Module 07 透明度:决策和过程
1. 什么是透明度(Transparency)?
1.1 透明度
算法透明度:
随着越来越多的决策变得自动化并由算法处理,这些过程变得更加不透明和不负责任,存在秘密分析和非法歧视的风险。 对于 Rotenberg 来说,“现代隐私法的核心是一个单一的目标:使影响我们生活的自动化决策变得透明。” 他认为 “算法透明度”,即影响个人的数据过程被公开的原则,是透明度法、互联网法和隐私法发展的下一阶段。当前互联网生态系统缺乏算法透明度,对捍卫在线基本人权(从隐私和言论自由到安全)构成了重大挑战。除了算法透明度之外,Rotenberg 还指出了其他需要研究的新兴问题,特别是无人机和机器人越来越多的使用以及对其注册的需求。
机构透明度和公共价值:
算法 “透明度” 有很多方面,但在机构参与者的背景下,它需要与自动化决策系统相关的采购、实施和技术机制的清晰度。 这种类型的透明度有助于跟踪决策系统随着时间的推移产生的影响,并在其目的、范围、政策和技术方面实现一些公开披露。
1.2 关于术语(和重点)的说明
一些学者使用术语透明度来描述算法的 “内部运作”(例如 Loi 等人,2020:https://link.springer.com/article/10.1007/s10676-020-09564-w)。
澄清一下,该模块的重点是算法 系统 的 首要流程和决策。
我们在 可解释性(explainability) 的旗帜下囊括了关于算法本身的可解释性、反事实分析(counterfactual analysis)等的技术考虑。
(我们自己的蒂姆米勒是该领域的专家)。
1.3 例子:假设性思想实验 —— 深度学习和你的成绩
如果对于本单元,我们会根据最先进的基于深度学习的估计器/预测器来确定您的最终成绩,该估计器/预测器将根据 1,000 个因素得出最终成绩 —— 从您观看的关于伦理的 Youtube 视频的数量,到你在每周讨论活动中的活跃度,当被要求在讨论板上发表评论时你的打字速度,你对西蒙和导师教你伦理基础知识时在 Zoom 上的反应,你对模块中的 Marc 的互联网模因(meme)笑了多少,等等。最终的分数预测器是如此先进,已经通过了 NASA、Google 和 10 位诺贝尔奖获得者的审核!然而,由于使用的一些基于张量的算法是 NVidia 的专利,NVidia 赞助了用于深度学习的 Geforce RTX3090 阵列,因此它们不能公开披露。此外,预测器做出的决定即为最终决定。
1.4 反思
- 流程:
- 谁来管理 ML 模型/训练数据的选择?
- 优先考虑哪些供应商?例如:
- 为什么选择谷歌(而不是 AWS)?
- 为什么选择 Tensorflow 和 Nvidia?
- 有什么利益冲突吗?有任何反馈循环吗?
- 为什么整个系统都笼罩在秘密之中?
- 谁审核的?我可以看到源代码/设计原理图/基本原理吗?
- 我甚至注册过吗?
- 决策:
- 我们可以挑战他们吗?
- 我可以把这个告上法庭吗?
- 谁批准这是官方的?
- 这是另一家剑桥分析公司吗?
注:剑桥分析公司(Cambridge Analytica,简称 CA),是一家进行资料探勘及数据分析的私人公司。在2018年3月爆发不当取得5000万Facebook用户数据之丑闻而闻名。丑闻曝光后,客户和供应商大量流失、内外部调查和诉讼费用不断上涨,2018年5月2日宣布“立即停止所有营运”,并在英国和美国申请破产。
2. 自动决策 (ADM) 系统:每个阶段的透明度?
