Lecture 06 数据读取机制:DataLoader 与 Dataset
本节课我们将学习 PyTorch 中的数据读取机制:Dataloader 与 Dataset。这里,我们将通过一个人民币二分类的例子来学习它们。
1. 人民币二分类
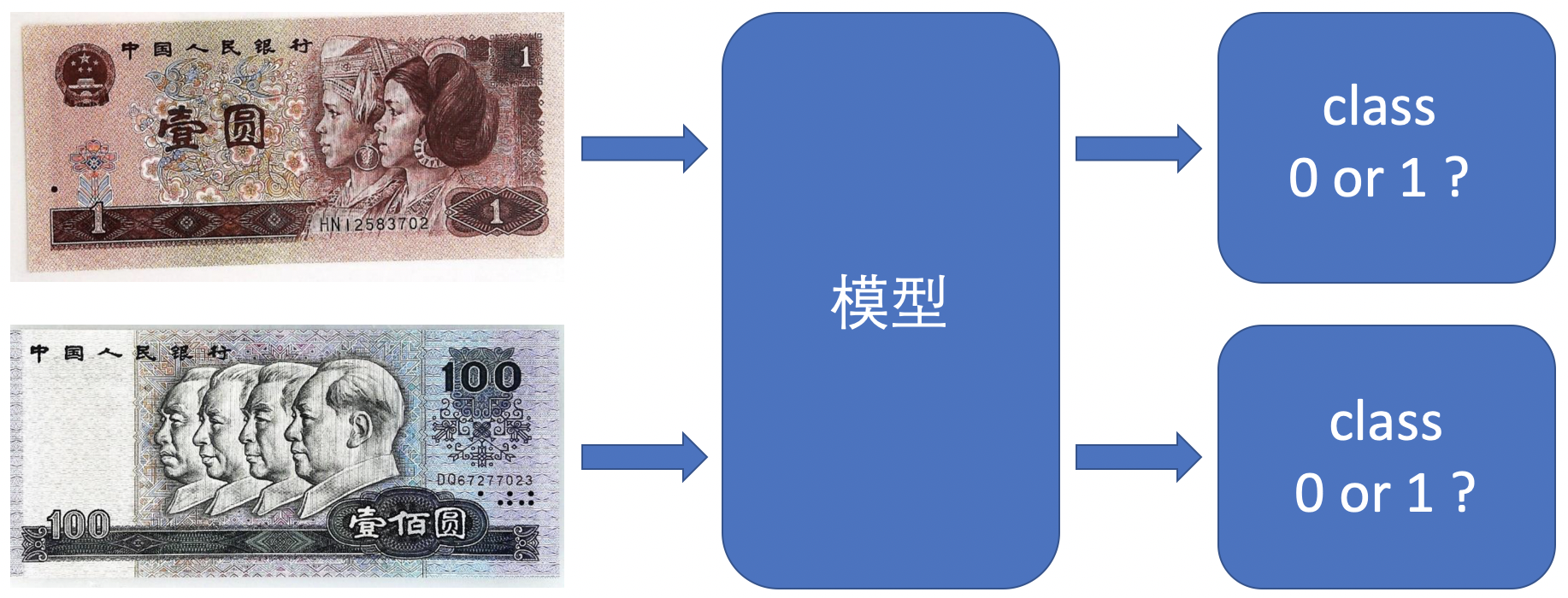
任务:训练一个分类模型,使得其能够对第四套人民币中的 1 元和 100 元面额的纸币进行分类。
回顾一下上节课中学习的机器学习的 5 个步骤:

其中,数据模块又可以分为以下子模块:
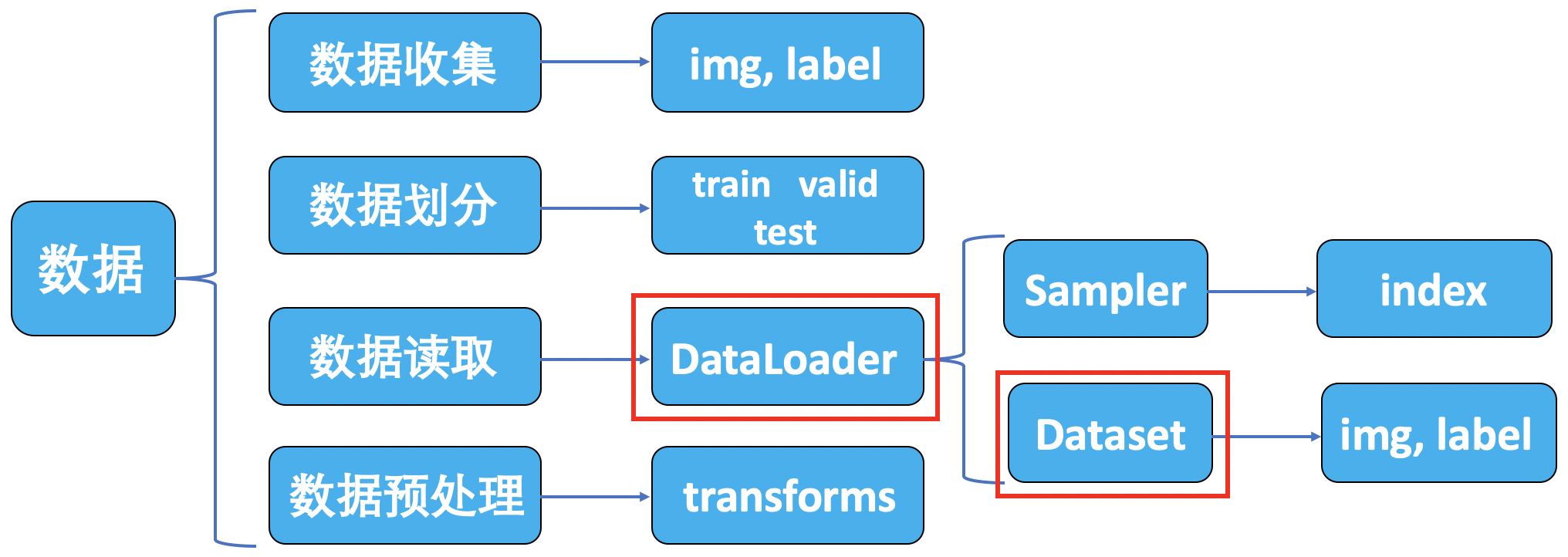
2. DataLoader 与 Dataset
2.1 DataLoader
torch.utils.data.DataLoader
功能:构建可迭代的数据装载器。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
DataLoader(
dataset,
batch_size=1,
shuffle=False,
sampler=None,
batch_sampler=None,
num_workers=0,
collate_fn=None,
pin_memory=False,
drop_last=False,
timeout=0,
worker_init_fn=None,
multiprocessing_context=None
)
主要参数:
dataset:Dataset类,决定数据从哪读取及如何读取。batchsize:批大小。num_works:是否多进程读取数据。shuffle:每个epoch是否乱序。drop_last:当样本数不能被batchsize整除时,是否舍弃最后一批数据。
相关概念:
- Epoch:所有训练样本都已输入到模型中,称为一个 epoch。
- Iteration:一批样本输入到模型中,称之为一个 iteration。
- Batchsize:批大小,决定一个 epoch 有多少个 iteration。
例如:
-
训练样本:80
Batchsize:8
1 epoch = 10 iteration
-
训练样本:87
Batchsize:8
drop_last = True:1 epoch = 10 iterationdrop_last = False:1 epoch = 11 iteration
2.2 Dataset
torch.utils.data.Dataset
功能:Dataset 抽象类,所有自定义的 Dataset 需要继承它,并重写 __ getitem __() 方法。
1
2
3
4
5
6
7
class Dataset(object):
def __getitem__(self, index):
raise NotImplementedError
def __add__(self, other):
return ConcatDataset([self, other])
