1. 案例背景
随着电商⾏业近⼏年的迅猛发展,电⼦商务从早些年的粗放式经营,逐步转化为精细化运营。随着平台数据量的不断积累,通过数据分析挖掘消费者的潜在需求,消费偏好成为平台运营过程中的重要环节。本项⽬基于某电商平台⽤户⾏为数据,在 MySQL 关系型数据库,探索⽤户⾏为规律,寻找⾼价值⽤户;分析商品特征,寻找⾼贡献商品;分析产品功能,优化产品路径。
2. 分析流程
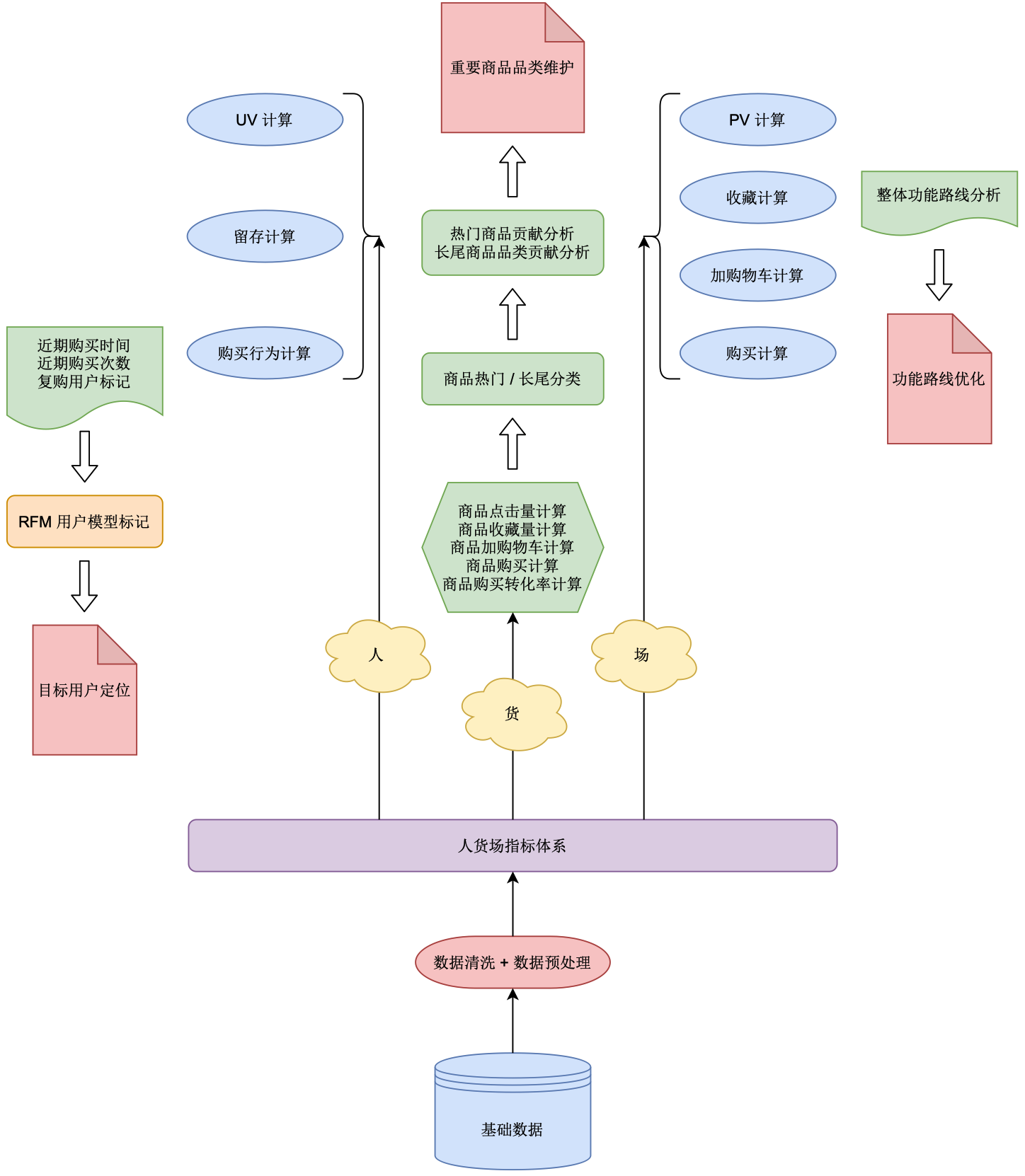
首先,我们看一下最下面的 基础数据 模块。这些基础数据一般是由业务系统工程师提供,他们可能会采集一些日志文件,并对这些日志文件进行分析,然后放入数据库中。此案例中的基础数据可能会涉及到用户行为数据,例如:当用户收藏某件商品时,会生成一条记录;当用户将商品加入购物车时,会生成一条记录;当用户进行支付购买时,会生成一条记录……每当有此类特殊事件触发时,就会生成一条记录并将其加入数据库中(或者,写入日志文件中)。这些基础数据就是我们后期进行一些分析工作的前提。
有了基础数据之后,在进行分析之前,我们还需要对其进行一些处理:
-
数据清洗:为什么要进行数据清洗呢?因为原始的基础数据中可能存在一些脏数据,即那些不符合规范要求的数据。那么,为什么会存在脏数据呢?因为业务系统工程师在采集这些数据的过程中,可能本身就存在一些不规范的地方;另外,业务工程师在采集数据时可能并不能提前知道后续的业务分析中对于数据有哪些要求,例如采集过程中可能某些字段为空,而实际业务要求该字段不能为空等等。具体脏数据的定义还需要结合实际项目情况来决定,例如:出现空字段、重复记录等。因此,在进行正式分析之前,需要先对基础数据进行数据清洗。
-
数据预处理:所谓预处理就是提前对数据进行一些处理,它是相对正式分析过程中的数据处理而言的。例如,后期的很多指标统计都依赖于某行为产生时的日期(YYYY/MM/DD),但是基础数据中的相关信息只有完整的时间戳形式(”日期 + 时间“),而考虑到后期很多地方都需要用到单独的日期信息,所以我们可以在原始时间戳的基础上,对其进行预处理,生成一个新的日期字段方便后期分析时使用。
在完成数据清洗和预处理后,我们就来到了 指标体系,即我们需要统计分析哪些指标,它其实是在整个项目经营设计阶段(即正式经营之前)就应该提前构建的。本例中,指标体系的构建基于 ”人 + 货 + 场“ 理论:”人“ 指的是电商平台的用户,”货“ 指的是电商平台的产品,”场“ 指的是电商平台本身。也就是说,我们需要分别对用户、商品、平台进行数据分析。
接下来,我们来看一下针对用户、商品、平台,都有哪些具体指标需要进行分析:
-
首先,针对用户,我们可以进行 PV 和 UV 的计算,这里 PV(Page View)指的是访问次数,即一定时间内某个页面的浏览次数;UV(Unique Visitor)指的是访问人数,即一定时间内访问某个页面的人数。 然后,我们还可以计算 留存,它指的是某一个统一时段内新增的用户数中,经过一段时间后仍在使用我们网站或者 APP 的用户占当初新增用户的比例。 再就是 购买行为 的计算,即用户购买了什么商品、属于什么品类、购买量是多少等等。然后,我们还可以使用 RFM 模型 进行统计,它是一种用于衡量当前用户价值和用户潜在价值的工具,即当前用户对平台产生了多少贡献,以及他们未来会对平台产生多少贡献,是否属于高价值用户等。通过 RFM 模型,我们可以对目标用户进行精准定位。
-
然后,针对商品,我们可以计算某商品的 点击量、收藏量、加入购物车的数量、购买量、购买转化率 等。
-
最后,针对平台,我们可以对商品被浏览、收藏、添加到购物车、最终购买 —— 这类在整个流程中比较重要的一些节点数据进行分析,计算 每个环节的转化率 是多少,看一下是否其中某个环节存在问题(系统功能、用户体验等),并针对该环节进行 功能优化。
因此,上图反映出了本案例中的业务流程。一般经典的电商类数据分析流程基本都与之类似,即:
基础数据 $\longrightarrow$ 数据清洗、预处理 $\longrightarrow$ “人货场” 指标体系 $\longrightarrow$ 统计各种指标 $\longrightarrow$ 根据这些指标来分析指导后期运营策略
3. 使⽤ “⼈货场” 拆解⽅式建⽴指标体系
最终结果:评价 “⽤户、商品、平台“ 三者的质量
⼈货场:
-
“人”(⽤户)是整个运营的核⼼。所有举动都围绕着,如何让更多的⼈有购买⾏为,让他们买的更多,买的更贵。所以对⼈的洞察是⼀切⾏为的基础。⽬前平台上的主⼒消费⼈群(用户)有哪些特征,他们对货(商品)有哪些需求,他们活跃在哪些场(平台),还有哪些有消费⼒的⼈⽬前不在平台上,对这些问题的回答指向了接下来的⾏动。

-
“货” (商品)就对应供给,涉及到了货品分层,哪些是红海(销量高、利润少、竞争多),哪些是蓝海(销量少、利润高、竞争少),如何进⾏动态调整,是要做⾃营还是平台,以满⾜消费者的需求(最终目的还是追求平台利益最大化)。
-
“场”(平台)就是消费者在什么场景下,以什么样的⽅式接触到了这个商品。平台可以理解为就是电商网站,但是现在这个 “场” 的概念已经前后有所延伸,往前延伸指的是推广引流等,往后延伸指的是物流、售后等。早期的导购(引流)做的⽐较简单,⽬前的场就⽐较丰富,但也暴露了淘宝和京东在导购⽅⾯的⼀些问题。⽐如内容营销,⽬前最好的可能是微信的 KOL(关键意见领袖,例如:网红、大 V 等) ⽣态和⼩红书,甚⾄微博,⽽不在电商⾃⼰的场。如何做⼀个全域的打通,和消费者进⾏多触点的接触,⽐如社交和电商联动,来完成销售转化,这就是腾讯和阿⾥⼀直都在讲的 “全域营销”。
4. 确认问题
本次分析的⽬的是想通过对⽤户⾏为数据进⾏分析,为以下问题提供解释和改进建议:
-
基于漏⽃模型的⽤户购买流程各环节分析指标,确定各个环节的转换率,便于找到需要改进的环节;
-
商品分析:找出热销商品,研究热销商品特点;
-
基于 RFM 模型找出核⼼付费⽤户群,对这部分⽤户进⾏精准营销(进一步挖掘 / 挽留)。
5. 准备⼯作
5.1 数据读取(⽤户⾏为数据)
表结构:
| 列名 | 说明 |
|---|---|
| user_id | ⽤户 ID |
| item_id | 商品 ID |
| behavior_type | ⽤户⾏为类型(1-曝光;2-购买;3-加⼊购物⻋;4-加⼊收藏夹。) |
| user_geohash | 地理位置 |
| item_category | 品类 ID |
| time | ⽤户⾏为发⽣的时间 |
基础数据(部分):
| user_id | item_id | behavior_type | user_geohash | item_category | time |
|---|---|---|---|---|---|
| 98047837 | 232431562 | 1 | 4245 | 2019-12-06 02 | |
| 97726136 | 383583590 | 1 | 5894 | 2019-12-09 20 | |
| 98607707 | 64749712 | 1 | 2883 | 2019-12-18 11 | |
| 98662432 | 320593836 | 1 | 96nn52n | 6562 | 2019-12-06 10 |
| 98145908 | 290208520 | 1 | 13926 | 2019-12-16 21 | |
| 93784494 | 337869048 | 1 | 3979 | 2019-12-03 20 | |
| 94832743 | 105749725 | 1 | 9559 | 2019-12-13 20 | |
| 95290487 | 76866650 | 1 | 10875 | 2019-11-27 16 | |