2.1 免责声明:我不是律师
本次小型讲座中提供的信息从各种来源进行总结,以解释透明度不仅是算法的要求,也是围绕其实施的上下文的要求。
本次讲座不会让您成为行政决策专家 ☺
2.2 AADM
来源:Administrative Review Council, Automated Assistance in Administrative Decision Making: Report to the Attorney General (Report No 46, November 2004) (‘2004 Report’)
2004年的报告在当时是超前的
第 27 页:“系统内置的保障措施只是询问相关问题,告诉客户为什么会提出问题(这使得决策过程更加透明),并向客户记录和解释决策的原因”
第 43 页:“专家系统所提供的 对他们所参与的行政决策过程的审查跟踪 能力,对于透明度、公平和效率的行政法价值很重要。 ”
第 45 页:“一个好的内部审查系统是一个 过程透明 的系统,可以对决策进行快速、低成本且独立的审查。这样的系统对申请人和机构都有利”。(引自 Administrative Review Council 2000)
2.3 GDPR
4.通用数据保护条例中的透明度和问责制
GDPR 中的许多条款旨在促进个人数据处理过程中的高度透明度 [6]。一般来说,这些规定要求数据控制者向数据主体提供有关其个人数据处理的信息,并以简洁、透明、易懂且易于访问的形式,使用清晰明了的语言。
如果从数据主体获取个人数据,第 13(2)(f) 条要求数据控制者向数据主体提供相关信息——“自动决策的存在,包括分析……以及有关所涉及逻辑的有意义的信息,以及作为此类处理对数据主体的重要性和预期后果”。此类信息提供的目的据说是 “确保公平和透明的处理”。
来源:Christina Blacklaws, ‘Algorithms: transparency and accountability’, Phil. Trans. R. Soc. A.3762017035120170351. (2018).
https://royalsocietypublishing.org/doi/10.1098/rsta.2017.0351
2.4 AI 系统的高层次视角 (OECD, 2019)
来源:OECD (2019), Artificial Intelligence in Society, OECD Publishing, Paris, https://doi.org/10.1787/eedfee77-en.

2.5 ML 系统的要素 (Google Inc, from Scully et al 2015)
来源:https://cloud.google.com/solutions/machine-learning/mlops-continuous-delivery-and-automation-pipelines-in-machine-learning —— 改编自 Scully 等人 (2015) https://papers.nips.cc/paper/2015/file/86df7dcfd896fcaf2674f757a2463eba-Paper.pdf
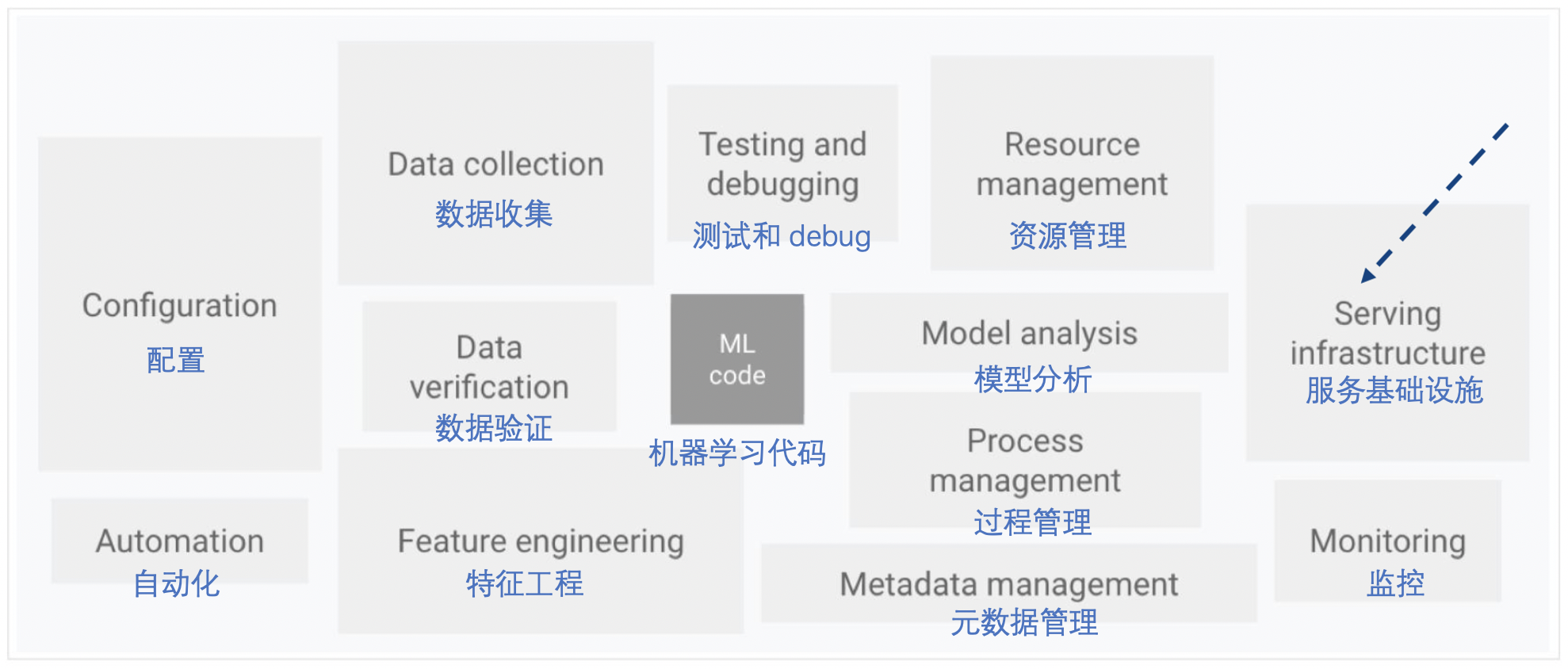
2.6 反思
从我们的例子来看,代码(‘算法’)只是其中的一小部分!
