1. 案例背景
某线下培训机构计划开设数据分析方向的课程,但是对于数据分析行业还没有太全面的了解,因此需要通过在招聘网站上采集数据分析行业的相关招聘信息,对数据分析岗位的市场需求、就业情况和岗位技能做深入调研。目前,爬虫组已采集了与数据分析相关的招聘信息,需要由数据分析组完成分析报告,为企业战略规划提供有力依据。
通常,大公司内部的数据采集、处理和分析流程如下:

目前,公司内已开设的课程方向有:
- 游戏
- 运维
这里,我们不仅需要对数据分析岗位进行分析,还应当将得到的各项结果指标与已有课程方向进行对比分析。例如:对比数据分析、游戏、运维三个方向的招聘需求量、薪资分布等。
本案例中,我们仅以数据分析岗位为例进行分析,其余两个岗位方向的分析过程是类似的。
限定就业地区:由于此培训机构学员入口和出口绝大多数来自一线城市,本次也仅针对北京、上海、广州、深圳这 四个一线城市的数据进行分析。
数据来源:此次招聘数据来源于来自 51job,采集日期:2020-09-15。
2. 问题确认与目标拆解
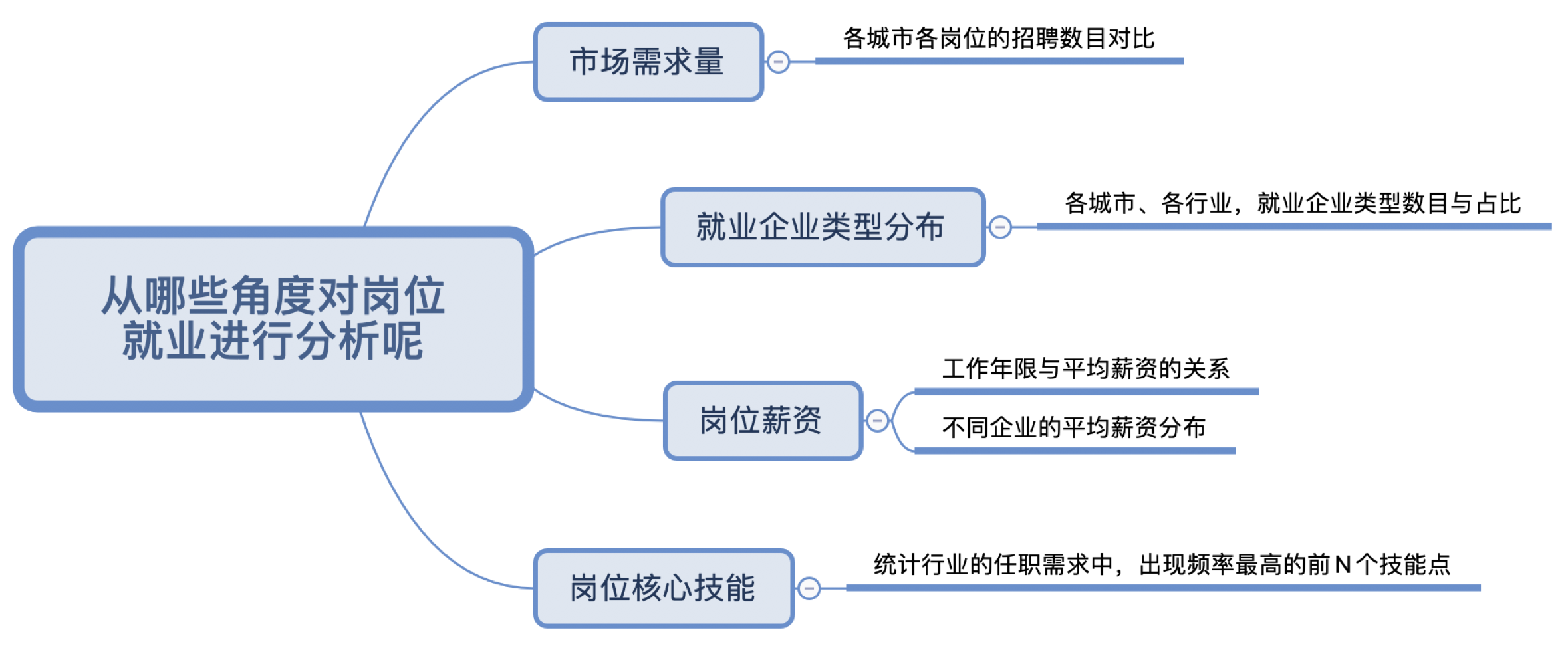
3. 问题解决思路
清洗数据:
-
缺失数据处理(例如:某行数据没有工作名称)
-
重复数据处理(例如:同一个公司发布多个相同岗位)
-
限定招聘地区(一线城市:北京、上海、广州、深圳)
-
过滤周边岗位(例如:某些不相关岗位可能也要求具有数据分析能力)
市场需求量:
-
按城市与岗位进行分组
-
统计岗位招聘量
就业企业类型分布:
-
对企业类型进行分组
-
统计每个企业类型的招聘数量与在总招聘量中的占比
岗位薪资:
-
薪资字段规范化(例如:1-2 万/月 $\Longrightarrow$ 最小值:10000 ,最大值:20000,平均值:15000)
-
按工作年限进行分组,计算每组的薪资平均值
-
按企业类型进行分组,计算每组的薪资平均值
岗位核心技能:
- 建立待评估的岗位技能表
- 统计各个待评估技能在招聘需求中出现的次数
- 获取出现次数最高的前 30 个技能,标记为岗位的核心技能
4. 案例实操
4.1 数据导入
4.1.1 创建数据库
之前案例中我们使用 Navicat 客户端导入数据,这里我们尝试另一种方式:通过终端导入数据。
首先,打开终端,输入如下命令连接到 MySQL 本地服务器:
1
mysql -u root -p
根据提示信息输入密码后,连接成功,会返回如下信息:
1
2
3
4
5
6
7
8
9
10
11
12
13
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 61
Server version: 8.0.14 MySQL Community Server - GPL
