ 的概率向该方向移动(例如:向右移动),$0.1$ 的概率向该方向逆时针 $90^{\,\circ}$ 移动(例如:向上移动),以及 $0.1$ 的概率向该方向顺时针 $90^{\,\circ}$ 移动(例如:向下移动),如果碰到墙壁则停在原位 (即 $s’=s$)。
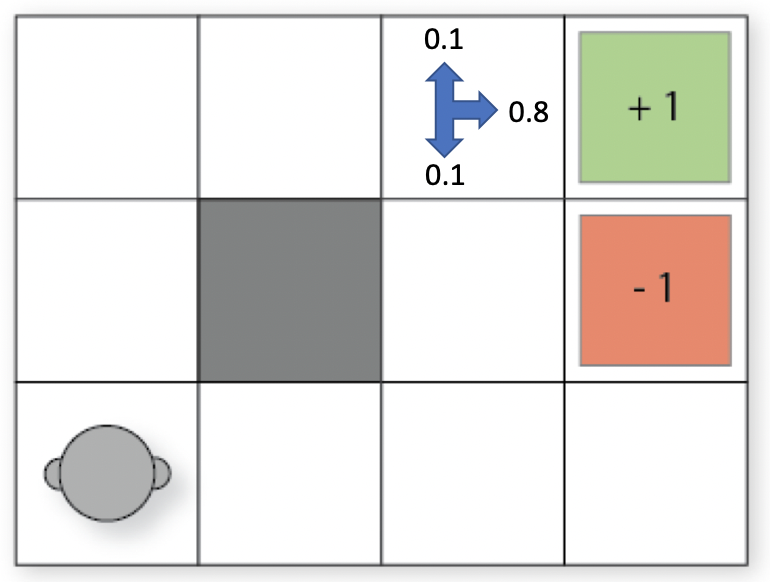
网格 $(2,2)$ 在第 2 次迭代中的价值 $V_2$:
- 向右移动:$0.8\times(0+0.9\times 1)+0.1\times(0+0.9\times 0)+0.1\times(0+0.9\times 0)=0.72$
- 向上移动:$0.8\times(0+0.9\times 0)+0.1\times(0+0.9\times 0)+0.1\times(0+0.9\times 1)=0.09$
- 向下移动:$0.8\times(0+0.9\times 0)+0.1\times(0+0.9\times 1)+0.1\times(0+0.9\times 0)=0.09$
- 向左移动:$0.8\times(0+0.9\times 0)+0.1\times(0+0.9\times 0)+0.1\times(0+0.9\times 0)=0$
现在,我们得到了 agent 在 $(2,2)$ 网格的所有行动的价值,我们选择其中的最大值作为该网格在此次迭代中的价值,即 $V_{t+1}=V_2=0.72$。
同理,按此方法计算出第 2 次迭代中所有网格的价值,可知其余可执行移动行动的网格价值在此次迭代中均为 0。
现在,让我们来看一下网格 $(2,2)$ 在第 3 次迭代中的价值 $V_3$:
- 向右移动:$0.8\times(0+0.9\times 1)+0.1\times(0+0.9\times \color{red}{0.72})+0.1\times(0+0.9\times 0)=0.78$
注意:因为向右移动时有 $0.1$ 的概率向上移动,而网格 $(2,2)$ 上方是墙壁,这种情况下移动后的状态 $s’$ 仍然处于 $(2,2)$,而网格 $(2,2)$ 在前一次(第 2 次)的迭代价值为 $0.72$,所以对于上面式子中的第二个加项,我们用 $0.72$ 替换之前的 $0$。 - 向上移动:$0.8\times(0+0.9\times 0.72)+0.1\times(0+0.9\times 0)+0.1\times(0+0.9\times 1)=0.61$
- 向下移动:$0.8\times(0+0.9\times 0)+0.1\times(0+0.9\times 1)+0.1\times(0+0.9\times 0)=0.09$