规划、实施、审计,以及涉及数据、设计、测试、部署……都需要透明度。
另外,还要考虑更广泛意义上的法律方面和哲学概念:包括公平、追索权……
3. 当前的透明度问题:社交媒体广告系统
3.1 考虑 Facebook 的产品组
如果我们使用 Instagram、Facebook、WhatsApp,我们中有多少人实际阅读了服务条款(Terms of Service, TOS)?

没有阅读 Facebook 的细则条款?这正是它所说的 阿曼达·舍克
因此,与全球 12.8 亿每月活跃 Facebook 用户中的其他每一个人一样,您在没有阅读细则的情况下盲目地同意了 Facebook 的条款和条件。
您在未阅读网站政策的情况下将您的相册、私人消息和关系委托给了网站。并且您对所有其他网站都这样做……听起来对吗?
为您辩护,卡内基梅隆大学的研究人员确定,美国人平均需要 76 个工作日才能阅读他们每年同意的所有隐私政策。所以你并不是因为懒惰而逃避阅读;这实际上是一种保住工作的行为。
所以这里是你和 Facebook 签订这份合同时你同意的 “克里夫笔记”。顺便说一下,一旦您完成注册它就开始生效了:
女性 男性 单击 “注册” 即表示您同意我们的条款并且您已阅读我们的数据使用政策。包括我们的 Cookie 使用。
大约打印了 9 -10 页 A4 纸(截至本次讲座)。
由 TOSDR (https://tosdr.org/en/service/182) 总结 —— 即使是关键点也占用了大约 2 页 A4 纸,参考下图:

这甚至不包括附加政策:例如 “商业标准”、“广告政策”……(还有 12 个链接)
3.2 我们再看看 Twitter?
A4 纸打印了大约 39 页!!!(截至本次讲座)。
由 TOSDR (https://tosdr.org/en/service/195) 总结 —— 即使是关键点也占用了约 2 页 A4 纸,参考下图:

3.3 考虑广告:这是 “透明的” 吗?
假设我在 Facebook 上看到了一个广告(赞助帖子)。作为消费者,我想知道 为什么 会被推送该广告。
我转到服务条款,然后找到 “广告”,然后找到 “数据政策”……它又将我带到另一个页面……这让我害怕。

设备信息
如下所述,我们从您使用的与我们的产品集成的计算机、电话、联网电视和其他联网设备上收集信息,并将这些信息整合到您使用的不同设备中。例如,我们使用收集的有关您在手机上使用我们产品的信息来更好地个性化您在其他设备(如笔记本电脑或平板电脑)上使用我们产品时看到的内容(包括广告)或功能,或衡量您是否针对我们在其他设备上的手机上向您展示的广告采取了行动。
我们从这些设备获得的信息包括:
- 设备属性:诸如操作系统、硬件和软件版本、电池电量、信号强度、可用……
让我们尝试另一种方法 —— 转到广告,然后单击菜单。

Facebook 给了我一些理由。
但是,还有 “更多未列出的因素”……并将我引导到一个包含许多解释的大页面,但都是 “可能”(我们可能、广告商可能……)……并且用很长的服务条款解释了多种方式。
问题:这是否足够透明?社交媒体公司应该/可以做什么?