Copyright (c) 2000, 2019, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql>
然后,我们创建数据库 recruitment,并指定 UTF-8 编码:
1
CREATE DATABASE recruitment CHARSET utf8;
创建成功,返回如下信息:
1
Query OK, 1 row affected, 1 warning (0.08 sec)
然后,我们退出 MySQL 环境:
1
EXIT;
退出成功,返回如下信息:
1
Bye
4.1.2 导入数据库
在终端中,切换路径到存放我们提前准备好的 recruitment.sql 文件所在的路径下(这里以桌面文件夹为例):
1
cd Desktop
执行以下命令,通过 recruitment.sql 脚本将数据导入到之前创建的 recruitment 数据库中:
1
mysql -u root -p recruitment < recruitment.sql
按照提示输入密码后,等待导入完成。
注意:
-
<后面的recruitment.sql是 SQL 文件的相对路径; -
如果提示找不到指定文件,可以在终端中重新尝试将路径切换到
recruitment.sql所在的文件夹,再次执行导入命令; -
或者,使用
recruitment.sql的绝对路径,例如:mysql -u root -p recruitment < /Users/andy/Desktop/recruitment.sql -
导入操作是在终端中进行的,而不是在 MySQL 环境下;
-
另外,我们也可以将现有数据库导出为 SQL 脚本文件,例如:
mysqldump -u root -p recruitment > /Users/andy/Desktop/recruitment.sql
现在,我们打开 Navicat 客户端,可以看到 recruitment 数据库已经成功创建,并且数据已经成功导入到各表中:
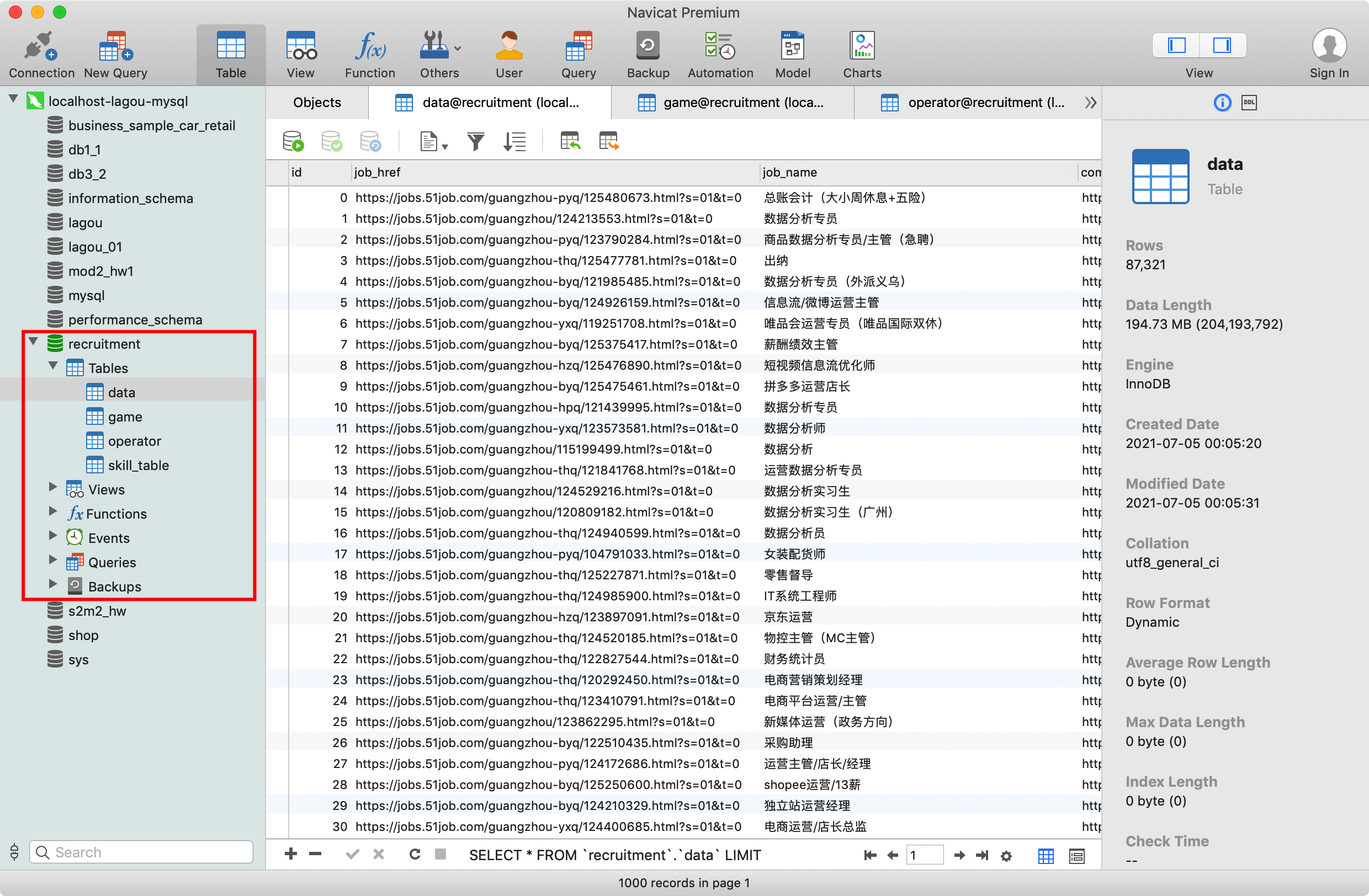
可以看到,recruitment 数据库中现在有以下 4 张表:
data:数据分析岗位的招聘数据game:游戏行业的招聘数据operator:运维方向的招聘数据skill_table:各种技能名称的数据
本案例中,我们主要分析的是数据分析岗位的招聘数据,即 data 表,它包含以下字段,其中除了 id 为 BIGINT 类型之外,其余字段均为 TEXT 类型:
id:职位对应记录的编号job_href:职位链接的 URL(即 51job 上该职位信息页面)job_name:职位名称company_href:招聘该职位的公司链接的 URL(即 51job 上该公司详情页面)company_name:公司名称providesalary_text:薪资workarea:职位所在地区的编码(即 51job 服务器中该地区对应的编码)workarea_text:职位所在地区updatedate:职位信息的更新日期(例如:09-15)companytype_text:公司类型degreefrom:招聘人数workyear:要求的工作年限issuedate:职位信息的更新时间(例如:2020-09-15 11:12:00)parse2_job_detail:职位的详细信息(包含岗位职责、岗位要求、职能类别、关键字等)
4.2 数据清洗
以 “数据分析” 招聘岗位数据为例:
4.2.1 缺失数据处理
首先,我们需要对数据集中的缺失数据进行处理:
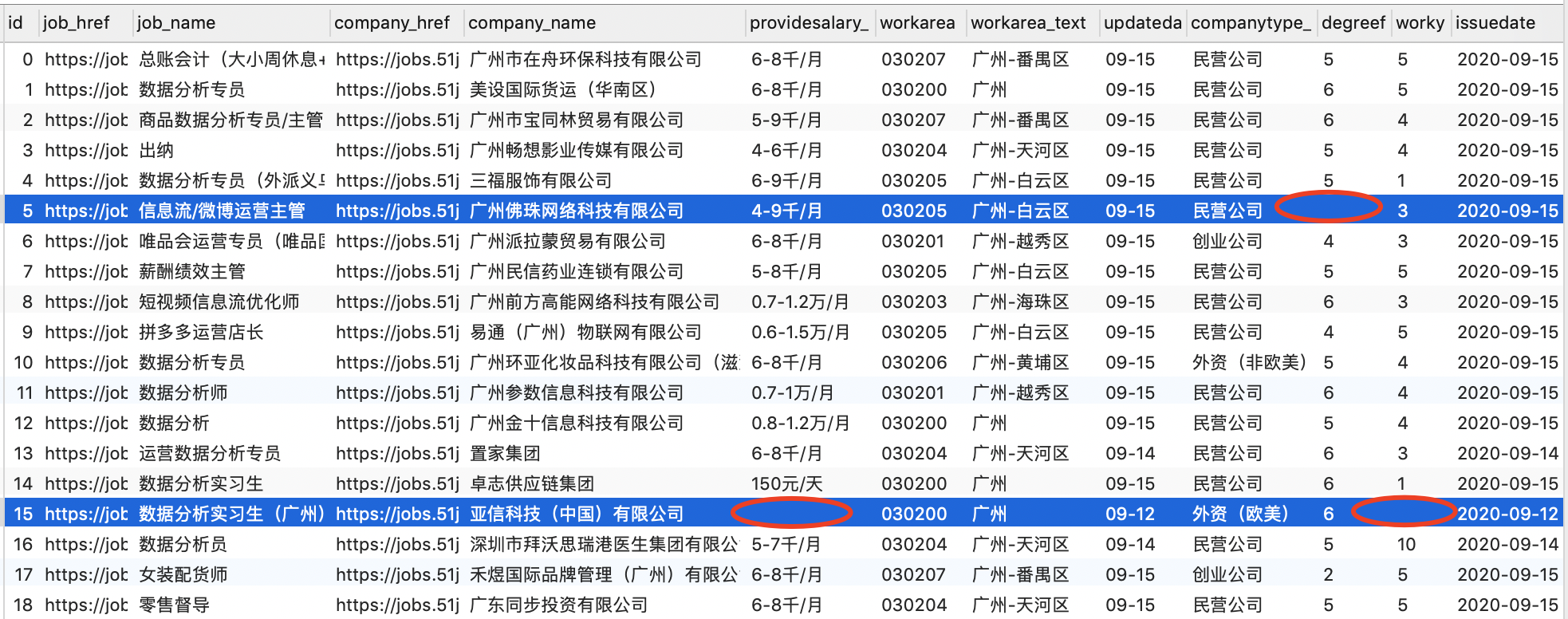
可以看到,有些数据存在部分字段信息缺失,例如上面 id = 5 的记录缺少 degreefrom(招聘人数)相关信息,id = 15 的记录缺少 providesalary_text(薪资)和 workyear(工作年限)相关信息。那么,对于这类记录我们应该保留吗?
一般来说,我们的处理原则是:关键数据不能缺失,但是某些字段的数据是允许缺失的。
例如:
company_href(公司简介链接的 URL)可能在这里并不是特别重要,所以对于该字段的缺失是允许的;- 或者,某记录缺少
workarea(工作地区编码)的信息,但是workarea_text(工作地区名称)的信息是存在的,这种情况也是允许的; - 又或者,某记录的
updatedate(职位信息更新日期)缺失,但是更详细的issuedate(职位更新时间)的信息是存在的,这种情况也是允许的; - 但是,对于一些关键信息字段,比如
job_name(职位名称)、company_name(公司名称)、parse2_job_detail(职位详细信息)等,这些字段的信息是不允许缺失的。
通常情况下,我们需要制定一些规则,以确定哪些字段允许为空,哪些字段不允许为空。
这里,我们采取一种比较简单粗暴的做法:只要有任何字段信息缺失的情况(NULL 或者 ""),就过滤掉该记录。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
-- 缺失数据处理:过滤掉任何包含 NULL 或者空字符串字段的记录
CREATE VIEW v_data_clean_null AS
SELECT *
FROM data
WHERE
