Lecture 17 优化器 (一)
前两节课中,我们学习了损失函数的概念以及 PyTorch 中的一系列损失函数方法,我们知道了损失函数的作用是衡量模型输出与真实标签之间的差异。在得到了 loss 函数之后,我们应该如何去更新模型参数,使得 loss 逐步降低呢?这正是优化器的工作。本节课我们开始学习优化器模块。
1. 什么是优化器
在学习优化器模块之前,我们先回顾一下机器学习模型训练的 5 个步骤:

我们看到,优化器是第 4 个模块,那么它的作用是什么呢?我们知道,在前一步的损失函数模块中,我们会得到一个 loss 值,即模型输出与真实标签之间的差异。有了 loss 值之后,我们一般会采用 PyTorch 中的 AutoGrid 自动梯度求导模块对模型中参数的梯度进行求导计算,之后优化器会拿到这些梯度值并采用一些优化策略去更新模型参数,使得 loss 值下降。因此,优化器的作用就是利用梯度来更新模型中的可学习参数,使得模型输出与真实标签之间的差异更小,即让 loss 值下降。
PyTorch 的优化器:管理 并 更新 模型中可学习参数 (权值或偏置) 的值,使得模型输出更接近真实标签。
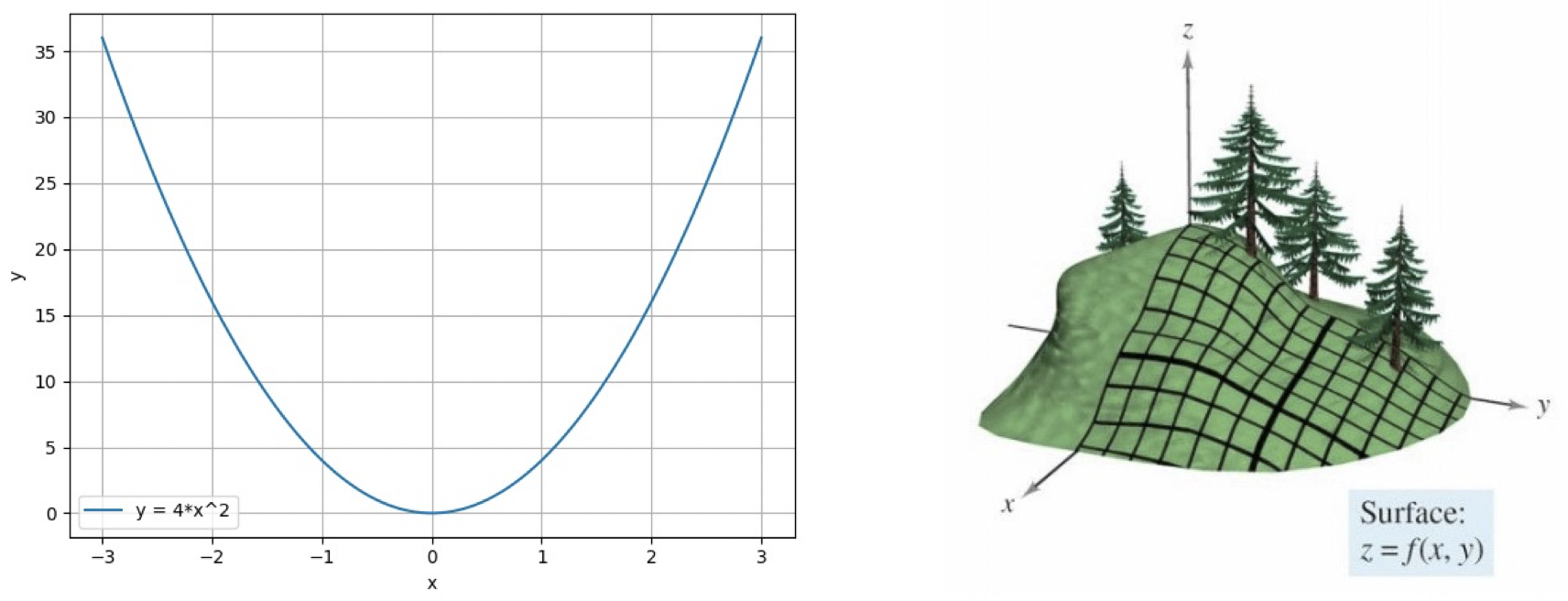
- 导数:函数在指定坐标轴上的变化率。
- 方向导数:指定方向上的变化率。
- 梯度:一个向量,方向为方向导数取得最大值的方向。
2. Optimizer 的属性
PyTorch 中的 Optimizer 类:
1
2
3
4
5
6
7
class Optimizer(object):
def __init__(self, params, defaults):
self.defaults = defaults
self.state = defaultdict(dict)
self.param_groups = []
param_groups = [{'params': param_groups}]
基本属性:
defaults:优化器超参数。state:参数的缓存,如momentum的缓存。params_groups:管理的参数组。_ step_count:记录更新次数,学习率调整中使用。
3. Optimizer 的方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
class Optimizer(object):
def zero_grad(self):
for group in self.param_groups:
for p in group['params']:
if p.grad is not None:
p.grad.detach_()
p.grad.zero_()
def add_param_group(self, param_group):
for group in self.param_groups:
param_set.update(set(group['params’]))
self.param_groups.append(param_group)
def state_dict(self):
return {'state': packed_state, 'param_groups': param_groups,}
def load_state_dict(self, state_dict):
基本方法:
zero_grad():清空所管理参数的梯度 (PyTorch 特性:张量梯度不自动清零)。step():执行一步更新。add_param_group():添加参数组。state_dict():获取优化器当前状态信息 字典。load_state_dict():加载状态信息字典。
例子:人民币二分类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
# -*- coding: utf-8 -*-
import os
import numpy as np
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
import torchvision.transforms as transforms
import torch.optim as optim
from matplotlib import pyplot as plt
from model.lenet import LeNet
from tools.my_dataset import RMBDataset
from tools.common_tools import transform_invert, set_seed
set_seed(1) # 设置随机种子
rmb_label = {"1": 0, "100": 1}
# 参数设置
MAX_EPOCH = 10
BATCH_SIZE = 16
LR = 0.01
log_interval = 10
val_interval = 1
# ============================ step 1/5 数据 ============================
split_dir = os.path.join("..", "..", "data", "rmb_split")