参考:https://psyarxiv.com/ea28z/ - Lorenz-Spreen et al (2021)
第 4 - 5 页:
“目前,平台的透明度措施只是提供了 “名义透明度”,并没有真正考虑人们是否真的可以轻松访问、阅读和深入了解有关他们的信息,以及这种名义上的透明度是否会促进用户的自主权。
“旨在实现有效的透明度 —— 这显然使用户能够了解平台如何处理他们的数据以及用户的选择意味着什么,然后将这些知识转化为可衡量的行为 —— 是朝着更可接受的商业实践和重新获得一些失去自主权的用户的重要步骤(例如,通过提示人们调整他们的隐私设置,Parra-Arnau 等人,2017)
4. 当前透明度问题:刑事司法人工智能系统
4.1 刑事司法 AI 系统
您在探索 AI 伦理时可能遇到过以下示例。
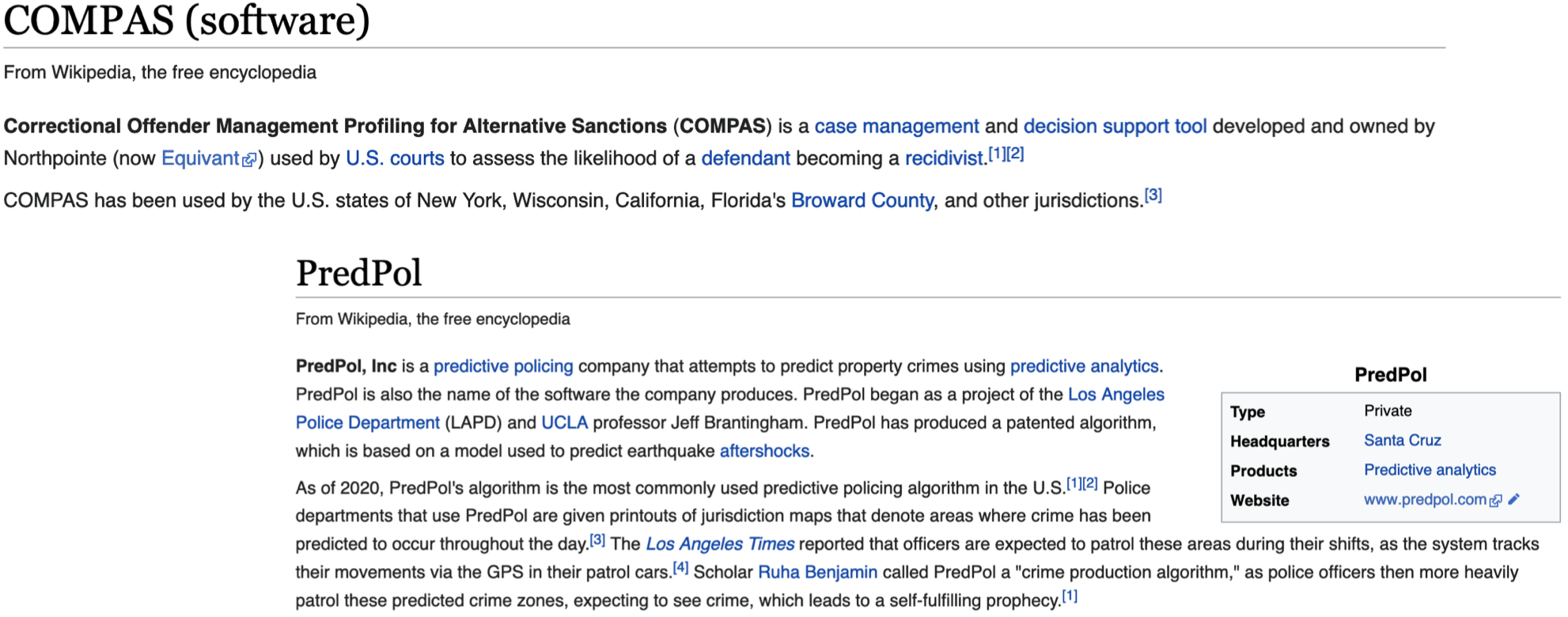
COMPAS(软件)
替代制裁的惩教罪犯管理概况 (COMPAS) 是 Northpointe(现为 Equivant)开发和拥有的案件管理和决策支持工具,美国法院使用该工具评估被告成为惯犯的可能性。
COMPAS 已被美国纽约州、威斯康星州、加利福尼亚州、佛罗里达州布劳沃德县和其他司法管辖区使用。
PredPol
PredPol, Inc 是一家预测性警务公司,试图使用预测分析来预测财产犯罪。PredPol 也是该公司生产的软件的名称。PredPol 最初是洛杉矶警察局 (LAPD) 和加州大学洛杉矶分校教授杰夫·布兰廷厄姆 (Jeff Brantingham) 的一个项目。PredPol 开发了一种专利算法,该算法基于用于预测地震余震的模型。
截至 2020 年,PredPol 的算法是美国警察局中最常用的预测警务算法,使用 PredPol 的警察局会打印出管辖地图,这些地图表示预计全天发生犯罪的区域。《洛杉矶时报》报道说,警官们应该在轮班期间巡逻这些区域,因为系统会通过巡逻车中的 GPS 跟踪他们的行踪。学者鲁哈·本杰明 (Ruha Benjamin) 称 PredPol 是一种 “犯罪生成算法”,因为警察随后会更频繁地巡逻这些预测的犯罪区域,希望看到犯罪,这导致了自我实现的预言。
4.2 阅读:Rudin (2019) 关于 COMPAS
本案例研究的重点不是底层算法的技术可解释性等,而是关于所涉及的流程和决策的透明度。
以 COMPAS 及其在实践中的 决策 假设为例(Rudin, 2019):
停止为用于高风险决策的黑盒机器学习模型提供解释,而是使用可解释的模型
Cynthia Rodin
“但是如果模型是一个黑匣子,则很难手动校准这些附加信息应该提高或降低估计风险的程度。这类问题不断出现:例如,美国司法系统用于再犯风险预测的专有 COMPAS 模型不依赖于当前犯罪的严重性 [27, 29]。相反,法官被指示以某种方式手动将当前犯罪与 COMPAS 结合起来。事实上,很多法官可能并不知道这个事实。如果模型是透明的,法官可以直接看到在风险评估中没有考虑当前犯罪的严重性。”