主要参数:
getitem:接收一个索引,返回一个样本。
2.3 PyTorch 的数据读取机制
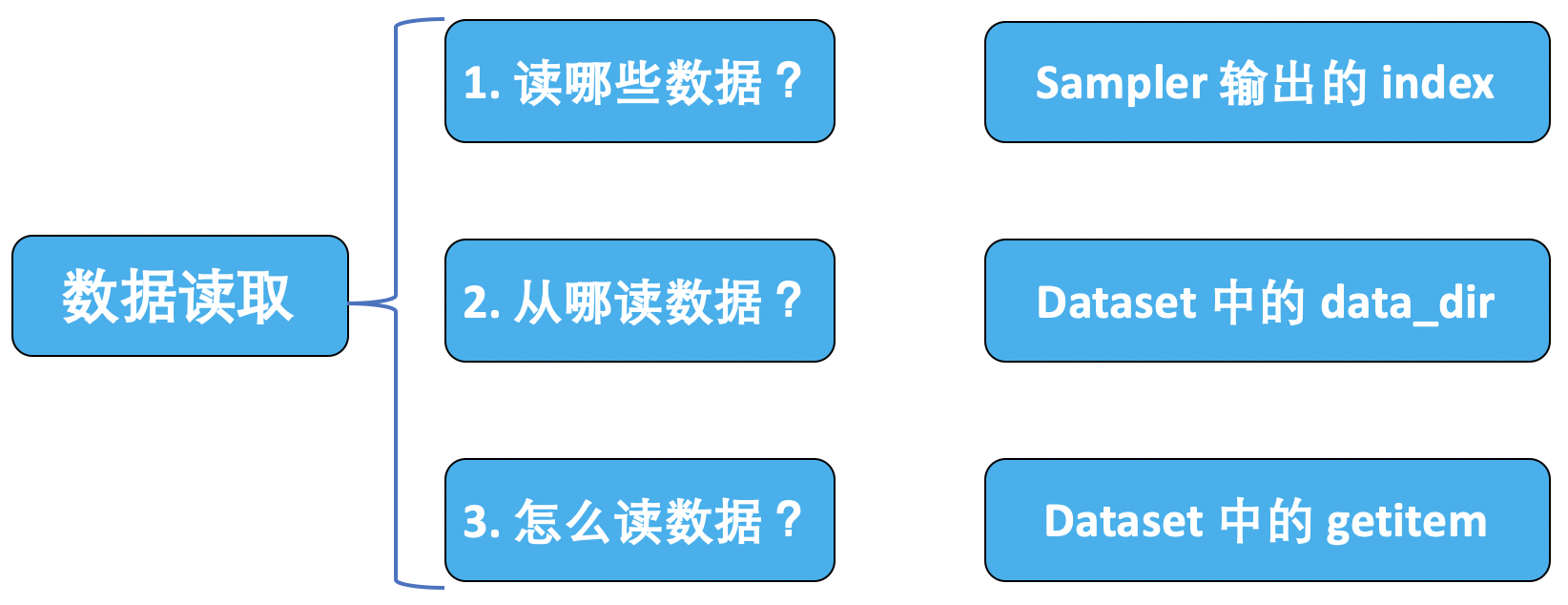
将数据集划分为训练集、验证集和测试集:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
import os
import random
import shutil
def makedir(new_dir):
if not os.path.exists(new_dir):
os.makedirs(new_dir)
if __name__ == '__main__':
random.seed(1)
# 人民币图片数据所在目录:"../../data/RMB_data"
dataset_dir = os.path.join("..", "..", "data", "RMB_data")
# 划分数据集所在目录:"../../data/rmb_split"
split_dir = os.path.join("..", "..", "data", "rmb_split")
# 训练集目录:"../../data/rmb_split/train"
train_dir = os.path.join(split_dir, "train")
# 验证集目录:"../../data/rmb_split/valid"
valid_dir = os.path.join(split_dir, "valid")
# 测试集目录:"../../data/rmb_split/test"
test_dir = os.path.join(split_dir, "test")
train_pct = 0.8
valid_pct = 0.1
test_pct = 0.1
for root, dirs, files in os.walk(dataset_dir):
# os.walk() 方法用于通过在目录树中游走输出在目录中的文件名,向上或者向下,
# 返回一个三元元组 (root, dirs, files):
# root:当前正在遍历的这个文件夹的本身的地址,这里为
# "/Users/andy/PycharmProjects/hello_pytorch/data/RMB_data"
# dirs:是一个 list ,内容是该文件夹中所有的目录的名字(不包括子目录),这里为 ["1", "100"]
# files:同样是 list , 内容是该文件夹中所有的文件(不包括子目录),这里为 []
for sub_dir in dirs:
# os.listdir() 方法用于返回指定的文件夹包含的文件或文件夹的名字的列表
# 这里返回的是目录 "1" 或 "100" 下的文件或文件夹名字的列表
imgs = os.listdir(os.path.join(root, sub_dir))