train_dir = os.path.join(split_dir, "train")
valid_dir = os.path.join(split_dir, "valid")
norm_mean = [0.485, 0.456, 0.406]
norm_std = [0.229, 0.224, 0.225]
train_transform = transforms.Compose([
transforms.Resize((32, 32)),
transforms.RandomCrop(32, padding=4),
transforms.RandomGrayscale(p=0.8),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
valid_transform = transforms.Compose([
transforms.Resize((32, 32)),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
# 构建MyDataset实例
train_data = RMBDataset(data_dir=train_dir, transform=train_transform)
valid_data = RMBDataset(data_dir=valid_dir, transform=valid_transform)
# 构建DataLoder
train_loader = DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
valid_loader = DataLoader(dataset=valid_data, batch_size=BATCH_SIZE)
# ============================ step 2/5 模型 ============================
net = LeNet(classes=2)
net.initialize_weights()
# ============================ step 3/5 损失函数 ============================
criterion = nn.CrossEntropyLoss() # 选择损失函数
# ============================ step 4/5 优化器 ============================
optimizer = optim.SGD(net.parameters(), lr=LR, momentum=0.9) # 选择优化器
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.1) # 设置学习率下降策略
# ============================ step 5/5 训练 ============================
train_curve = list()
valid_curve = list()
for epoch in range(MAX_EPOCH):
loss_mean = 0.
correct = 0.
total = 0.
net.train()
for i, data in enumerate(train_loader):
# forward
inputs, labels = data
outputs = net(inputs)
# backward
optimizer.zero_grad()
loss = criterion(outputs, labels)
loss.backward()
# update weights
optimizer.step()
# 统计分类情况
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).squeeze().sum().numpy()
# 打印训练信息
loss_mean += loss.item()
train_curve.append(loss.item())
if (i+1) % log_interval == 0:
loss_mean = loss_mean / log_interval
print("Training:Epoch[{:0>3}/{:0>3}] Iteration[{:0>3}/{:0>3}] Loss: {:.4f} Acc:{:.2%}".format(
epoch, MAX_EPOCH, i+1, len(train_loader), loss_mean, correct / total))
loss_mean = 0.
scheduler.step() # 更新学习率
# validate the model
if (epoch+1) % val_interval == 0:
correct_val = 0.
total_val = 0.
loss_val = 0.