| 96610296 | 161166643 | 1 | 3064 | 2019-12-11 23 | |
| 100684618 | 21751142 | 3 | 2158 | 2019-12-05 23 | |
| 100509623 | 266020206 | 3 | tfvomgk | 4923 | 2019-12-08 17 |
| … | … | … | … | … | … |
注意:基础数据中的时间格式为 年-月-日 小时(24 小时制),例如:2019-12-06 02。
创建数据表:
1
2
3
4
5
6
7
8
9
-- 创建数据表
CREATE TABLE o_retailers_trade_user (
user_id INT(9),
item_id INT(9),
behavior_type INT(1),
user_geohash VARCHAR(14),
item_category INT(5),
time VARCHAR(13)
);
导入数据:
1
2
-- 查看基础数据
SELECT * FROM o_retailers_trade_user LIMIT 11;

5.2 数据预处理
增加新列 date_time (DATETIME)、dates (CHAR),便于后续时间维度分析:
1
2
3
4
5
6
7
8
-- 增加新字段 date_time,字段数据来自基础数据中的 time 字段
-- %H 可以表示 0-23;⽽ %h 表示 0-12
ALTER TABLE o_retailers_trade_user ADD COLUMN date_time DATETIME NULL;
UPDATE o_retailers_trade_user SET date_time = STR_TO_DATE(time, '%Y-%m-%d %H');
-- 增加新字段 dates,字段数据来自上面新增的 date_time 字段
ALTER TABLE o_retailers_trade_user ADD COLUMN dates CHAR(10) NULL;
UPDATE o_retailers_trade_user SET dates = DATE(date_time);
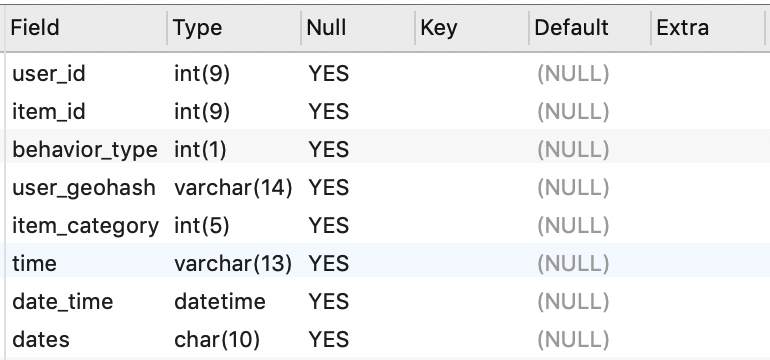
查看更新后的表结构和数据:
1
2
-- 查看更新后的表结构
DESC o_retailers_trade_user;
1
2
-- 查看更新后的数据
SELECT * FROM o_retailers_trade_user LIMIT 11;

重复值处理:创建新表 temp_trade,并向其中插⼊去重后的数据
1
2
3
-- 创建新表 temp_trade,并向其中插⼊去重后的数据
CREATE TABLE temp_trade LIKE o_retailers_trade_user;
INSERT INTO temp_trade SELECT DISTINCT * FROM o_retailers_trade_user;
6. 指标体系建设
“⼈ 货 场” 指标体系
6.1 ⽤户指标体系
基础指标体系(UV / PV / 留存率)+ RFM 模型分析
6.1.1 基础指标
UV、PV、浏览深度统计
1
2
3
4
5
6
7
8
9
10
11
12
13
14
/*
pv:统计 behavior_type = 1 的记录数量,需要按日统计(分组)
uv:统计 DISTINCT user_id 的数量,需要按⽇统计(分组)
浏览深度:pv/uv
注意:pv 进⾏ COUNT 的时候,如果 behavior_type = 1 则进⾏计算;否则,不进⾏计算
*/
SELECT dates,
COUNT(DISTINCT user_id) AS uv,
COUNT(IF(behavior_type = 1, user_id, NULL)) AS pv,
COUNT(IF(behavior_type = 1, user_id, NULL)) / COUNT(DISTINCT user_id) AS 'pv/uv'
FROM temp_trade
GROUP BY dates;

留存率(按日)统计
注意:留存率可以分为很多种,例如:新注册用户留存率、活跃用户留存率等。由于本案例中的数据并没有包含用户注册相关信息,因此这里我们统计的是活跃用户留存率。
例如:
| 基准日期 | 当日活跃用户 | 1 天以后活跃用户 | 2 天以后活跃用户 | …… |
|---|---|---|---|---|
| 2019-12-28 | 100 人 | 90 人(90%) | 80 人(80%) | …… |
| …… | …… | …… | …… | …… |
我们需要:
-
获取到一个类似上面的结果集
-
基础数据中所有的日期都应该进行如上的计算
例如,对于 ID 为 98047837 的用户,以 2019-12-28 为基准日期计算之后一段时间内的日活跃率,我们需要在数据集中找到该用户 2019-12-28 之后的数据,即:
| user_id | dates | dates_after |
|---|---|---|
| 98047837 | 2019-12-28 | 2019-12-29(如果该用户 29 日这天记录存在,那么该用户在 29 日这天就是活跃的) |
| 98047837 | 2019-12-28 | 2019-12-30(同上) |
| …… | …… | …… |
因此,对于该用户,我们通过计算 (dates_after - dates)得到某后续日期与基准日期相差的天数,如果结果等于:
- 1 天,我们就应该在计算 “1 天以后活跃用户” 的时候 +1,或者进行
COUNT()计数; - 2 天,我们就应该在计算 “2 天以后活跃用户” 的时候 +1,或者进行
COUNT()计数; - ……
然后,我们该如何得到如前面展示的同时包含 “当日活跃用户”、“1 天以后活跃用户”、“2 天以后活跃用户” 等字段的表结构呢?
我们可以使用 自关联 的方式来完成:
首先,我们可以先从 temp_trade 表中筛选出 user_id 和 dates 字段,并按照这两个字段分组。这种情况下,某用户在某天即使存在多条记录也只返回一条,即表明该用户在这天是活跃的:
1
SELECT user_id, dates FROM temp_trade GROUP BY user_id, dates;
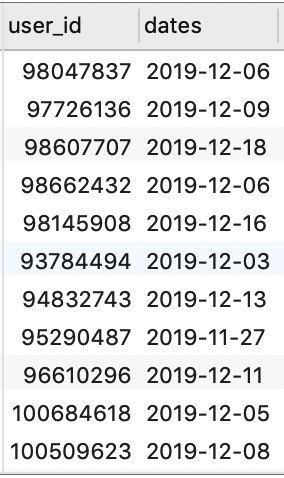
可以看到,得到的结果与我们之前所期望的数据集还差一个 dates_after 字段,下面我们尝试通过自关联的方式来得到该日期:
1
2
3
4
5
6
SELECT *
FROM
(SELECT user_id, dates FROM temp_trade GROUP BY user_id, dates) AS a
LEFT JOIN
(SELECT user_id, dates FROM temp_trade GROUP BY user_id, dates) AS b
ON a.user_id = b.user_id;
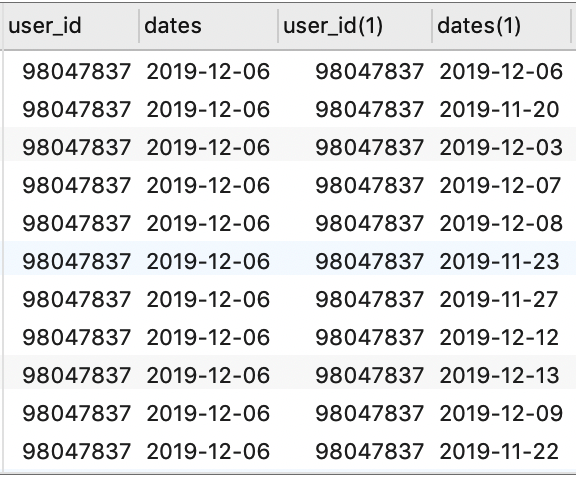
现在,我们得到了两个日期字段,但是我们发现某些记录中,第二个日期字段比第一个日期字段小,例如第 2 行中,dates 为 2019-12-06,而 dates(1) 为 2019-11-20。由于我们希望计算的是基准日期当天的活跃用户数,以及之后一段时间内的活跃用户留存率,因此第二个日期字段应该要大于或者等于第一个日期字段(然后再计算两个日期之间相差的天数)。所以,我们还需要通过 WHERE 条件对上面的结果集进行过滤:
1
2
3
4
5
6
7
8
9
10
SELECT
a.user_id,
a.dates,
b.dates AS dates_after
FROM
(SELECT user_id, dates FROM temp_trade GROUP BY user_id, dates) AS a
LEFT JOIN
(SELECT user_id, dates FROM temp_trade GROUP BY user_id, dates) AS b
ON a.user_id = b.user_id
WHERE b.dates >= a.dates;
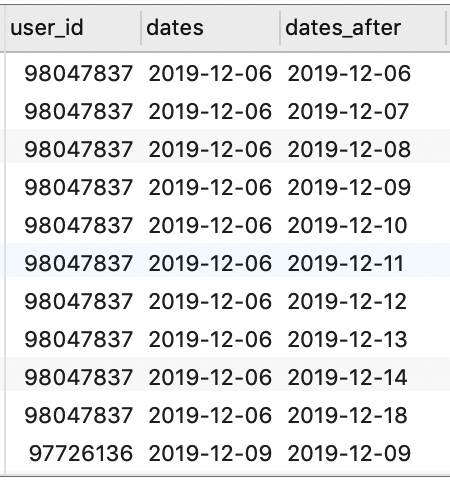
假设我们希望最终得到的数据集中包含以下字段:
- 基准日期
- 活跃用户数
- 1 日留存率
- 2 日留存率
- ……
- 7 日留存率
- 15 日留存率
- 30 日留存率
首先,对于活跃用户数,我们可以在上表的基础上,对基准日期进行分组统计得到:
1
2
3
4
5
6
7
8
9
10
SELECT
a.dates,
COUNT(DISTINCT a.user_id) AS user_count
FROM
(SELECT user_id, dates FROM temp_trade GROUP BY user_id, dates) AS a
LEFT JOIN
(SELECT user_id, dates FROM temp_trade GROUP BY user_id, dates) AS b
ON a.user_id = b.user_id
WHERE b.dates >= a.dates
GROUP BY a.dates;
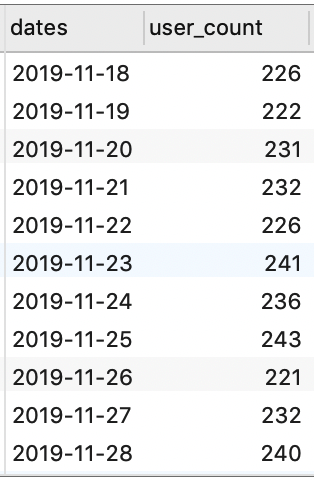
现在,我们已经得到了目标结果集中的前两个字段。显然,后续的 1 日留存率、2 日留存率……30 日留存率的计算模式是相同的。而我们知道,某日留存率 = 当日留存数 / 基准日期活跃数,所以我们先计算对应日期的留存数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
SELECT
a.dates,
COUNT(DISTINCT a.user_id) AS user_count,
COUNT(DISTINCT IF(DATEDIFF(b.dates, a.dates) = 1, b.user_id, NULL)) AS remain_1,
COUNT(DISTINCT IF(DATEDIFF(b.dates, a.dates) = 2, b.user_id, NULL)) AS remain_2,
COUNT(DISTINCT IF(DATEDIFF(b.dates, a.dates) = 3, b.user_id, NULL)) AS remain_3,
COUNT(DISTINCT IF(DATEDIFF(b.dates, a.dates) = 4, b.user_id, NULL)) AS remain_4,
COUNT(DISTINCT IF(DATEDIFF(b.dates, a.dates) = 5, b.user_id, NULL)) AS remain_5,
COUNT(DISTINCT IF(DATEDIFF(b.dates, a.dates) = 6, b.user_id, NULL)) AS remain_6,
COUNT(DISTINCT IF(DATEDIFF(b.dates, a.dates) = 7, b.user_id, NULL)) AS remain_7,
COUNT(DISTINCT IF(DATEDIFF(b.dates, a.dates) = 15, b.user_id, NULL)) AS remain_15,
COUNT(DISTINCT IF(DATEDIFF(b.dates, a.dates) = 30, b.user_id, NULL)) AS remain_30
FROM
(SELECT user_id, dates FROM temp_trade GROUP BY user_id, dates) AS a
LEFT JOIN
(SELECT user_id, dates FROM temp_trade GROUP BY user_id, dates) AS b
ON a.user_id = b.user_id
WHERE b.dates >= a.dates
GROUP BY a.dates;
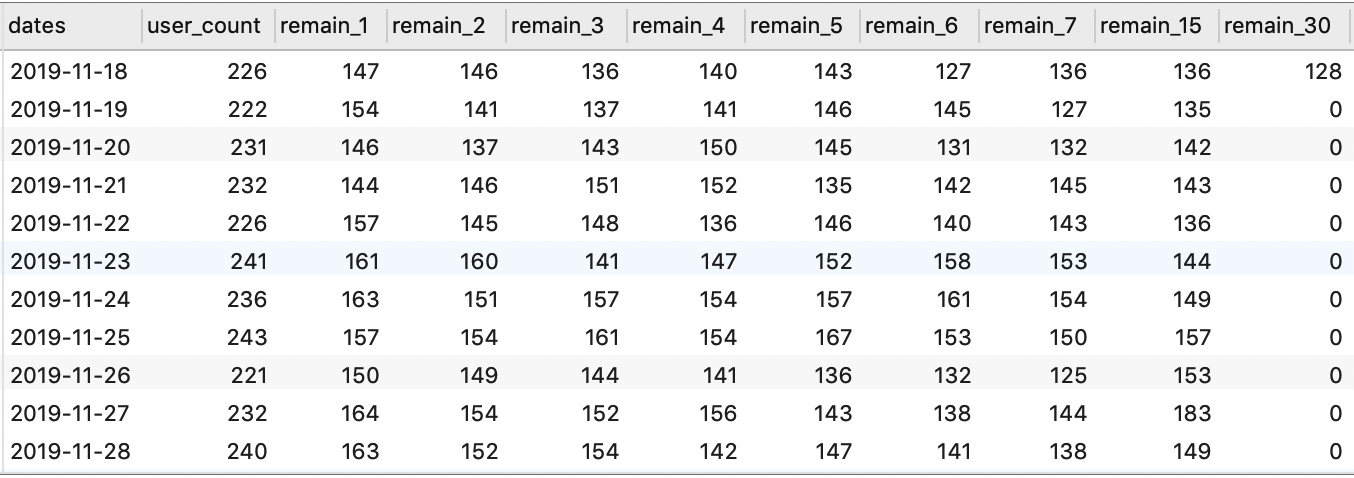
然后,基于某日留存数,我们就可以计算出当日的留存率。为了便于后续计算,我们可以将上面的 SELECT 语句保存为视图(或者通过 WITH AS 语句创建临时表,以便在同一条 SQL 语句内进行重复调用):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
CREATE VIEW user_remain_view AS
SELECT
a.dates,
COUNT(DISTINCT a.user_id) AS user_count,
COUNT(DISTINCT IF(DATEDIFF(b.dates, a.dates) = 1, b.user_id, NULL)) AS remain_1,
COUNT(DISTINCT IF(DATEDIFF(b.dates, a.dates) = 2, b.user_id, NULL)) AS remain_2,
COUNT(DISTINCT IF(DATEDIFF(b.dates, a.dates) = 3, b.user_id, NULL)) AS remain_3,
COUNT(DISTINCT IF(DATEDIFF(b.dates, a.dates) = 4, b.user_id, NULL)) AS remain_4,
COUNT(DISTINCT IF(DATEDIFF(b.dates, a.dates) = 5, b.user_id, NULL)) AS remain_5,
COUNT(DISTINCT IF(DATEDIFF(b.dates, a.dates) = 6, b.user_id, NULL)) AS remain_6,
COUNT(DISTINCT IF(DATEDIFF(b.dates, a.dates) = 7, b.user_id, NULL)) AS remain_7,
COUNT(DISTINCT IF(DATEDIFF(b.dates, a.dates) = 15, b.user_id, NULL)) AS remain_15,
COUNT(DISTINCT IF(DATEDIFF(b.dates, a.dates) = 30, b.user_id, NULL)) AS remain_30
FROM
(SELECT user_id, dates FROM temp_trade GROUP BY user_id, dates) AS a
LEFT JOIN
(SELECT user_id, dates FROM temp_trade GROUP BY user_id, dates) AS b
ON a.user_id = b.user_id
WHERE b.dates >= a.dates
GROUP BY a.dates;
SELECT * FROM user_remain_view;
计算留存率(视图方法):
1
2
3
4
5
6
7
8
9
10
11
12
13
SELECT