job_href IS NOT NULL AND job_href != '' AND
job_name IS NOT NULL AND job_name != '' AND
company_href IS NOT NULL AND company_href != '' AND
company_name IS NOT NULL AND company_name != '' AND
providesalary_text IS NOT NULL AND providesalary_text != '' AND
workarea IS NOT NULL AND workarea != '' AND
workarea_text IS NOT NULL AND workarea_text != '' AND
companytype_text IS NOT NULL AND companytype_text != '' AND
degreefrom IS NOT NULL AND degreefrom != '' AND
workyear IS NOT NULL AND workyear != '' AND
updatedate IS NOT NULL AND updatedate != '' AND
issuedate IS NOT NULL AND issuedate != '' AND
parse2_job_detail IS NOT NULL AND parse2_job_detail != '';
SELECT
(SELECT COUNT(*) FROM data) AS count_before,
(SELECT COUNT(*) FROM v_data_clean_null) AS count_after;

可以看到,原始数据集包含 98069 条记录。过滤掉包含缺失字段的记录后,数据量为 88534 条。
4.2.2 重复数据处理
在完成对缺失数据的处理后,我们还需要处理数据集中包含的重复记录。例如,某公司将同一个职位信息发布了多次,我们应该对这种情况进行去重。
但是,注意这里我们不能仅仅依靠 DISTINCT 完成去重操作,即:
1
SELECT DISTINCT * FROM v_data_clean_null;
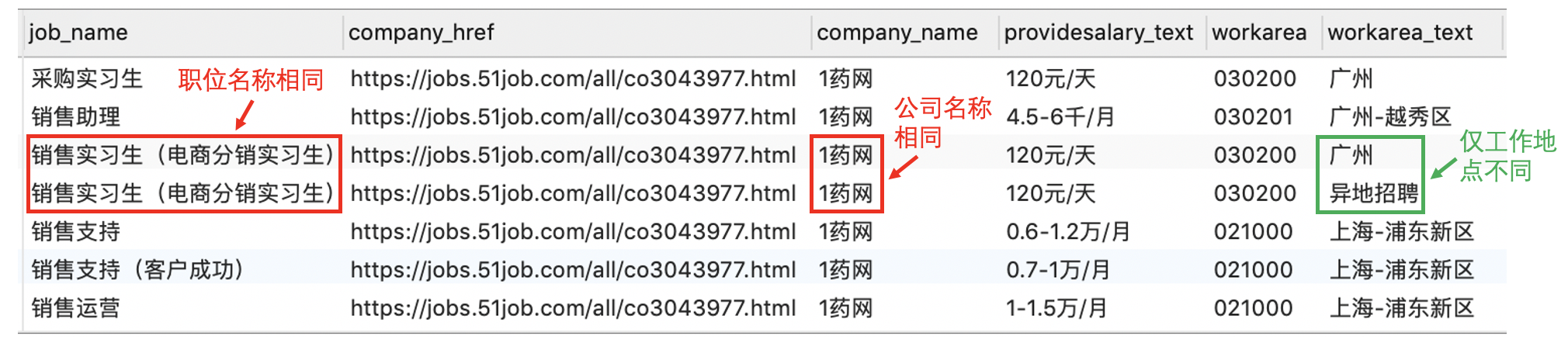
可以看到,图中两条记录的职位名称、公司名称、任职要求等信息都相同,仅仅只有工作地点不同。这种情况下,我们其实应该将其视为同一条招聘信息。
因此,正确的做法是选取一些合适的字段进行去重。这里,我们选择 company_name (公司名称)和 job_name(职位名称)进行去重,即保留该公司发布的关于该职位的最新招聘数据。