# 仅保留列表中文件名后缀为 '.jpg' 的元素,即图片数据
imgs = list(filter(lambda x: x.endswith('.jpg'), imgs))
random.shuffle(imgs)
img_count = len(imgs)
train_point = int(img_count * train_pct)
valid_point = int(img_count * (train_pct + valid_pct))
for i in range(img_count):
if i < train_point:
out_dir = os.path.join(train_dir, sub_dir)
elif i < valid_point:
out_dir = os.path.join(valid_dir, sub_dir)
else:
out_dir = os.path.join(test_dir, sub_dir)
makedir(out_dir)
target_path = os.path.join(out_dir, imgs[i])
src_path = os.path.join(dataset_dir, sub_dir, imgs[i])
# 拷贝文件和权限,这里表示将原始数据集中的图片文件拷贝到目标路径文件名下
shutil.copy(src_path, target_path)
print('Class: {}, train: {}, valid :{}, test: {}'.format(sub_dir, \
train_point, valid_point-train_point, img_count-valid_point))
输出结果:
1
2
Class: 1, train: 80, valid :10, test: 10
Class: 100, train: 80, valid :10, test: 10
数据读取:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
import os
import random
import numpy as np
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
import torchvision.transforms as transforms
import torch.optim as optim
from matplotlib import pyplot as plt
from model.lenet import LeNet
from tools.my_dataset import RMBDataset
def set_seed(seed=1):
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
set_seed() # 设置随机种子
rmb_label = {"1": 0, "100": 1}
# 参数设置
MAX_EPOCH = 10
BATCH_SIZE = 16
LR = 0.01