dates,
user_count,
CONCAT(ROUND(remain_1 / user_count * 100, 2), '%') AS day_1,
CONCAT(ROUND(remain_2 / user_count * 100, 2), '%') AS day_2,
CONCAT(ROUND(remain_3 / user_count * 100, 2), '%') AS day_3,
CONCAT(ROUND(remain_4 / user_count * 100, 2), '%') AS day_4,
CONCAT(ROUND(remain_5 / user_count * 100, 2), '%') AS day_5,
CONCAT(ROUND(remain_6 / user_count * 100, 2), '%') AS day_6,
CONCAT(ROUND(remain_7 / user_count * 100, 2), '%') AS day_7,
CONCAT(ROUND(remain_15 / user_count * 100, 2), '%') AS day_15,
CONCAT(ROUND(remain_30 / user_count * 100, 2), '%') AS day_30
FROM user_remain_view;
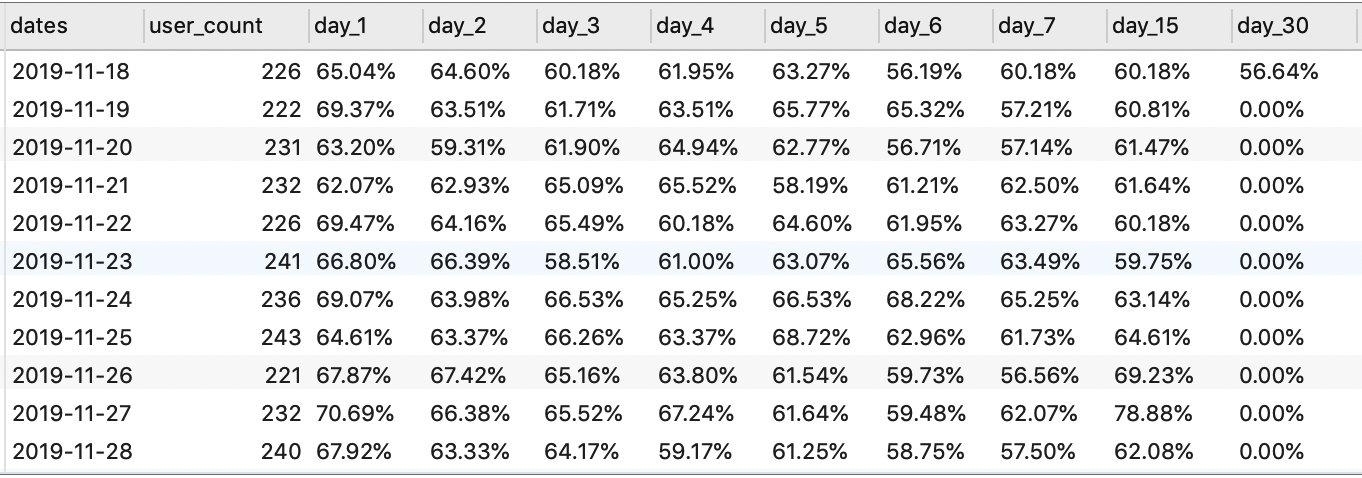
另外,我们也可以通过使用 WITH AS 语句创建临时表计算留存率:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
WITH temp_table_trades AS
(SELECT
a.dates,
COUNT(DISTINCT a.user_id) AS user_count,
COUNT(DISTINCT IF(DATEDIFF(b.dates, a.dates) = 1, b.user_id, NULL)) AS remain_1,
COUNT(DISTINCT IF(DATEDIFF(b.dates, a.dates) = 2, b.user_id, NULL)) AS remain_2,
COUNT(DISTINCT IF(DATEDIFF(b.dates, a.dates) = 3, b.user_id, NULL)) AS remain_3,
COUNT(DISTINCT IF(DATEDIFF(b.dates, a.dates) = 4, b.user_id, NULL)) AS remain_4,
COUNT(DISTINCT IF(DATEDIFF(b.dates, a.dates) = 5, b.user_id, NULL)) AS remain_5,
COUNT(DISTINCT IF(DATEDIFF(b.dates, a.dates) = 6, b.user_id, NULL)) AS remain_6,
COUNT(DISTINCT IF(DATEDIFF(b.dates, a.dates) = 7, b.user_id, NULL)) AS remain_7,
COUNT(DISTINCT IF(DATEDIFF(b.dates, a.dates) = 15, b.user_id, NULL)) AS remain_15,
COUNT(DISTINCT IF(DATEDIFF(b.dates, a.dates) = 30, b.user_id, NULL)) AS remain_30
FROM
(SELECT user_id, dates FROM temp_trade GROUP BY user_id, dates) AS a
LEFT JOIN
(SELECT user_id, dates FROM temp_trade GROUP BY user_id, dates) AS b
ON a.user_id = b.user_id
WHERE b.dates >= a.dates
GROUP BY a.dates)
SELECT
dates,
user_count,
CONCAT(ROUND(remain_1 / user_count * 100, 2), '%') AS day_1,
CONCAT(ROUND(remain_2 / user_count * 100, 2), '%') AS day_2,
CONCAT(ROUND(remain_3 / user_count * 100, 2), '%') AS day_3,
CONCAT(ROUND(remain_4 / user_count * 100, 2), '%') AS day_4,
CONCAT(ROUND(remain_5 / user_count * 100, 2), '%') AS day_5,
CONCAT(ROUND(remain_6 / user_count * 100, 2), '%') AS day_6,
CONCAT(ROUND(remain_7 / user_count * 100, 2), '%') AS day_7,
CONCAT(ROUND(remain_15 / user_count * 100, 2), '%') AS day_15,
CONCAT(ROUND(remain_30 / user_count * 100, 2), '%') AS day_30
FROM temp_table_trades;
6.1.2 RFM 模型分析
RFM 是 3 个指标的缩写:
- R(Recency)表示最近一次消费时间间隔;
- F(Frequency)表示消费频率;
- M(Monetary)表示消费金额。
通过以上 3 个指标对用户进行分类的方法称为 RFM 模型分析。
不同业务对各指标的定义不同,具体需要根据业务场景和需求灵活定义。各指标与用户价值之间的关系如下:
- 对于最近一次消费时间间隔(R),上一次消费时间离得越近,也就是 R 的值越小,用户价值越高;
- 对于消费频率(F),消费频率越高,也就是 F 的值越大,用户价值越高;
- 对于消费金额(M),消费金额越高,也就是 M 的值越大,用户价值越高。
将这 3 个指标 按照价值 由低到高排序,并将其作为坐标轴,我们可以将用户空间分割为 8 个象限,对应下图中的 8 类用户:

于是,我们可以得到以下用户分类规则:
| 用户分类 | 最近一次消费时间间隔(R) | 消费频率(F) | 消费金额(M) |
|---|---|---|---|
| 1. 重要价值用户 | 高 | 高 | 高 |
| 2. 重要发展用户 | 高 | 低 | 高 |
| 3. 重要保持用户 | 低 | 高 | 高 |
| 4. 重要挽留用户 | 低 | 低 | 高 |
| 5. 一般价值用户 | 高 | 高 | 低 |
| 6. 一般发展用户 | 高 | 低 | 低 |
| 7. 一般保持用户 | 低 | 高 | 低 |
| 8. 一般挽留用户 | 低 | 低 | 低 |
注意:上表中各指标的高低代表的是其反映出的用户价值高低,而非指标本身的数值大小。
利用 RFM 模型,我们可以将用户按照价值进行分类,对不同价值的用户采取不同的运营策略,将公司的有限资源发挥出最大效用,从而实现 精细化运营。
具体步骤:
- 计算 R、F、M 的值。一般涉及 3 个数据字段:用户 ID、消费时间、消费金额。
- 给 R、F、M 值按照用户价值打分(例如,最近一次消费时间越近,用户价值越高,R 项分值就越高),一般采用 5 分制。
- 计算用户价值平均值,即分别计算 R、F、M 得分的平均值。
- 用户分类。将各用户的 R、F、M 得分分别与各自的平均值进行比较,然后按照上面的分类规则表对用户进行分类。