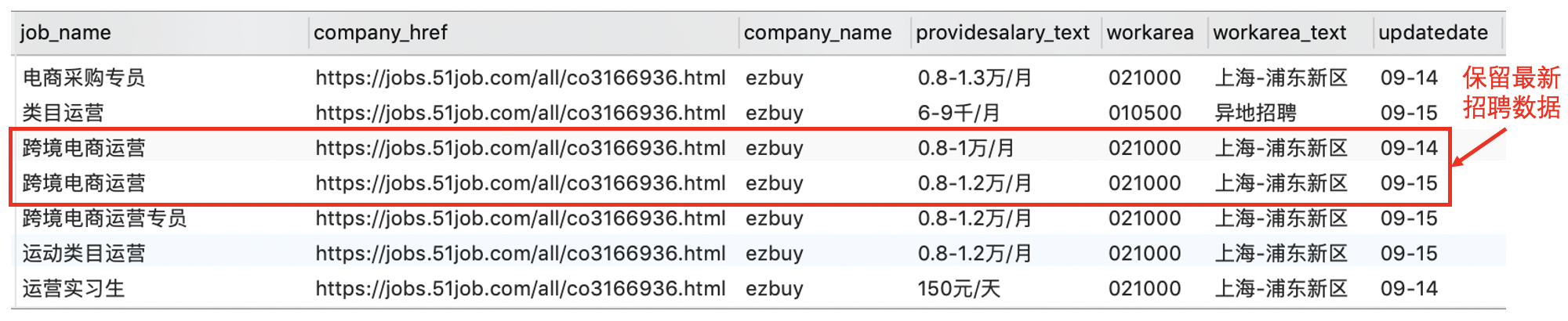
例如,上图中 ezbuy 公司在 9 月 14 日和 9 月 15 日连续发布了两条 “跨境电商运营” 的招聘信息。按照前面我们指定的规则,这种情况属于同一公司发布的同一职位信息,因此我们仅保留最新的那一条记录(即 9 月 15 日发布的那条记录)。
思路:利用窗口函数,按照公司和职位进行分组,按照发布时间进行倒排序,选取排名第一的记录。这种处理方式的好处是即使两条记录的发布时间完全相同,也可以按照排名只选取其中一条记录。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
-- 重复数据处理:利用窗口函数,按照公司和职位进行分组,按照发布时间进行倒排序,选取排名第一的记录
CREATE VIEW v_data_clean_distinct AS
WITH p AS
(SELECT
*,
ROW_NUMBER() OVER (PARTITION BY company_name, job_name ORDER BY issuedate DESC) AS row1
FROM v_data_clean_null)
SELECT
id,
job_href,
job_name,
company_href,
company_name,
providesalary_text,
workarea,
workarea_text,
updatedate,
companytype_text,
degreefrom,
workyear,
issuedate,
parse2_job_detail
FROM p
WHERE row1 = 1;
SELECT
(SELECT COUNT(*) FROM v_data_clean_null) AS count_before,
(SELECT COUNT(*) FROM v_data_clean_distinct) AS count_after;
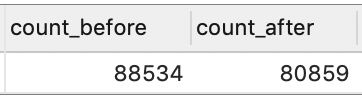
可以看到,去除重复招聘信息之前有 88534 条记录,去重后还剩下 80859 条记录。
4.2.3 限定招聘地区
接下来,我们对招聘地区进行过滤,仅保留来自北京、上海、广州和深圳的记录:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
CREATE VIEW v_data_clean_workplace AS
WITH p AS
(SELECT
*,
CASE
WHEN workarea_text LIKE '%北京%' THEN '北京'