- 向左移动:$0.8\times(0+0.9\times 0)+0.1\times(0+0.9\times 0)+0.1\times(0+0.9\times 0.72)=0.06$
同样,我们选择其中的最大值作为网格 $(2,2)$ 在此次迭代中的价值,即 $V_{t+1}=V_3=0.78$。
以此类推,我们可以得到:
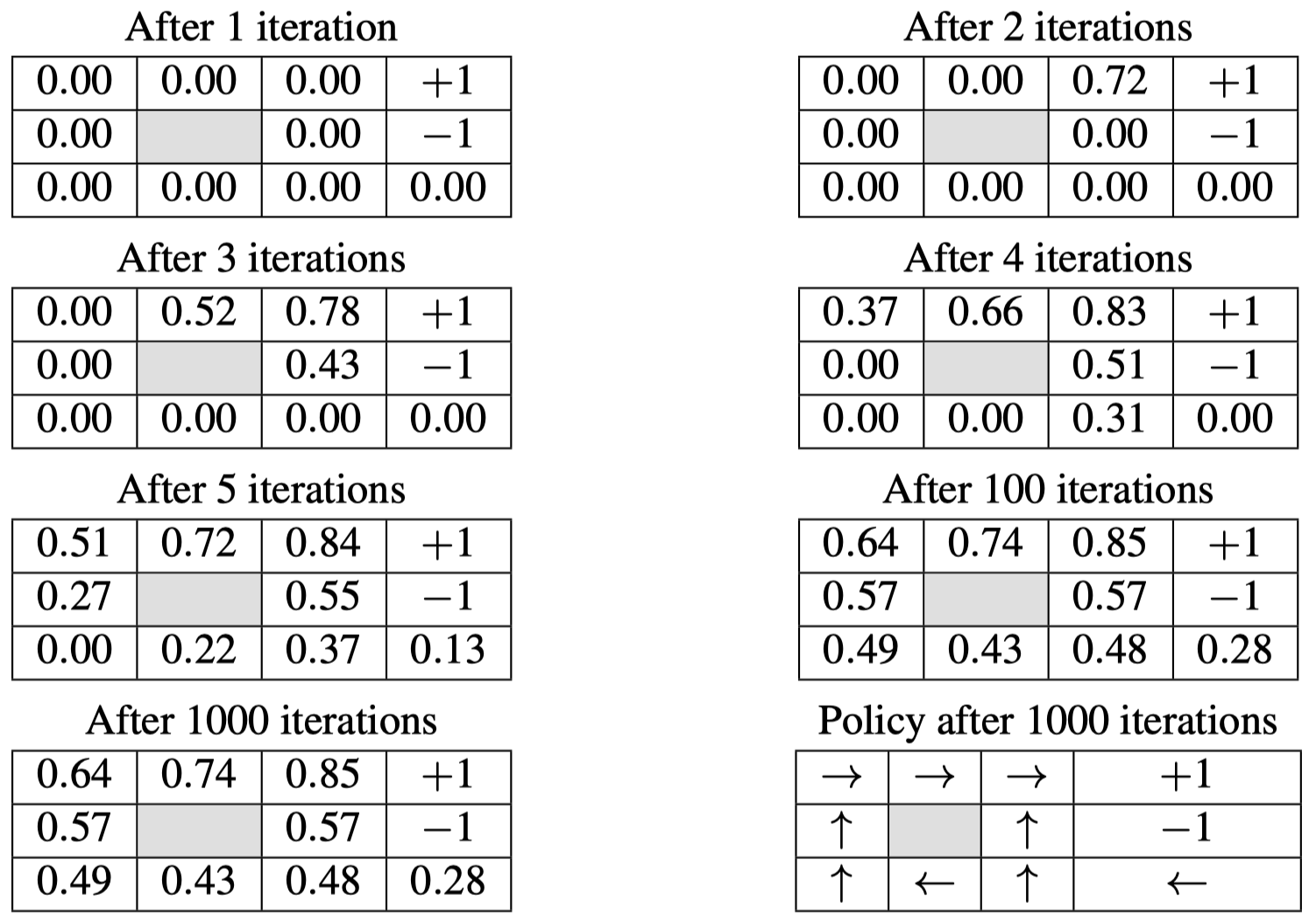
可以看到,在迭代 $100$ 次之后,各个网格状态的迭代价值已经收敛了。在最后我们得到的策略图中,对于每个网格状态,我们总是选择朝着价值最大的相邻网格移动。
示例:http://www.cs.ubc.ca/~poole/demos/mdp/vi.html
3.6 决定如何行动
给定一个(近似)最佳策略,那么我们应该如何在给定状态下选择行动?很简单:我们可以选择能够最大化 期望效用(expected utility)的行动。因此,给定一个价值函数 $V$,我们可以使用以下方法选择具有最高期望回报的行动:
\[\mathop{\operatorname{arg\,max}}\limits_{a\in A(s)}\sum_{s'\in S}P_a(s'\mid s)[r(s,a,s') + \gamma V(s')]\]这被称为 策略提取(policy extraction),因为它为一个价值函数(或者 $Q$-函数)提取了一个策略。这可以在运行时动态计算。
或者,给定一个 $Q$-函数而非一个价值函数,我们可以使用:
\[\mathop{\operatorname{arg\,max}}\limits_{a\in A(s)} Q(s,a)\]这比使用价值函数更容易决定,因为我们不需要对可能的输出状态集进行求和。
3.7 策略迭代和策略评估
求解 MDP 的另一种常见方法是使用 策略迭代(policy iteration)—— 它是一种类似于价值迭代的方法。价值迭代是在价值函数上进行迭代,而策略迭代是对策略本身进行迭代,在每次迭代中创建一个严格改进的策略(除非迭代的策略已经是最优策略)。
策略迭代首先从某个(非最佳)策略开始(例如:随机策略),然后在给定该策略的情况下,计算 MDP 中每个状态的价值 —— 此步骤称为 策略评估(policy evaluation)。然后,它通过计算来自该状态适用的每个行动的期望回报来为每个状态的策略本身进行更新。
这里的基本思想是,策略评估要比价值迭代更容易计算,因为我们当前拥有的策略已经限定了需要考虑的行动的集合。
3.8 策略评估