现在,在实践中使用 COMPAS 及其模型选择(Rudin, 2019):
(i) 公司可以从提供给黑匣子的知识产权中获利。
如果改用可解释的模型,对个人预测收费的公司可能会发现他们的利润被抹杀。
考虑上面讨论的 COMPAS 专有的累犯风险预测工具,该工具在美国司法系统中广泛使用,用于预测某人在获释后被捕的概率 [29]。
COMPAS 模型对于累犯预测与非常简单的三规则可解释机器学习模型同样准确,仅涉及下图所示的年龄和过去犯罪次数。然而,没有明确的商业模式表明可以从简单的透明模式中获利。图 3 中的简单模型是根据一种称为可证明最优规则列表 (CORELS) 的算法创建的,该算法查找 if-then……
4.3 阅读:Asaro (2019) 关于 PredPol (参考: COMPAS)
同样,我们考虑 COMPAS;参见 Asaro 中的 PredPol (2019)
算法、数据和实施实践的透明度也是必要的。虽然芝加哥警察局试图避免因公布 SSL 的细节而感到尴尬,但独立的外部研究人员无法在无法访问数据和算法的情况下评估其正面和负面影响。政府机构共享公共数据不应该需要报纸的长期诉讼。当然,随着越来越多的商业系统(如 PredPol)将算法甚至数据设为专有,它们将受到知识产权保护。这意味着私人公司将会处理这些数据,并且不需要透露他们的算法,或让他们接受独立的外部审查。在某些情况下,私人……
4.4 阅读:Ferguson (2017) 关于 PredPol (参考: COMPAS)
同样,我们考虑 COMPAS;参见 PredPol - Ferguson (2017) 提供了一个法律视角。
所有阶段的问题:犯罪统计、资料档案、个人/文化偏见、数据输入/分析、技术复杂性、财务/知识产权利益、审查、评估指标……
华盛顿大学法律评论 第 94 卷,第 5 期,2017 警务预测警务 安德鲁·格思里·弗格森
1.透明度:漏洞
按照目前的实施情况,各级预测性警务都缺乏透明度。即使是像犯罪统计这样简单的东西,在许多情况下都是公开的,但仍然充满了对准确性和完整性的担忧。将个人数据档案添加到这些犯罪统计数据中会产生新的问题,因为信息的庞大数量使得对预测来源的透明评估变得复杂。如果您压根看不到存在这样的错误,您如何修复数据中的错误?您怎么知道谁有责任将信息输入这些大型聚合数据库?此外,无意的个人或文化偏见会影响数据、评分系统、源代码,从而影响由此产生的预测结果。简而言之,如果没有在揭示数据收集方法、弱点和差距方面进行大量投资,也没有在理解与输入和分析数据相关的挑战方面进行同等投资,整个系统就会冒着建立在未知和不可知数据库上的风险。