WHEN workarea_text LIKE '%上海%' THEN '上海'
WHEN workarea_text LIKE '%广州%' THEN '广州'
WHEN workarea_text LIKE '%深圳%' THEN '深圳'
-- 这里省略了 ELSE NULL
END AS workplace
FROM v_data_clean_distinct)
SELECT *
FROM p
WHERE p.workplace IS NOT NULL;
SELECT
(SELECT COUNT(*) FROM v_data_clean_distinct) AS count_before,
(SELECT COUNT(*) FROM v_data_clean_workplace) AS count_after;
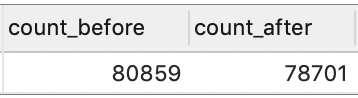
可以看到,对城市进行筛选之前有 80859 条记录,筛选之后还剩下 78701 条记录。
4.2.4 过滤周边岗位
通过在招聘网站上搜索关键词 “数据分析”,搜索引擎会把在招聘信息中出现 “数据分析” 关键词的岗位按照一定的顺序列举出来,故得到了很多并非数据分析主方向、但任职要求中提到了数据分析技能的周边岗位。
那么,如何过滤掉这些周边岗位呢?
- 工作名称中必须出现指定的关键词,本次筛选的条件是:工作名称中要出现 “数据” 一词,否则标记为周边岗位,并过滤掉;
- 对搜索结果的再一次过滤,称为二次检索,大部分的实现方式都是通过包含关键词来判断。但是,通常很难在一开始就选择到合适的关键词,所以需要在已有数据中不断尝试:过滤掉太多记录说明关键词太少、过滤掉太少记录则说明关键词太多或者不准确。找到一个中间值即可。
例如,我们可以通过在工作名称中指定关键词 “数据” 或者 “分析” 来进行二次检索过滤。这里我们考虑两种方式:
- 工作名称中包含关键词 “数据” 或者 “分析”;
- 工作名称中包含关键词 “数据”;
下面我们来看一下这两种过滤方式的差异:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
-- 二次检索:工作名称中包含关键词 “数据” 或者 “分析”
CREATE VIEW v1 AS
SELECT *
FROM v_data_clean_workplace
WHERE job_name LIKE '%数据%' OR job_name LIKE '%分析%';
-- 二次检索:工作名称中包含关键词 “数据”
CREATE VIEW v2 AS
SELECT *
FROM v_data_clean_workplace