net.eval()
with torch.no_grad():
for j, data in enumerate(valid_loader):
inputs, labels = data
outputs = net(inputs)
loss = criterion(outputs, labels)
_, predicted = torch.max(outputs.data, 1)
total_val += labels.size(0)
correct_val += (predicted == labels).squeeze().sum().numpy()
loss_val += loss.item()
valid_curve.append(loss_val)
print("Valid:\t Epoch[{:0>3}/{:0>3}] Iteration[{:0>3}/{:0>3}] Loss: {:.4f} Acc:{:.2%}".format(
epoch, MAX_EPOCH, j+1, len(valid_loader), loss_val, correct / total))
train_x = range(len(train_curve))
train_y = train_curve
train_iters = len(train_loader)
valid_x = np.arange(1, len(valid_curve)+1) * train_iters*val_interval # 由于valid中记录的是epochloss,需要对记录点进行转换到iterations
valid_y = valid_curve
plt.plot(train_x, train_y, label='Train')
plt.plot(valid_x, valid_y, label='Valid')
plt.legend(loc='upper right')
plt.ylabel('loss value')
plt.xlabel('Iteration')
plt.show()
# ============================ inference ============================
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
test_dir = os.path.join(BASE_DIR, "test_data")
test_data = RMBDataset(data_dir=test_dir, transform=valid_transform)
valid_loader = DataLoader(dataset=test_data, batch_size=1)
for i, data in enumerate(valid_loader):
# forward
inputs, labels = data
outputs = net(inputs)
_, predicted = torch.max(outputs.data, 1)
rmb = 1 if predicted.numpy()[0] == 0 else 100
img_tensor = inputs[0, ...] # C H W
img = transform_invert(img_tensor, train_transform)
plt.imshow(img)
plt.title("LeNet got {} Yuan".format(rmb))
plt.show()
plt.pause(0.5)
plt.close()
下面我们来看一下优化器中的 5 种基本方法的具体使用方式:
step()
为了方便计算,我们先设置学习率 lr=1:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
import os
import torch
import torch.optim as optim
from tools.common_tools import set_seed
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
set_seed(1) # 设置随机种子
weight = torch.randn((2, 2), requires_grad=True)
weight.grad = torch.ones((2, 2))
optimizer = optim.SGD([weight], lr=1)
print("weight before step:{}".format(weight.data))
optimizer.step() # 修改lr=1 0.1观察结果
print("weight after step:{}".format(weight.data))
输出结果:
1
2
3
4
weight before step:tensor([[0.6614, 0.2669],
[0.0617, 0.6213]])
weight after step:tensor([[-0.3386, -0.7331],
[-0.9383, -0.3787]])
可以看到,第一个梯度在更新之前的值为 $0.6614$,更新之后的值为 $0.6614 - 1 = -0.3386$。现在,我们将学习率设置为 lr=0.1,观察结果是否发生变化:
1
optimizer = optim.SGD([weight], lr=0.1)
输出结果:
1
2
3
4
weight before step:tensor([[0.6614, 0.2669],
[0.0617, 0.6213]])
weight after step:tensor([[ 0.5614, 0.1669],
[-0.0383, 0.5213]])
可以看到,第一个梯度更新后的值变为了 $0.6614 - 0.1 = 0.5614$。这就是 step() 方法的一步更新。
zero_grad ()
1
2
3
4
5
6
7
8
9
print("weight before step:{}".format(weight.data))
optimizer.step() # 修改lr=1 0.1观察结果
print("weight after step:{}".format(weight.data))
print("weight in optimizer:{}\nweight in weight:{}\n".format(id(optimizer.param_groups[0]['params'][0]), id(weight)))
print("weight.grad is {}\n".format(weight.grad))
optimizer.zero_grad()
print("after optimizer.zero_grad(), weight.grad is\n{}".format(weight.grad))
输出结果:
1
2
3
4
5
6
7
8
9
10
11
weight before step:tensor([[0.6614, 0.2669],
[0.0617, 0.6213]])
weight after step:tensor([[ 0.5614, 0.1669],
[-0.0383, 0.5213]])
weight in optimizer:4729862544
weight in weight:4729862544
weight.grad is tensor([[1., 1.],
[1., 1.]])
after optimizer.zero_grad(), weight.grad is
tensor([[0., 0.],
[0., 0.]])