算法的性质进一步模糊了这个过程,技术专家可能除外。警察和管理人员会收到结果,但由于所选算法的复杂性,他们很少能理解其背后的数学原理。因此,预测警务遇到了与其他自动化预测技术相同的问题:设计的技术复杂性使得外人几乎不可能确定程序的准确性、有效性或公平性。的确,警察可以看到系统是否工作,但警察无法理解系统是如何工作的。这种缺乏透明度不仅仅是新技术的结果,也是软件专有性质的影响。参与这些真实世界测试的公司正在一场耗资数百万美元的竞赛中说服警察部门采用他们的特定产品。这些公司有需要保护的经济利益和专有机密,以及报告积极成果的一切动力。
有效性本身仍然是一个有争议的问题。早期测试表明使用某些预测性警务技术与犯罪率降低(对于某些犯罪)之间存在相关性。但未来警区如何确定指标?犯罪可能会上升或下降,与所选的计算机程序无关。犯罪分析人员可能会做出或多或少准确的比较判断。最重要的是,外人如何审核数据?在类似的警方数据收集实验(DNA 数据库、“拦截搜身” 报告)中,警方对自己进行了审核,而结果喜忧参半。
4.5 反思
司法/警务中的人工智能系统对人们在法律下的自由和地位造成严重影响。
人工智能伦理的法律视角为我们提供了关于透明度需求的另一个视角。
“透明度的实施非常困难,但它对处理个人生活和自由的有效预测系统很重要” (Ferguson, 2017)
我们如何开始解决问题?
例如,对于 PredPol —— 审核、评估指标的公开发布、培训 (Ferguson, 2017)。
5. 大数据研究与社交媒体:从选举到流行病
5.1 阅读:Walsh (2019)
社交媒体实验
作者:Toby Walsh
摘要 Facebook 和 Twitter 等社交媒体平台允许以最低的成本对科学家以前可能梦想过的规模的人群进行实验。例如,Facebook 上的一项实验涉及超过 6000 万名受试者。如此大规模的实验带来了新的挑战,因为当乘以大量人口时,即使很小的效应也会产生重大影响。
最近关于使用社交媒体操纵投票行为的揭露加剧了这种担忧。据信,Cambridge Analytica 用于针对美国选民的心理测量数据是由剑桥大学的 Aleksandr Kogan 博士使用 Facebook 上的个性测验收集的。未来想要在社交媒体平台上收集数据和进行实验的研究人员面临着真正的风险,他们将面临公众的强烈反对,从而阻碍此类研究的开展。我们建议采取更强有力的保护措施来帮助防止这种情况发生,并确保公众对使用社交媒体进行行为和其他研究的科学家保持信心。
不仅仅是以操纵选举为目的 Cambridge Analytica 公司。
Walsh (2019) 发现,学术界关于 “提高选民参与度” 的研究实际上 “增加了约 340,000 票的投票率” (引用 Bond 等人, 2012)。
问题:
-
Cambridge Analytica 公司很糟糕,我相信你同意这点……
-
但是对于第二个实验 —— 这不是一件好事吗?增加选民参与 = 健康的民主?