WHERE job_name LIKE '%数据%';
-- 对比上面两种方式的差异,即仅包含关键词 “分析” 而不包含 “数据” 的记录
SELECT *
FROM v1
WHERE v1.id NOT IN (SELECT id FROM v2);
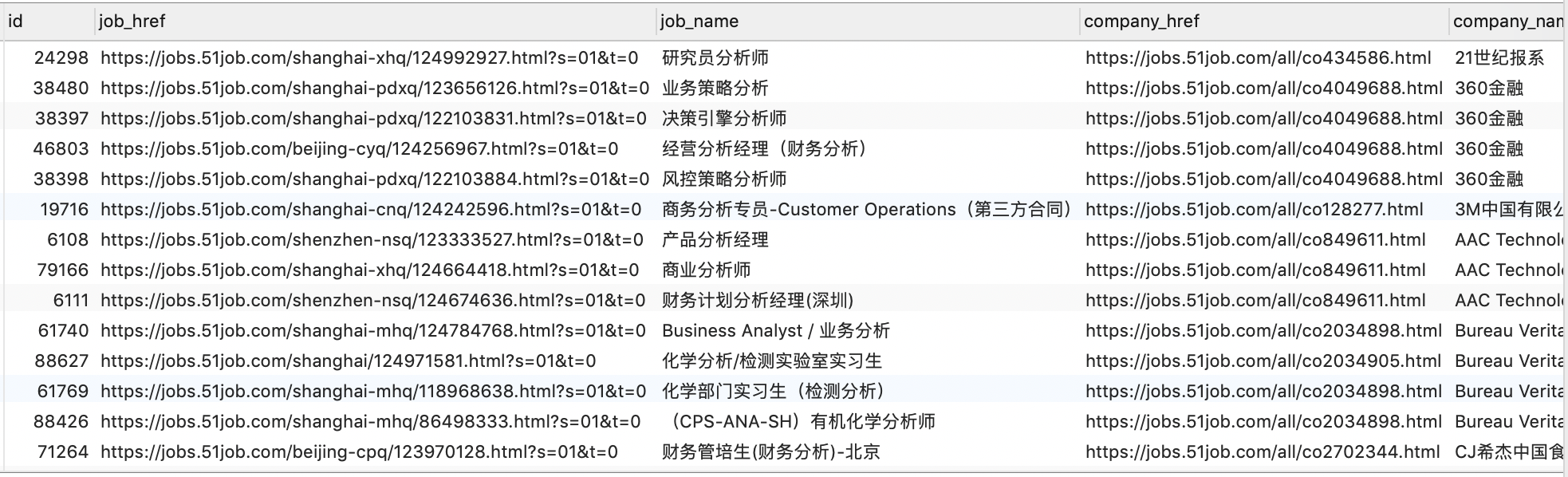
可以看到,仅包含关键词 “分析” 而不包含 “数据” 的记录中,有一些并非我们所期望的结果,例如:化学部门实习生(检测分析)、(CPS-ANA-SH)有机化学分析师等。对于这种情况,我们可以通过对关键词 “分析” 加以一定的约束条件来改善结果,例如:
1
2
3
SELECT *
FROM v_data_clean_workplace
WHERE job_name LIKE '%数据%' OR (job_name LIKE '%分析%' AND job_name LIKE '%市场%');
本案例中,我们采取较为简单的方式,即只选取工作名称中包含关键词 “数据” 的记录:
1
2
3
4
5
6
7
8
9
-- 过滤周边岗位:通过关键词 “数据” 进行二次检索
CREATE VIEW v_data_clean_jobname AS
SELECT *
FROM v_data_clean_workplace
WHERE job_name LIKE '%数据%';
SELECT
(SELECT COUNT(*) FROM v_data_clean_workplace) AS count_before,
(SELECT COUNT(*) FROM v_data_clean_jobname) AS count_after;

可以看到,对周边岗位进行过滤之前有 78701 条记录,过滤之后还剩 5417 条记录。
到这里,我们就完成了整个数据清洗的工作流程:
缺失数据处理 $\longrightarrow$ 重复数据处理 $\longrightarrow$ 限定招聘地区 $\longrightarrow$ 过滤周边岗位
由于接下来的分析都是基于上面得到的最终清洗结果,我们重新建立一个名为 v_data_clean 的视图,用于接下来的分析:
1
2
-- 将最终清洗结果保存到视图 v_data_clean
CREATE VIEW v_data_clean AS (SELECT * FROM v_data_clean_jobname);
4.3 市场需求量
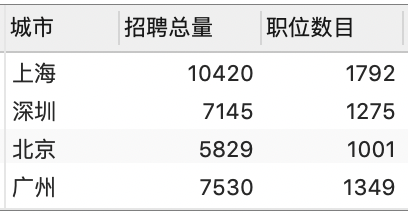
我们将清洗结果按照城市进行分组,然后统计各城市的总的招聘人数和职位数量:
1
2
3
4
5
6
7
8
9
10
-- 各城市的市场需求量分析