从状态 $s$ 到目标状态,策略 $\pi$ 的 期望回报 $V^{\pi}(s)$ 是该策略所定义的可能的状态序列的回报乘以它们在给定策略 $\pi$ 下的概率的加权平均。
但是,期望回报 $V^{\pi}(s)$ 也可以表示为以下方程的解:
\[V^{\pi}(s)=\sum_{s'\in S}P_a(s'\mid s)[r(s,a,s') + \gamma V^{\pi}(s')]\]其中,$a=\pi(s)$,并且对于目标状态,$V^{\pi}(s)=0$。
该线性方程可以利用 MATLAB 求得解析解,也可以通过其他程序求解,这不是我们所关心的问题。
- 最优期望回报(optimal expected reward):$V^*(s)=\max_{\pi}V^{\pi}(s)$
- 最优策略(optimal policy):$\pi^*=\mathop{\operatorname{arg\,max}}_{\pi}V^{\pi}(s)$。
3.9 策略迭代
令 $Q^{\pi}(a,s)$ 为从状态 $s$ 开始先执行 行动 $a$,然后再执行策略 $\pi$ 的期望回报:
\[Q^{\pi}(a,s)=\sum_{s'\in S}P_a(s'\mid s)[r(s,a,s') + \gamma V^{\pi}(s')]\]当 $Q^{\pi}(a,s) < Q^{\pi}(\pi(s),s)$ 时,通过将 $\pi(s)$ 替换为 $a$ 是一种对策略 $\pi$ 的严格改进。
策略迭代通过一系列的策略评估和改进来计算 $\pi^*$:
- 从任意策略 $\pi$ 开始
- 为所有的状态 $s$ 计算 $V^{\pi}(s)$(策略评估)
- 通过设置 $\pi(s):=\mathop{\operatorname{arg\,max}}_{a\in A(s)}Q^{\pi}(a,s)$ 来改进 $\pi$(策略改进)
- 如果第 3 步中,策略发生了改变,那么回到步骤 2,否则结束。
该算法在有限次数的迭代后,在结束时会得到一个最优策略 $\pi^*$,因为策略的数量是有限的,以 $O(|A|^{|S|})$ 为界,这一点和价值迭代不同,价值迭代理论上要求无限的迭代次数。
但是,每次的迭代代价为 $O(|S|^2|A|+|S|^3)$。经验证据表明,最有效的方法取决于所求解的特定 MDP 模型。
3.10 维度诅咒
因此,使用这些算法求解 MDP 是状态空间大小的多项式,但是如果我们使用类似 PDDL 的语言来表示我们的问题,它将是变量数量的指数级。即,如果有 $N$ 个变量,每个变量都是一个布尔值,那么将有 $2^N$ 种状态。价值迭代和策略迭代要求我们维持一个大小为 $|2^N|$ 的向量。