第一个建议是,我们可能不仅需要考虑对被研究个体的影响,还要考虑任何实验可能对社会产生的更广泛的影响。对于投票的研究,这可能是一种选举风险。对于假新闻的研究,它可能会降低社会对真实新闻的信任。对于操纵人们情绪的研究,可能是研究人群的情绪健康。
Walsh 对社交媒体和大数据研究透明度的思考(2019 年):
-
“第一个建议是,我们可能不仅需要考虑对被研究个体的影响,还需要考虑任何实验可能对社会产生的更广泛的影响……”
-
“第二个建议是,可能需要伦理批准……”
-
“第三个建议是,任何实验的受试者可能需要在研究后直接告知结果以及他们的参与……”
#2 和 #3 的激发/思想实验:
例如,对 Twitter 的一项研究可能涉及 100k - 1M 的推文/用户(或更多?)
这怎么可能实现?
5.2 总结
社交媒体上的大数据研究引发了许多担忧 —— 隐私(用户是否可以选择退出 “来自研究人员的凝视”);自主性(研究是否要求用户做他们不会做的事情?);福利(研究是否有可能改变情绪/健康结果?)……这些对用户来说清楚吗?
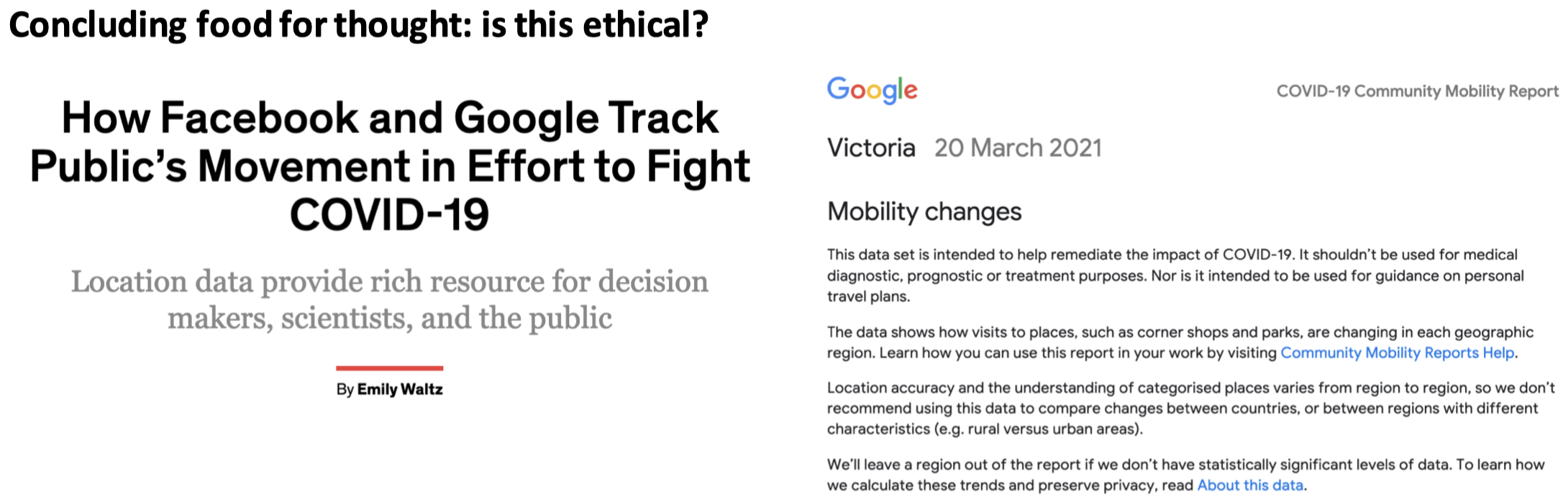
总结深思:这合乎道德吗?
6. 推荐阅读
- Experiments in Social Media.
- Stop Explaining Black Box Machine Learning Models for High Stakes Decisions and Use Interpretable Models Instead.
- Facebook–Cambridge Analytica data scandal.
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。 欢迎转载,并请注明来自:YEY 的博客 同时保持文章内容的完整和以上声明信息!