log_interval = 10
val_interval = 1
# ========================= step 1/5 数据 ===============================
split_dir = os.path.join("..", "..", "data", "rmb_split")
train_dir = os.path.join(split_dir, "train")
valid_dir = os.path.join(split_dir, "valid")
norm_mean = [0.485, 0.456, 0.406]
norm_std = [0.229, 0.224, 0.225]
train_transform = transforms.Compose([
# 将图像缩放到 32*32 大小
transforms.Resize((32, 32)),
# 对图像进行随机裁剪(数据增强)
transforms.RandomCrop(32, padding=4),
# 将图片转成张量形式,并进行归一化操作,把像素值区间从 0~255 归一化到 0~1
transforms.ToTensor(),
# 数据标准化,均值为 0,标准差为 1:output = (input - mean) / std
transforms.Normalize(norm_mean, norm_std),
])
valid_transform = transforms.Compose([
transforms.Resize((32, 32)),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
# 构建 MyDataset 实例
train_data = RMBDataset(data_dir=train_dir, transform=train_transform)
valid_data = RMBDataset(data_dir=valid_dir, transform=valid_transform)
# 构建 DataLoader
train_loader = DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
valid_loader = DataLoader(dataset=valid_data, batch_size=BATCH_SIZE)
RMBDataset 类实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
import os
import random
from PIL import Image
from torch.utils.data import Dataset
random.seed(1)
rmb_label = {"1": 0, "100": 1}
class RMBDataset(Dataset):