1)RFM 模型:R 部分
R 指标分析:根据每个用户最近一次购买时间,给出相应的分数。
这里我们可以分两步:
- 获取每个用户的最近购买时间;
- 计算每个用户最近购买时间距离参照日期相差几天,根据相差的天数进行打分。
注意,参照日期需要在所有购买日期之后,这里我们可以选取 2019-12-18 作为参照日期。
另外,我们这里采用 5 分制,通过计算最近一次购买日期距离参照日期的天数,如果:
- <= 2,打 5 分;
- <= 4,打 4 分;
- <= 6,打 3 分;
- <= 8,打 2 分;
- 其他,打 1 分。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
-- R 指标分析:根据每个用户最近一次购买时间,给出相应的分数
-- 1. 建立 R 视图:统计每个用户的最近购买时间
DROP VIEW IF EXISTS user_recency_view;
CREATE VIEW user_recency_view AS
SELECT
user_id,
MAX(dates) AS recent_buy_time
FROM temp_trade
WHERE behavior_type = 2
GROUP BY user_id;
-- 2. 建立 R 评分视图:计算每个用户最近购买时间距离参照日期 '2019-12-18' 的天数,
-- 根据距离天数进行打分:<=2 5分;<=4 4分;<=6 3分;<=8 2分;其他 1分
DROP VIEW IF EXISTS r_score_view;
CREATE VIEW r_score_view AS
SELECT
user_id,
recent_buy_time,
DATEDIFF('2019-12-18', recent_buy_time) AS date_distance,
CASE
WHEN DATEDIFF('2019-12-18', recent_buy_time) <= 2 THEN 5
WHEN DATEDIFF('2019-12-18', recent_buy_time) <= 4 THEN 4
WHEN DATEDIFF('2019-12-18', recent_buy_time) <= 6 THEN 3
WHEN DATEDIFF('2019-12-18', recent_buy_time) <= 8 THEN 2
ELSE 1
END AS r_score
FROM user_recency_view;
SELECT * FROM r_score_view;

2)RFM 模型:F 部分
F 指标分析:计算每个用户在一定时间内的消费频率,给出相应分数。
这里,我们以整个数据集中的时间跨度为准,即不限制具体时间段,统计每个用户在数据集中的所有消费次数。
同样,我们这里采用 5 分制,通过对用户分组,计算每个用户有多少条消费记录,如果:
- <= 2,打 1 分;
- <= 4,打 2 分;
- <= 6,打 3 分;
- <= 8,打 4 分;
- 其他,打 5 分。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
-- F 指标计算:统计每个用户的消费次数,给出相应的分数
-- 1. 建立 F 视图:统计每个用户的消费次数
DROP VIEW IF EXISTS user_frequency_view;
CREATE VIEW user_frequency_view AS
SELECT
user_id,
COUNT(user_id) AS buy_frequency
FROM temp_trade
WHERE behavior_type = 2
GROUP BY user_id;
-- 2. 建立 F 评分视图:基于购买次数对用户进行打分
-- 按照购买次数评分:<=2 1分;<=4 2分;<=6 3分;<=8 4分;其他 5分
DROP VIEW IF EXISTS f_score_view;
CREATE VIEW f_score_view AS
SELECT
user_id,
buy_frequency,
CASE
WHEN buy_frequency <= 2 THEN 1
WHEN buy_frequency <= 4 THEN 2
WHEN buy_frequency <= 6 THEN 3
WHEN buy_frequency <= 8 THEN 4
ELSE 5
END AS f_score
FROM user_frequency_view;
SELECT * FROM f_score_view;
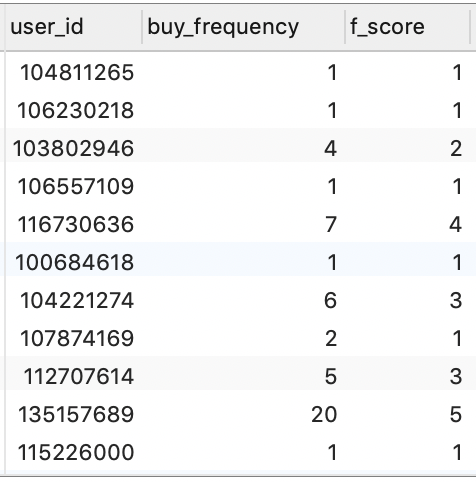
3)整合结果
由于该数据集中没有包含消费金额相关的字段信息,这里我们将仅基于最近一次消费时间间隔(R)和消费频率(F)建⽴ RFM 模型,并且将用户分为以下 4 类:
- 重要⾼价值客户:指最近⼀次消费较近⽽且消费频率较⾼的客户;
- 重要唤回客户:指最近⼀次消费较远且消费频率较⾼的客户;
- 重要深耕客户:指最近⼀次消费较近且消费频率较低的客户;
- 重要挽留客户:指最近⼀次消费较远且消费频率较低的客户。
我们将按照最近⼀次消费时间间隔的均值和消费频率的均值来确定 R 和 F 得分的⾼、低分界线。
1
2
3
4
-- 计算 R 得分和 F 得分的均值
SELECT
(SELECT AVG(r_score) FROM r_score_view) AS r_avg,
(SELECT AVG(f_score) FROM f_score_view) AS f_avg;

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
-- 拿到每个用户的 R 得分和 F 得分(两表关联 r_score_view 和 f_score_view),然后与均值对比,得到各用户类型
DROP VIEW IF EXISTS rfm_inall_view;
CREATE VIEW rfm_inall_view AS
SELECT
r.user_id,
r.r_score,
f.f_score,
CASE
WHEN r.r_score > 2.7939 AND f.f_score > 2.2606 THEN '重要高价值客户'
WHEN r.r_score < 2.7939 AND f.f_score > 2.2606 THEN '重要唤回客户'
WHEN r.r_score > 2.7939 AND f.f_score < 2.2606 THEN '重要深耕客户'
WHEN r.r_score < 2.7939 AND f.f_score < 2.2606 THEN '重要挽留客户'
END AS user_class
FROM r_score_view AS r INNER JOIN f_score_view AS f ON r.user_id = f.user_id;
SELECT * FROM rfm_inall_view;
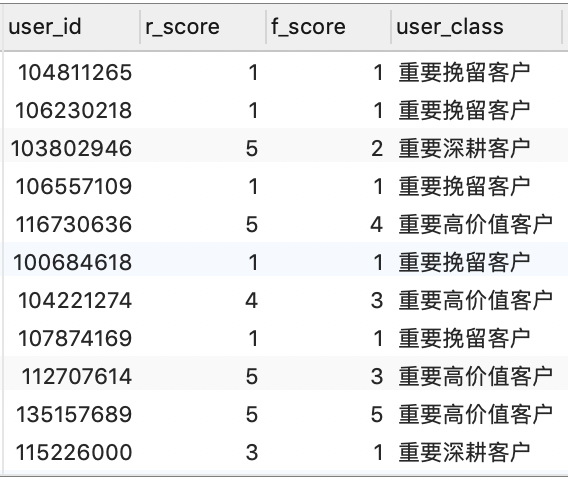
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
-- 统计各用户的用户类型、最近一次购买时间间隔、购买频率
DROP VIEW IF EXISTS user_class_view;
CREATE VIEW user_class_view AS
WITH temp_rf AS (
SELECT
r.user_id,
date_distance,
buy_frequency