可以看到,在执行 zero_grad() 之前,我们的梯度为 $[[1., 1.],[1., 1.]]$,执行之后变为了 $[[0., 0.],[0., 0.]]$。另外,我们看到,optimizer 中管理的 weight 的内存地址和真实的 weight 地址是相同的,所以我们在优化器中保存的是参数的地址,而不是拷贝的参数的值,这样可以节省内存消耗。
add_param_group ()
我们同样采用上面的优化器,该优化器当前已经管理了一组参数,就是我们的 weight。现在我们希望再增加一组参数,并且我们将该组参数的学习率设置的更小一些 lr=0.0001。首先,我们需要构建这样一组参数的字典,字典的 key 设置为 'params',其值为新的一组参数 w2;然后可以设置一些超参数,例如学习率 'lr' 等。然后我们使用 add_param_group () 将这组参数加入优化器中。
1
2
3
4
print("optimizer.param_groups is\n{}".format(optimizer.param_groups))
w2 = torch.randn((3, 3), requires_grad=True)
optimizer.add_param_group({"params": w2, 'lr': 0.0001})
print("optimizer.param_groups is\n{}".format(optimizer.param_groups))
输出结果:
1
2
3
4
5
6
7
8
optimizer.param_groups is
[{'params': [tensor([[0.6614, 0.2669],
[0.0617, 0.6213]], requires_grad=True)], 'lr': 0.1, 'momentum': 0, 'dampening': 0, 'weight_decay': 0, 'nesterov': False}]
optimizer.param_groups is
[{'params': [tensor([[0.6614, 0.2669],
[0.0617, 0.6213]], requires_grad=True)], 'lr': 0.1, 'momentum': 0, 'dampening': 0, 'weight_decay': 0, 'nesterov': False}, {'params': [tensor([[-0.4519, -0.1661, -1.5228],
[ 0.3817, -1.0276, -0.5631],
[-0.8923, -0.0583, -0.1955]], requires_grad=True)], 'lr': 0.0001, 'momentum': 0, 'dampening': 0, 'weight_decay': 0, 'nesterov': False}]
可以看到,在加入新参数之前,我们的优化器中只有一组参数,以一个列表形式呈现,里面只有一个字典元素。当我们使用 add_param_group () 之后,列表中有了两个字典元素。可以看到,两组参数的学习率是不同的,所以通过这种方式我们可以为不同的参数组设置不同的学习率,这在模型拟合过程中是一种非常实用的方法。
state_dict() 和 load_state_dict()
这两个函数用于保存优化器的状态信息,通常用于断点的继续训练。
保存状态信息:
1
2
3
4
5
6
7
8
9
10
11
optimizer = optim.SGD([weight], lr=0.1, momentum=0.9)
opt_state_dict = optimizer.state_dict()
print("state_dict before step:\n", opt_state_dict)
for i in range(10):
optimizer.step()
print("state_dict after step:\n", optimizer.state_dict())
torch.save(optimizer.state_dict(), os.path.join(BASE_DIR, "optimizer_state_dict.pkl"))
输出结果:
1
2
3
4
5
state_dict before step:
{'state': {}, 'param_groups': [{'lr': 0.1, 'momentum': 0.9, 'dampening': 0, 'weight_decay': 0, 'nesterov': False, 'params': [4745884296]}]}
state_dict after step:
{'state': {4745884296: {'momentum_buffer': tensor([[6.5132, 6.5132],
[6.5132, 6.5132]])}}, 'param_groups': [{'lr': 0.1, 'momentum': 0.9, 'dampening': 0, 'weight_decay': 0, 'nesterov': False, 'params': [4745884296]}]}
可以看到,在更新之前,'state' 里的值是一个空字典。在经过 10 步更新之后,'state' 字典中有了一些值,它的 key 是 4745884296,即参数地址,而它的值也是一个字典。其中 'momentum_buffer' 是动量中会使用的一些缓存信息。所以,在 'state' 中我们是通过地址去匹配参数的缓存的。然后,我们使用 torch.save 对字典进行序列化,将其保存为一个 pkl 的形式,可以看到当前文件夹下多了一个 optimizer_state_dict.pkl 的文件。
读取状态信息:
之前我们的模型已经训练了 10 次,假设我们总共需要训练 100 次,我们不希望再从头训练,而是希望能够接着之前第 10 次的状态继续训练,我们可以利用 load_state_dict 加载前面保存的 optimizer_state_dict.pkl 文件,并将其读取加载到优化器中继续训练:
1
2
3
4
5
6
optimizer = optim.SGD([weight], lr=0.1, momentum=0.9)
state_dict = torch.load(os.path.join(BASE_DIR, "optimizer_state_dict.pkl"))
print("state_dict before load state:\n", optimizer.state_dict())
optimizer.load_state_dict(state_dict)
print("state_dict after load state:\n", optimizer.state_dict())
输出结果:
1
2
3
4
5
state_dict before load state:
{'state': {}, 'param_groups': [{'lr': 0.1, 'momentum': 0.9, 'dampening': 0, 'weight_decay': 0, 'nesterov': False, 'params': [4684949616]}]}
state_dict after load state:
{'state': {4684949616: {'momentum_buffer': tensor([[6.5132, 6.5132],
[6.5132, 6.5132]])}}, 'param_groups': [{'lr': 0.1, 'momentum': 0.9, 'dampening': 0, 'weight_decay': 0, 'nesterov': False, 'params': [4684949616]}]}
可以看到,在加载之前,'state' 里的值是一个空字典。在使用 load_state_dict 加载之后,我们得到了之前第 10 次的参数状态,然后继续在此基础上进行训练即可。
4. 总结
本节课中,我们学习了优化器 Optimizer 的概念和一些基本属性及方法。在下节课中,我们将继续学习 PyTorch 中的一些常用的优化方法 (优化器)。
下节内容:优化器 (二)
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。 欢迎转载,并请注明来自:YEY 的博客 同时保持文章内容的完整和以上声明信息!