问题:我们可以做得更好吗?
答案:是的,使用函数逼近,我们将在后面的课程中看到。
4. 部分可观察 MDP
4.1 部分可观察 MDP
MDP 假定 agent 始终都能准确知道其所处的状态 —— 问题是完全可观察到的。但是,对于许多其他任务来说,情况并非如此;例如,在地震区搜索幸存者的无人驾驶飞机无法确定幸存者的位置;一个纸牌玩家 agent 不会知道对手的手牌等等。
部分可观察 MDP(POMDP)放松了关于完全可观察的假设。POMDP 定义为:
- 状态 $s\in S$
- 目标状态集合 $G\subseteq S$
- 行动 $A(s)\subseteq A$
- 转移概率 $P_a(s’\mid s)$,对于 $s\in S$,$a\in A(s)$
- 初始 信念状态(belief state)$b_0$
- 回报函数 $r(s,a,s’)$
- 一个 传感器模型(sensor model),由概率 $P_a(o\mid s),\;o\in Obs$ 给出
4.2 求解 POMDP(直观概述)
求解 POMDP 与求解 MDP 非常相似。实际上,它们适用于相同的算法。唯一的不同是,我们将 POMDP 问题视为具有新状态空间的标准 MDP 问题:每个状态都是集合 $S$ 上的 概率分布。因此,POMDP 的每个状态都是一个 信念状态,它定义了 $S$ 中每个状态的概率。
与 MDP 一样,POMDP 的解是将信念状态映射为行动的策略。
最优策略将最小化从 $b_0$ 到 $G$ 的期望回报。
我们不会在这里对此详细展开。但是,POMDP 显然是 MDP 的一种泛化,与标准 MDP 相比,它们对自动规划的影响更大。
5. 总结
我们介绍了马尔可夫决策过程(MDP)。它们与经典规划的不同之处在于,行动可以产生不止一种可能的结果。每个结果都有其关联的概率。
有两种用于穷尽计算最优策略的求解方法:价值迭代和策略迭代。它们都基于动态规划 —— 具体来说,它们使用贝尔曼方程迭代地对一个非最优解进行改进。
我们还可以使用启发式搜索,但不会产生一般性的解 —— 仅适用于从搜索的初始状态可以到达的状态。
部分可观察 MDP 通过接受对环境不完全可观察的描述来泛化 MDP。求解这类问题用到的技术与 MDP 相同,只是在一个更大的搜索空间上。
下一步是什么? 如何使用 强化学习 来 学习 行动结果的概率。
下节内容:蒙特卡洛树搜索:利用和探索的权衡
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。 欢迎转载,并请注明来自:YEY 的博客 同时保持文章内容的完整和以上声明信息!