FROM r_score_view r INNER JOIN f_score_view f ON r.user_id = f.user_id)
SELECT
rfm.user_id,
user_class,
date_distance,
buy_frequency
FROM rfm_inall_view AS rfm LEFT JOIN temp_rf AS trf ON rfm.user_id = trf.user_id;
SELECT * FROM user_class_view;
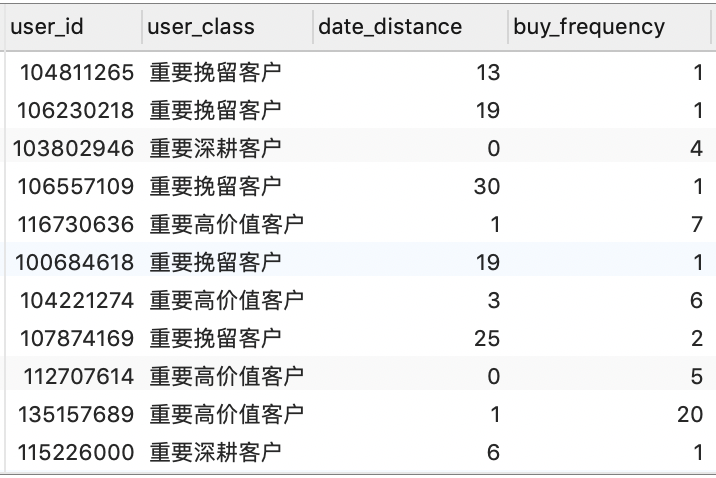
1
2
3
4
5
6
7
8
-- 统计各个用户类型下的用户数量、最近一次购买的平均时间间隔、平均消费频率
SELECT
user_class,
COUNT(user_id) AS user_count,
AVG(date_distance) AS avg_date_distance,
AVG(buy_frequency) AS avg_buy_frequency
FROM user_class_view
GROUP BY user_class;
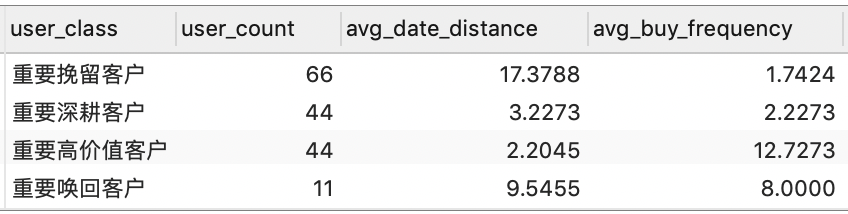
现在,我们已经完成了对用户群体的分类,这实际上相当于在一定程度上对用户进行画像,接下来就可以针对不同用户群体采取不同的运营策略。当然,后续具体运营策略的设计和实施就属于运营人员的工作范围了。
6.2 商品指标体系
前面我们分析了 “人货场” 中与 “人(用户)” 相关的指标,现在我们来分析与 “货(商品)” 相关的指标。
我们将从下面两个维度来进行分析:
- 按照商品进行分组统计:商品的点击量(浏览 / 曝光)、收藏量、加购量(加入购物车的次数)、购买次数、购买转化率(该商品的所有⽤户中有购买转化的⽤户占⽐)。
- 按照商品品类进行分组统计:对应品类的点击量、收藏量、加购量、购买次数、购买转化率。
6.2.1 商品指标统计
1
2
3
4
5
6
7
8
9
10
11
12
-- 统计各商品的点击量、收藏量、加购量、购买次数、购买转化率
SELECT
item_id,
SUM(IF(behavior_type = 1, 1, 0)) AS pv,
SUM(IF(behavior_type = 4, 1, 0)) AS favorite,
SUM(IF(behavior_type = 3, 1, 0)) AS cart,
SUM(IF(behavior_type = 2, 1, 0)) AS purchase,
CONCAT(ROUND(COUNT(DISTINCT IF(behavior_type = 2, user_id, NULL)) /
COUNT(DISTINCT user_id) * 100, 2), '%') AS purchase_ratio
FROM temp_trade
GROUP BY item_id
ORDER BY purchase DESC, purchase_ratio DESC;
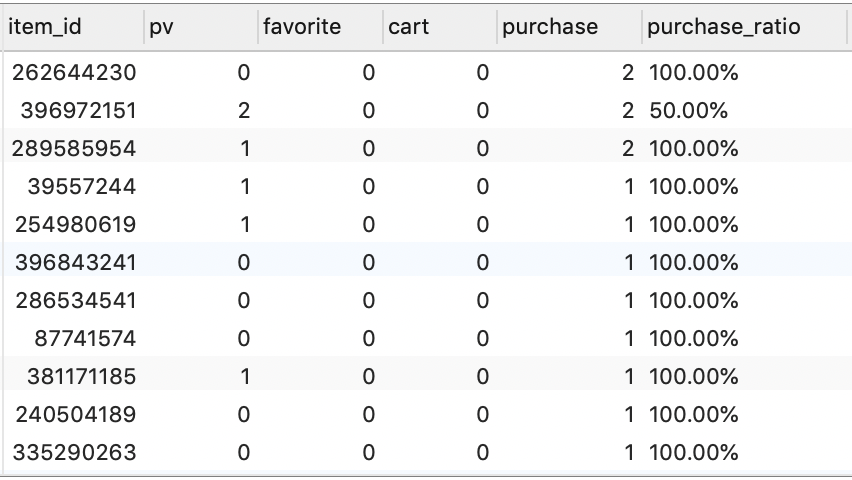
注意:由于这里我们的数据集比较有限,计算得到的转化率的值的集合可能比较小。
6.2.2 商品品类指标统计
1
2
3
4
5
6
7
8
9
10
11
12
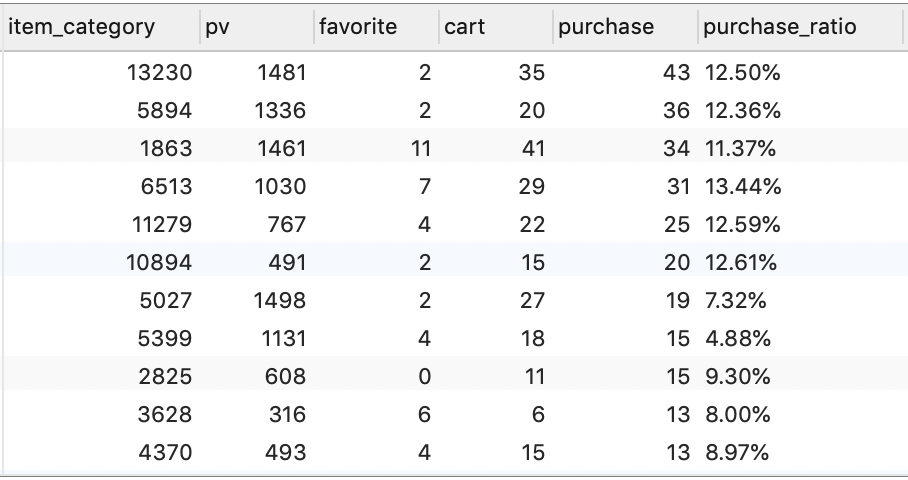
-- 统计各品类的点击量、收藏量、加购量、购买次数、购买转化率
SELECT
item_category,
SUM(IF(behavior_type = 1, 1, 0)) AS pv,
SUM(IF(behavior_type = 4, 1, 0)) AS favorite,
SUM(IF(behavior_type = 3, 1, 0)) AS cart,
SUM(IF(behavior_type = 2, 1, 0)) AS purchase,
CONCAT(ROUND(COUNT(DISTINCT IF(behavior_type = 2, user_id, NULL)) /
COUNT(DISTINCT user_id) * 100, 2), '%') AS purchase_ratio
FROM temp_trade
GROUP BY item_category
ORDER BY purchase DESC, purchase_ratio DESC;
6.3 平台指标体系
前面我们分析了 “人货场” 中的 “人(用户)” 和 “货(商品)” 的相关指标,接下来我们来分析与 “场(平台)” 相关的指标。
同样,我们从以下两个维度进行分析:
-
从平台角度来看用户的行为:按日统计整个平台的点击量、收藏量、加购量、购买次数、购买转化率。
-
用户行为路径分析:用户在购买商品的时候,可能会经历一系列的操作,例如:“浏览 $\rightarrow$ 收藏 $\rightarrow$ 加入购物车 $\rightarrow$ 支付购买”;或者 “浏览 $\rightarrow$ 支付购买”,又或者 “浏览 $\rightarrow$ 加入购物车 $\rightarrow$ 支付购买” 等等,我们将这些统称为行为路径。这里,我们可以以最近一次的 “支付购买” 行为为基准,并往前推 4 个操作行为,由此得到一条由 5 个操作组成的行为路径,然后统计每条行为路径下的用户数量。
6.3.1 平台用户指标统计
1
2
3
4
5
6
7
8
9
10
11
12
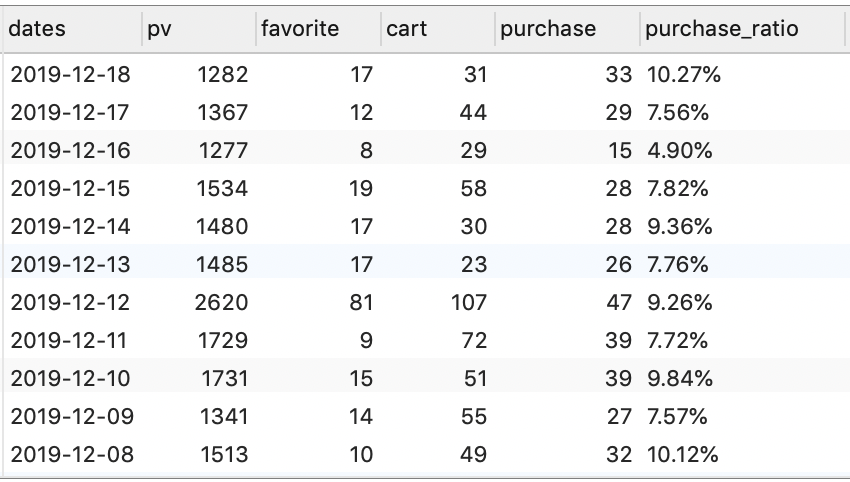
-- 统计平台每日的点击量、收藏量、加购量、购买次数、购买转化率
SELECT
dates,
SUM(IF(behavior_type = 1, 1, 0)) AS pv,
SUM(IF(behavior_type = 4, 1, 0)) AS favorite,
SUM(IF(behavior_type = 3, 1, 0)) AS cart,
SUM(IF(behavior_type = 2, 1, 0)) AS purchase,
CONCAT(ROUND(COUNT(DISTINCT IF(behavior_type = 2, user_id, NULL)) /
COUNT(DISTINCT user_id) * 100, 2), '%') AS purchase_ratio
FROM temp_trade
GROUP BY dates
ORDER BY dates DESC;
6.3.2 用户行为路径分析
如前所述,这里我们以最后的 “支付购买” 为基准,并往前推 4 个操作行为,由此得到一条由 5 个操作组成的行为路径,然后统计每条行为路径下的用户数量。
这里各行为代号可以从用户行为字段 behavior_type 获取:
- 1:曝光
- 2:购买
- 3:加⼊购物⻋
- 4:加⼊收藏夹
这里的核心步骤是:拼接行为路径。
例如,对于用户张三,其对于 a 商品可能存在以下行为:1、3、2、4、3、1、2。我们从最后的 2(购买)开始,往前推 4 个行为,然后拼接得到一条 “2 $\rightarrow$ 4 $\rightarrow$ 3 $\rightarrow$ 1 $\rightarrow$ 2” 的行为路径。
因此,我们需要:
- 将多个行为并列摆放,即使用窗口函数中的偏移分析函数
LAG()或者LEAD()为各行为分别创建一个字段; - 使用
CONCAT()函数对各行为字段进行拼接,得到行为路径; - 统计各行为路径下的用户数量。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
/*
用户行为拼接准备
使用偏移分析函数 LAG() 或者 LEAD() 为各行为分别创建一个字段,这里涉及到分组和排序:
1. 将 PARTITION BY 后的字段指定为 user_id 和 item_id
2. 将 ORDER BY 后的字段指定为 date_time
注意,这里我们排序字段指定的是 date_time 而不是 dates,因为同一天内可能存在多个行为,需要考虑它们之间的顺序。
另外,由于要统计的是最近一次购买行为对应的路径,可以使用排序函数 RANK() 按照 date_time 字段进行倒排序,然后取第一条记录。
*/
DROP VIEW IF EXISTS path_base_view;
CREATE VIEW path_base_view AS
SELECT a.* FROM
(SELECT
user_id,
item_id,
LAG(behavior_type, 4) OVER (PARTITION BY user_id, item_id ORDER BY date_time) AS lag_4,
LAG(behavior_type, 3) OVER (PARTITION BY user_id, item_id ORDER BY date_time) AS lag_3,
LAG(behavior_type, 2) OVER (PARTITION BY user_id, item_id ORDER BY date_time) AS lag_2,
LAG(behavior_type, 1) OVER (PARTITION BY user_id, item_id ORDER BY date_time) AS lag_1,
behavior_type,
RANK() OVER (PARTITION BY user_id, item_id ORDER BY date_time DESC) AS rank_number
FROM temp_trade) AS a
WHERE a.rank_number = 1 AND a.behavior_type = 2;
SELECT * FROM path_base_view;
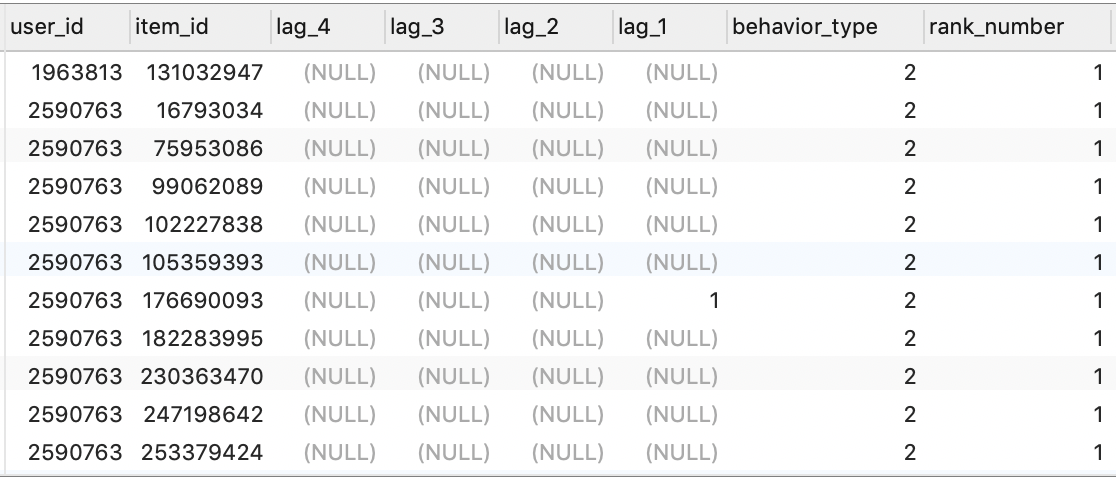
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
-- 拼接行为路径,并统计各行为路径下的用户数量
-- 注意:lag_4 到 lag_1 可能存在 NULL,因此我们用字符串 '空' 来对其进行标记,防止 CONCAT 函数输出 NULL 值。
SELECT
CONCAT(IFNULL(lag_4, '空'), '-',
IFNULL(lag_3, '空'), '-',
IFNULL(lag_2, '空'), '-',
IFNULL(lag_1, '空'), '-',
behavior_type) AS behavior_path,
COUNT(DISTINCT user_id) AS user_count
FROM path_base_view
GROUP BY
CONCAT(IFNULL(lag_4, '空'), '-',
IFNULL(lag_3, '空'), '-',
IFNULL(lag_2, '空'), '-',
IFNULL(lag_1, '空'), '-',
behavior_type)
ORDER BY user_count DESC;

7. 结论
至此,我们已经分析完了 “人”、“货”、“场” 三个维度下的若干指标。接下来我们将对相关结论进行梳理。
7.1 用户分析
用户分析中,我们有一个非常重要的指标,就是 UV(独立访客数)。我们每天会对 UV 进行统计,通过对 UV 进行异常分析,可以发现一些问题。例如,我们之前按日期对 UV 进行过数量统计,我们可以通过下面的折线图来观察其变化趋势:
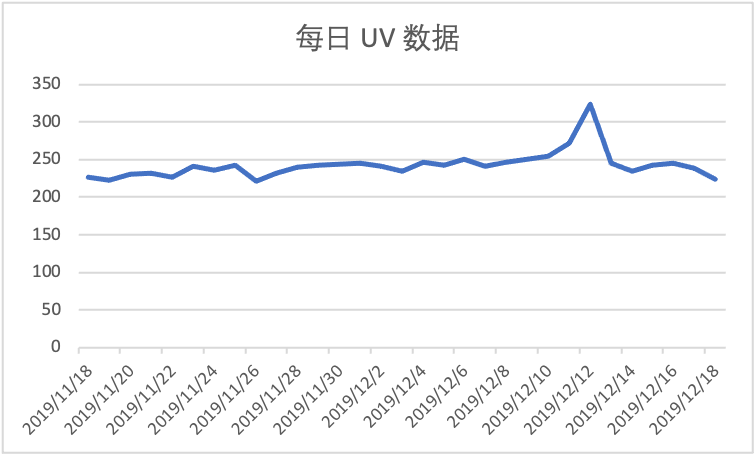
可以看到,每日的 UV 数据图中,存在一个非常明显的波峰,它对应于一个特殊的日期 2019-12-12,即 “双十二”。通常,数据中的这种波峰属于一个异常点,但是这里的这个异常点是由一个已知因素造成的,因为 “双十二” 属于购物节,当天访问量增加属于正常情况。可见,通过分析 UV 曲线,我们确实可以观察到一些现象。
同时,我们还可以对 UV 数据的周环比进行分析。例如,假设今天是周三,我们可以拿今天的 UV 数据和上周三的 UV 数据进行对比,具体计算方式为:(本周三 UV - 上周三 UV)/ 上周三 UV。为什么我们要比较周环比(和一周前的数据相比),而不是和前一天的数据相比呢?因为前一天的数据时间间隔太短,比较起来意义不大。同样,我们可以绘制 UV 的周环比折线图观察其变化趋势:
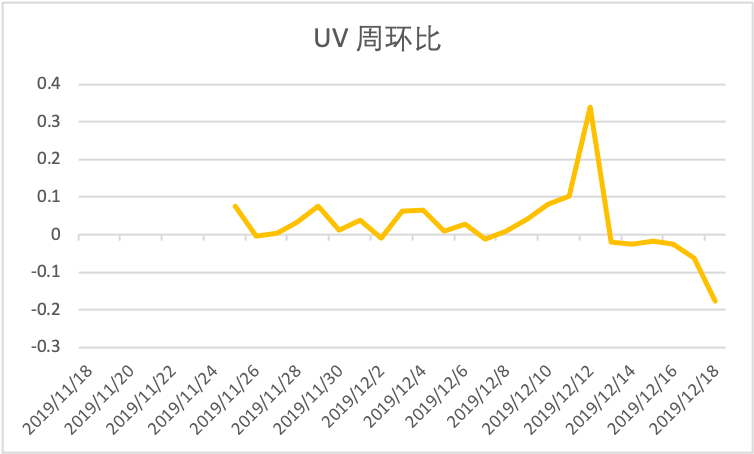
一般来说,周环比的数据往往是大于 0 的,代表用户数量呈上升趋势。但是,从图中可以看到,11⽉26⽇、12⽉2⽇、12⽉7⽇的数据均小于 0,说明这几天的用户数相比一周前有所减少,因此我们需要结合其他数据进一步分析其下降的原因。
通常可能的原因有:
- 内部问题:产品 BUG(⽹站 bug 影响用户体验)、策略问题(周年庆活动结束了)、营销问题(代⾔⼈换了)等;
- 外部问题:竞品活动问题(其他平台⼤酬宾)、政治环境问题(进⼝商品限制)、舆情⼝碑问题(平台商品爆出质量问题)等。
但是,对于一些特殊的时间段,例如,“双十二” 活动之后周环比下降一般属于正常现象。因为此类活动往往会由于打折促销等因素,会在短期内吸引大量用户关注,从而带来很高的 UV,而大部分用户往往会趁机一次性购买较多产品,因此活动之后一段时间内购物需求会有所下降,这些都属于正常现象。
当然,我们还可以对其他基础指标(例如:浏览深度、留存率等)进行类似的分析工作,此处不再展开赘述。
7.2 精细化运营
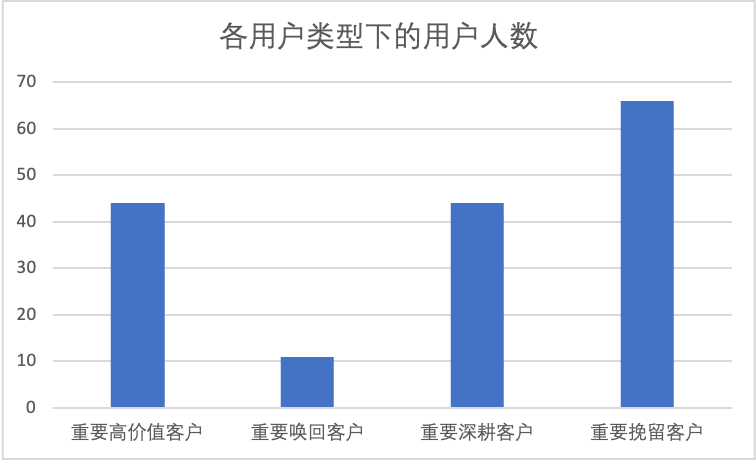
通过之前在 RFM 模型中对的⽤户最近⼀次购买时间、⽤户消费频次分析,我们分拆得到了以下 4 种重要⽤户:
- 重要⾼价值客户:指最近⼀次消费较近⽽且消费频率较⾼的客户;
- 重要唤回客户:指最近⼀次消费较远且消费频率较⾼的客户;
- 重要深耕客户:指最近⼀次消费较近且消费频率较低的客户;
- 重要挽留客户:指最近⼀次消费较远且消费频率较低的客户。
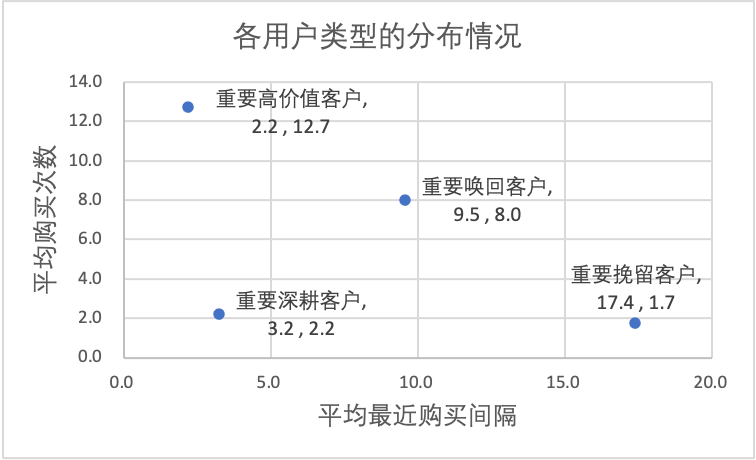
我们可以在后续精细化运营场景中直接使⽤细分⽤户,做差异化运营:
- 对⾼价值客户做 VIP 服务设计,增加⽤户粘性同时通过设计优惠券提升客户消费;
- 对唤回客户做定向⼴告、短信召回策略,尝试召回⽤户;
- 对深耕客户做⼴告、推送刺激,提升消费频次;
- 对挽留客户做优惠券、签到送礼策略,增加挽留⽤户粘性。
7.3 商品分析
我们在之前已经对各商品和各品类的点击量、收藏量、加入购物车的次数、购买次数和购买转化率都进行了统计。
下面是基于购买量统计得到的排名前 10 的商品品类及相关指标:
| item_category | pv | favorite | cart | purchase | purchase_ratio |
|---|---|---|---|---|---|
| 13230 | 1481 | 2 | 35 | 43 | 12.50% |
| 5894 | 1336 | 2 | 20 | 36 | 12.36% |
| 1863 | 1461 | 11 | 41 | 34 | 11.37% |
| 6513 | 1030 | 7 | 29 | 31 | 13.44% |
| 11279 | 767 | 4 | 22 | 25 | 12.59% |
| 10894 | 491 | 2 | 15 | 20 | 12.61% |