def __init__(self, data_dir, transform=None):
"""
rmb 面额分类任务的 Dataset
:param data_dir: str, 数据集所在路径
:param transform: torch.transform, 数据预处理
"""
self.label_name = {"1": 0, "100": 1}
self.data_info = self.get_img_info(data_dir) # data_info 存储所有t图片路径和标签,在 DataLoader 中通过 index 读取样本
self.transform = transform
def __getitem__(self, index):
path_img, label = self.data_info[index]
img = Image.open(path_img).convert('RGB') # 0~255
if self.transform is not None:
img = self.transform(img) # 在这里做 transform,转为 tensor 等等
return img, label
def __len__(self):
return len(self.data_info)
@staticmethod
def get_img_info(data_dir):
data_info = list()
for root, dirs, _ in os.walk(data_dir):
# 遍历类别
for sub_dir in dirs:
img_names = os.listdir(os.path.join(root, sub_dir))
img_names = list(filter(lambda x: x.endswith('.jpg'), img_names))
# 遍历图片
for i in range(len(img_names)):
img_name = img_names[i]
path_img = os.path.join(root, sub_dir, img_name)
label = rmb_label[sub_dir]
data_info.append((path_img, int(label)))
return data_info
PyTorch 中的 DataLoader 工作原理:
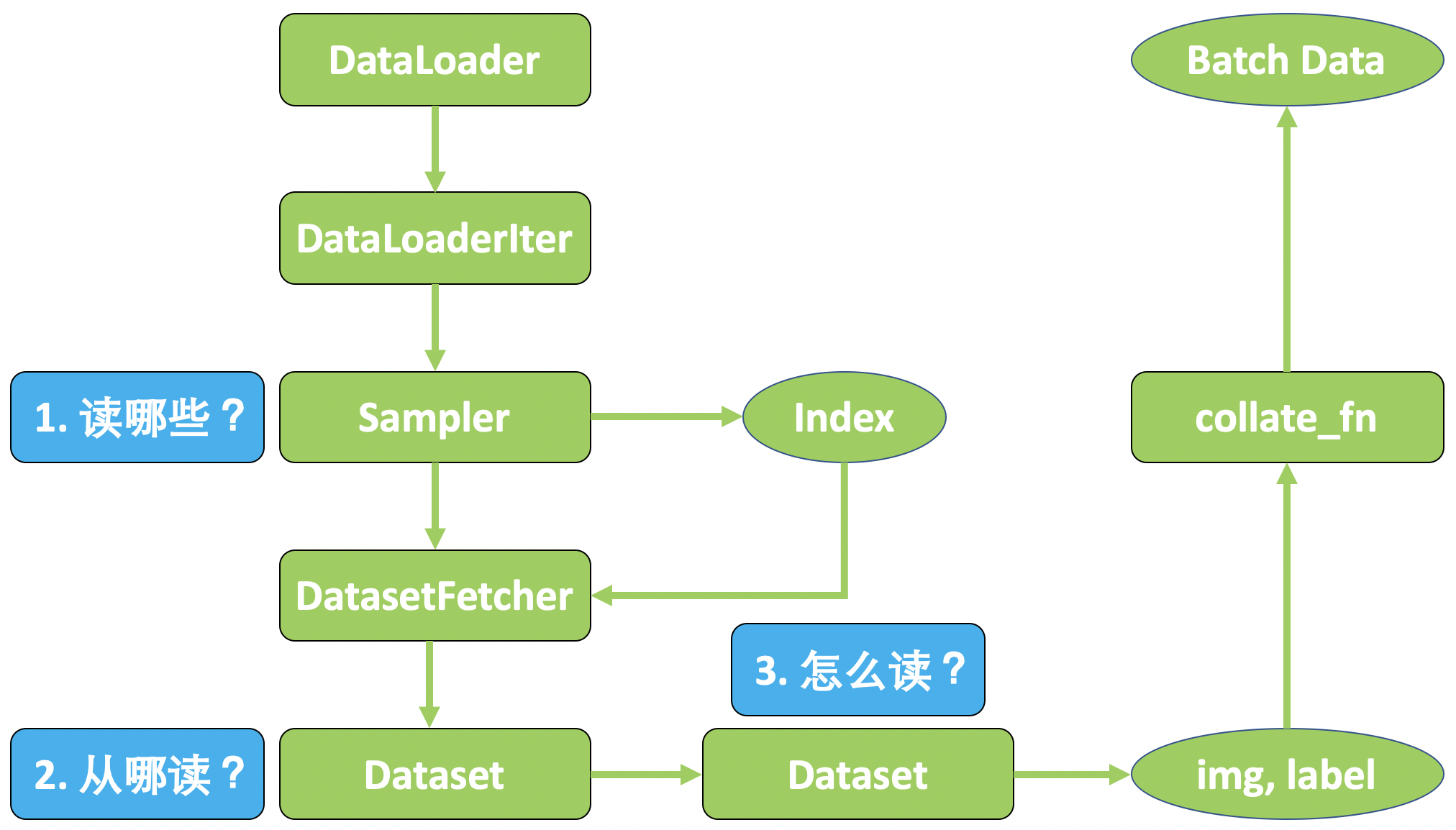
3. 总结
本节课介绍了 PyTorch 的数据读取机制,通过一个人民币分类实验来学习 PyTorch 是如何从硬盘中读取数据的,并且深入学习数据读取过程中涉及到的两个模块 Dataloader 与 Dataset。
下节内容:数据预处理 transforms 模块机制
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。 欢迎转载,并请注明来自:YEY 的博客 同时保持文章内容的完整和以上声明信息!