| 5027 | 1498 | 2 | 27 | 19 | 7.32% |
| 2825 | 608 | 0 | 11 | 15 | 9.30% |
| 5399 | 1131 | 4 | 18 | 15 | 4.88% |
| 4370 | 493 | 4 | 15 | 13 | 8.97% |
可以看到,其中 ID 为 5027、5399 的商品品类的购买转化率较其余商品品类偏低。因此,需要结合更多数据做进⼀步解读(可能的原因:品类⾃有特性导致⽤户购买较低,⽐如⾮必需品、奢侈品等等)。
7.4 产品功能路径分析
以下为主要购买路径和对应的用户人数:
| behavior_path | user_count |
|---|---|
| 空-空-空-空-2 | 146 |
| 空-空-空-1-2 | 64 |
| 空-空-1-1-2 | 10 |
| 空-空-2-1-2 | 2 |
| 空-空-空-3-2 | 2 |
| 空-1-1-1-2 | 1 |
| 空-空-1-3-2 | 1 |
| 空-空-空-2-2 | 1 |
我们可以发现:
- ⽤户多以直接购买为主;
- 添加购物⻋的购买在主要购买路径中数量较少。
也就是说,目前用户在购买商品时对于添加购物车和收藏功能使用频率很低,这说明平台在这两项功能的用户体验方面可能存在一些问题。想象一下,如果每次用户在购买商品时都是直接支付,那么相当于每次只购买了一件商品;而如果用户习惯于使用购物车功能,那么很有可能会每次购买多件商品,从而在平台消费更多金额。
因此,后续对于产品的加入购物车功能和收藏功能还需要结合更多数据做改进⽅案。
以上就是我们根据前面提取的数据指标初步分析出的一些方向性的结果,后续还可以结合更多指标进行更加精细化的深入分析。
8. 产出分析报告
8.1 结论
-
双十二活动效果预热明显:双十二前(11月18-12月8日)日均活跃用户数237人,日均周环比增长2%,用户稳定增长,说明前期活动 预热效果明显;
-
已挖掘出部分高价值用户:已经挖掘出来44个高价值客户、44个重要深耕客户、66个重要挽留用户和11个重要唤回客户。后续运营活 动可以直接使用;
-
头部商品品类基本保持正常转化率:头部商品品类基本保持正常平均转化率10.4%,部分品类’5027‘、’5399‘转化率偏低,需要后续 与商品运营团队沟通方案;
-
购物车转化率偏低:在所有的消费路径中,58%的用户有加入购物车的行为;但仅有0.6%的用户在加入购物车之后发生购买;说明加 入购物车购买转化率偏低的情况,后续与产品团队协商改进建议;
-
每日活跃用户留存率较为稳定,双十二活动效果明显:一般每日活跃用户留存率稳定在 60%到 70%之间,在双十二前几天逐渐上升, 双十二当天达到峰值(80%左右),之后一周逐渐下降到最低点(55%)左右。说明目前活跃用户留存率比较稳定,双十二活动效果明显, 通常用户在双十二活动后一段时间内购物需求有所下降,属于正常现象。建议可以增加购物积分制度,鼓励购物量较大的客户经常消费, 增加其活跃率。
-
不同行为用户的近一月平均留存有所下降,需进一步查找原因:近一月的平均留存曲线从次留的 67.8% 下降至30日留的 56.6%,下降幅度为 11.2%。其中,拉低短期用户留存(14日内)的用户主要为 “仅曝光” 用户;而拉低14日以上留存的用户主要为 “加入收藏夹” 的用户。11月25至12月3日、12月14至17日区间有多次 “加入收藏夹” 的用户留存低于 “仅曝光” 的用户,后续会针对这几天的 “加入收藏夹” 用户做详细拆解,分析留存较低的原因。
8.2 指标、数据说明
-
统计周期:2019年11月18日至2019年12月18日;
-
当日UV:指当日的用户排重计数;
-
重要高价值客户:指最近一次消费较近而且消费频率较高的客户;
-
重要唤回客户:指最近一次消费较远且消费频率较高的客户;
-
重要深耕客户:指最近一次消费较近且消费频率较低的客户;
-
重要挽留客户:指最近一次消费较远且消费频率较低的客户;
-
购买转化率:商品的被购买次数除以所有对商品的行为数;
-
活跃用户留存率:按照日期统计,目标日期的活跃用户数除以基准日期的活跃用户数。
8.3 用户分析部分
8.3.1 双十二后前用户稳步上升
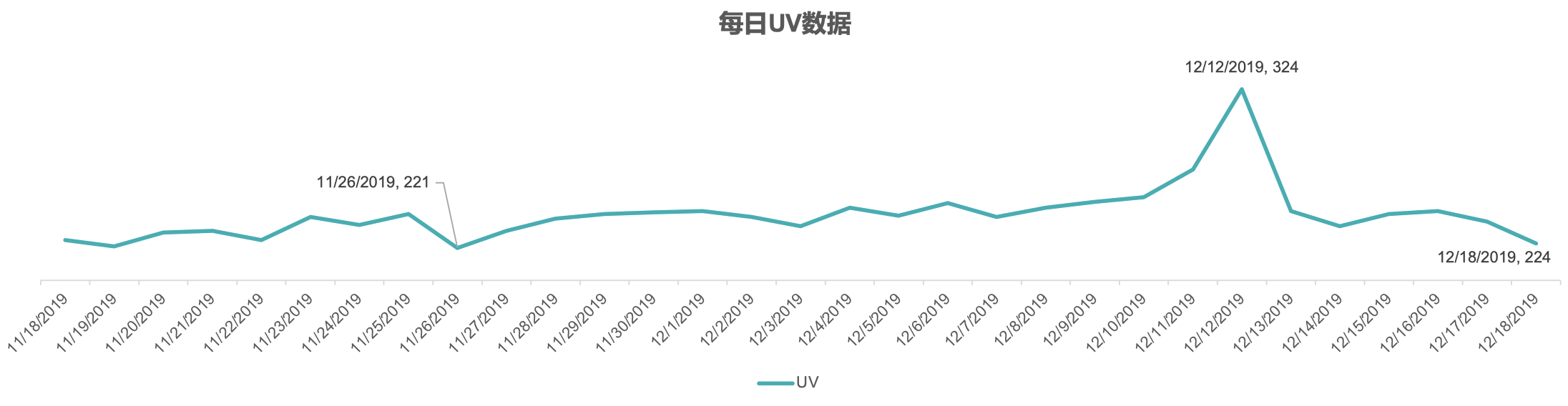
- 双十二前(11月18-12月8日)日均活跃用户数237人,日均周环比增长 2%;
- 双十二当日用户提升至 324 人;
- 双十二后,用户回落。
8.3.2 重点挖掘用户以及后续策略
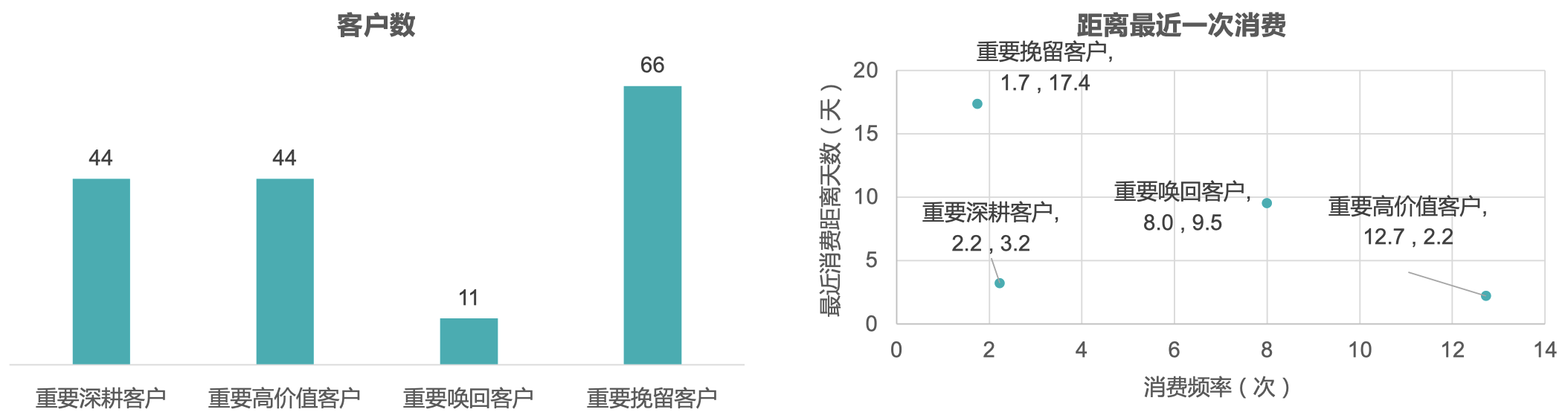
- 共挖掘重要客户 165人;
- 后续工作重点,需要对高价值客户(44人)做 VIP 服务设计,增加用户粘性同时通过设计优惠券提升客户消费;
- 对深耕客户(44人)做广告、推送刺激,提升消费频次;
- 对挽留客户(66人)做优惠券、签到送礼策略,增加挽留用户粘性;
- 对唤回客户(11人)做定向广告、短信召回策略,尝试召回用户。
8.4 商品分析部分
8.4.1 重点维护商品品类
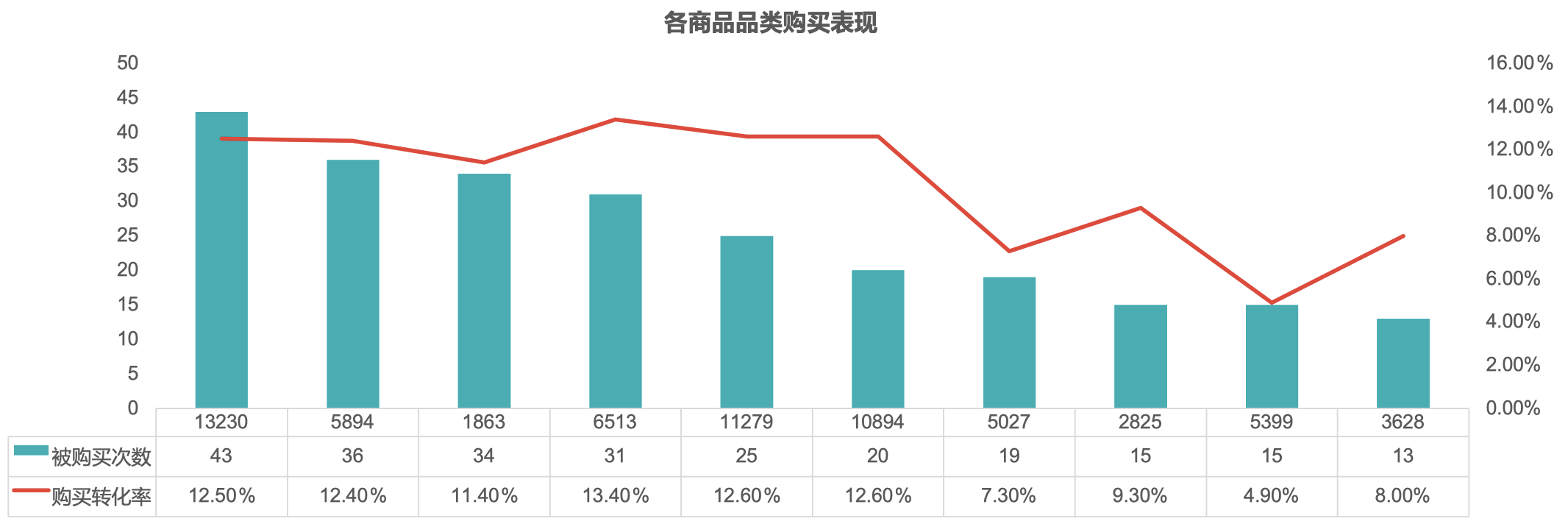
- 该周期内销量靠前的品类如上图所示;
- 以下品类后续需要重点维护;同时,对于 “5027”、“5399” 品类,发现存在曝光转化较低的情况,后续还需要进一步分析曝光较低的原因,提升品类曝光转化。
8.5 产品分析部分
8.5.1 产品主要消费路径
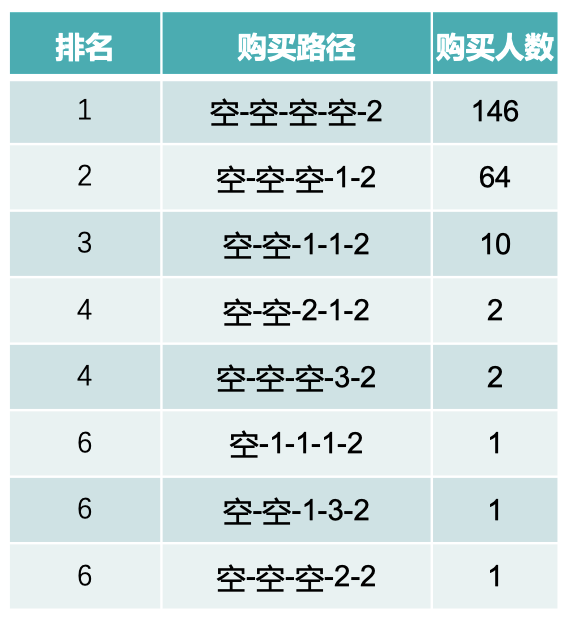
- 上表是产品的主要消费转化路径;
- 可以发现用户以直接购买转化为主;
- 重新购买(第4名、第6名)和加购物车转化(第4、第6名)都有一定的排名;
- 在所有的消费路径中,58% 的用户有加入购物车的行为;但仅有 0.6% 的用户在加入购物车之后发生购买;
- 购物车相关产品的后续改进会与产品经理沟通进行。
8.6 留存分析部分
8.6.1 总体留存分析
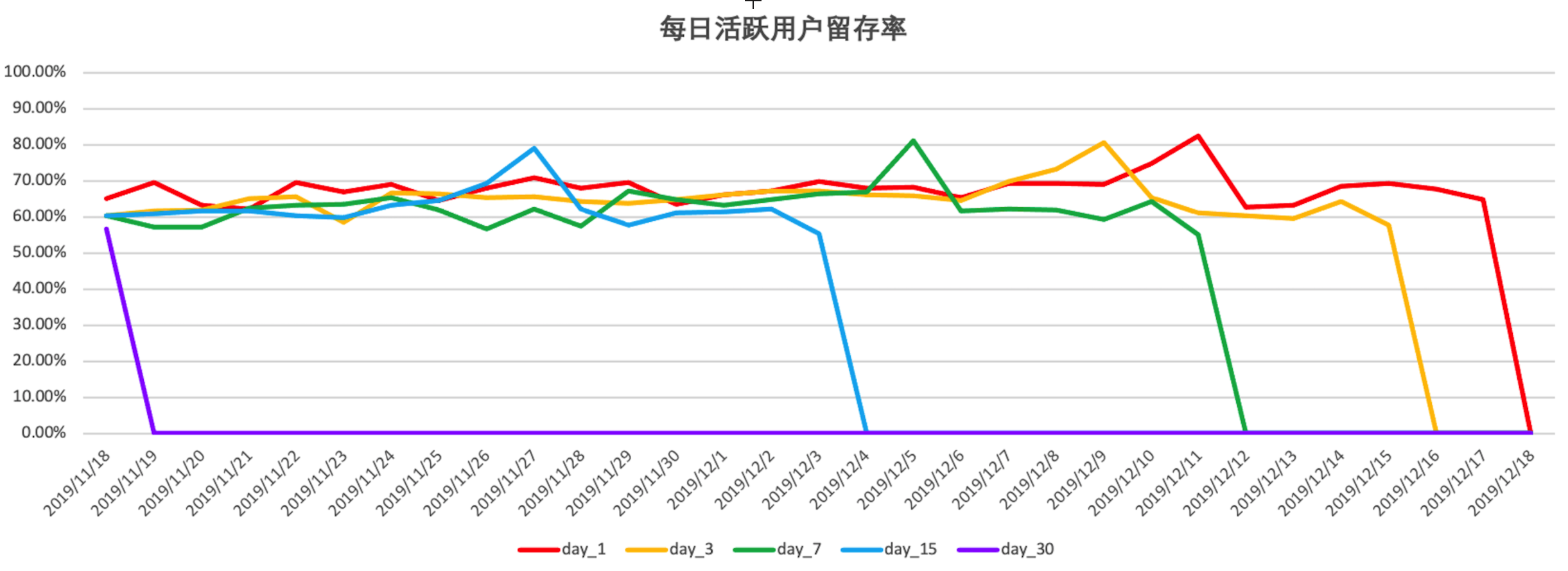
- 上图是每日活跃用户的 1日、3日、7日、15日和 30日留存率,可以看到除去峰值外,一般稳定在 60% 到 70% 之间;
- 注意:图中各曲线最终下降到 0% 并不是真的指留存率降到 0%了,而是指那个日期节点之后的数据是缺失的(即我们的数据只统计到了 2019 年 12 月 18 日);
- 可以看到,各曲线峰值对应日期均为12 月 12 日,说明双十二活动影响导致当日活跃用户留存率达到最大(80%左右),而在此之后一周左右(12 月 18 日)活跃用户留存率降到最低(55%左右),这与前面的每日 UV 数据吻合。
8.6.2 针对不同行为用户的留存分析
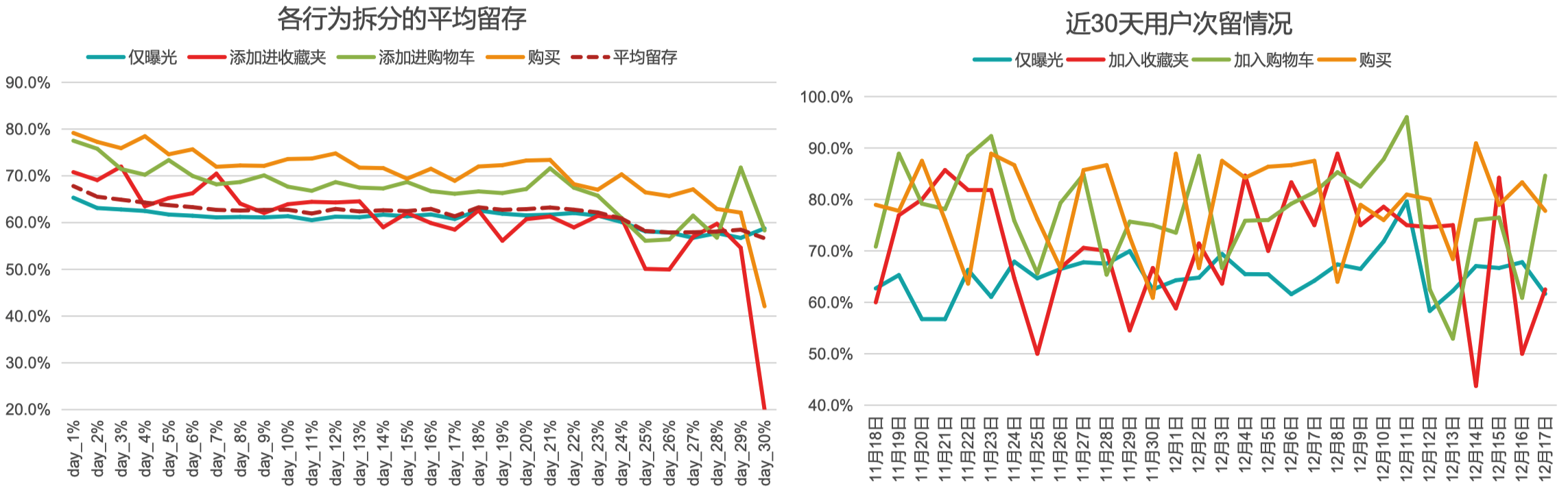
- 计算近一个月的用户平均留存,近一月的平均留存曲线从次留的 67.8% 下降至30日留的 56.6%,下降幅度为 11.2%;
- 拆分不同行为的用户留存曲线(将仅有曝光的用户拆分出来,其余用户不做处理)。可见拉低短期用户留存(14日内)的用户主要为 “仅曝光” 用户;而拉低14日以上留存的用户主要为 “加入收藏夹” 的用户;
- 而分析每类用户的每日次留曲线,可以看出11月25至12月3日、12月14至17日区间有多次 “加入收藏夹” 的用户留存低于 “仅曝光” 的用户,后续会针对这几天的 “加入收藏夹” 用户做详细拆解,分析留存较低的原因。
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。 欢迎转载,并请注明来自:YEY 的博客 同时保持文章内容的完整和以上声明信息!