CREATE VIEW v_data_market_demand AS
SELECT
workplace AS '城市',
SUM( degreefrom ) AS '招聘总量',
COUNT(*) AS '职位数目'
FROM v_data_clean
GROUP BY workplace;
SELECT * FROM v_data_market_demand;
4.4 招聘企业类型分布
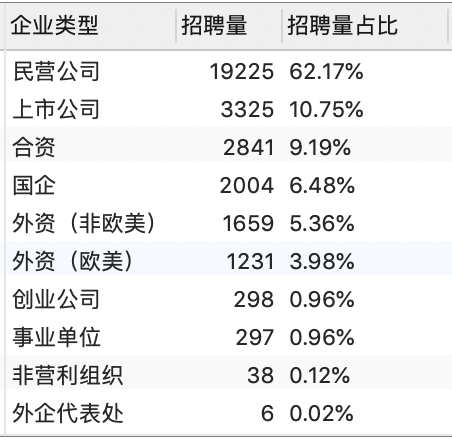
统计各招聘企业的类型、招聘量和招聘量占比。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
-- 招聘企业类型分布
CREATE VIEW v_data_companytype_degree AS
SELECT
companytype_text AS '企业类型',
degreefrom AS '招聘量',
CONCAT(ROUND(degreefrom / sum_degreefrom * 100, 2), '%') AS '招聘量占比'
FROM
(SELECT
companytype_text,
SUM(degreefrom) AS degreefrom
FROM v_data_clean
GROUP BY companytype_text
ORDER BY degreefrom DESC) AS f1,
(SELECT SUM(degreefrom) AS sum_degreefrom FROM v_data_clean) AS f2;
SELECT * FROM v_data_companytype_degree;
4.5 岗位薪资
统计岗位薪资,首先要规范化薪资字段,得到岗位月薪的最大值、最小值、均值。
清洗后的数据:
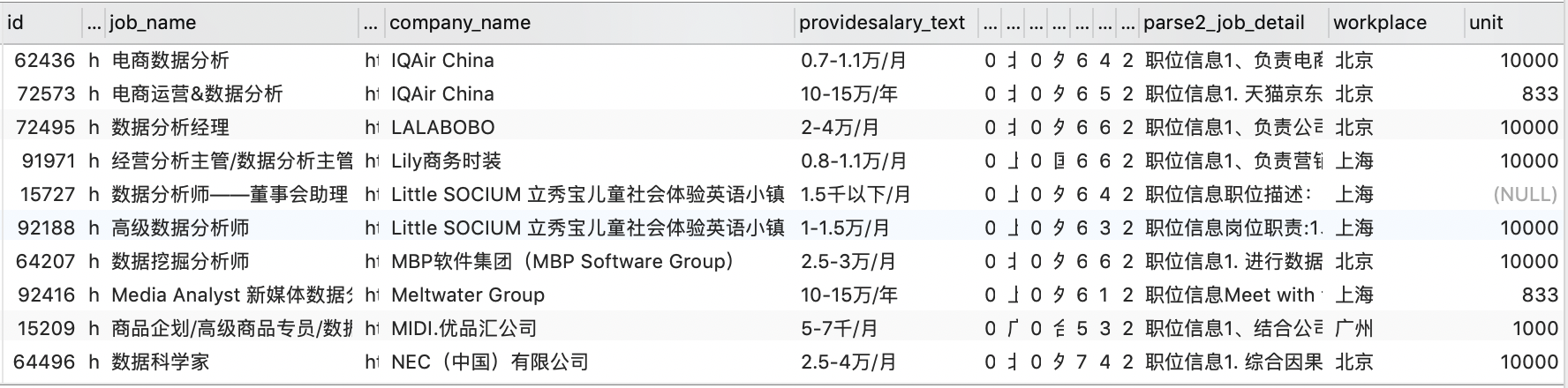
可以看到,目前各记录对于薪资字段 providesalary_text 采用的单位并不统一。我们希望将其转换为三个字段:最高薪资、最低薪资、平均薪资。
4.5.1 提取薪资单位
首先,我们需要提取薪资单位(这里统一以 “元/月” 为标准):
- 7-9千/月 $\Longrightarrow$ 单位 1000(7-9*1000元/月)
- 1.3-2.3万/月 $\Longrightarrow$ 单位 10000(1.3-2.3*10000元/月)
- 14-36万/年 $\Longrightarrow$ 单位 833(14-36*833元/月)
- 像 “150元/天”、“2千以下/月”、“5万以上/月” 这类缺少具体范围的非标准表示方法都不予考虑
1
2
3
4
5
6
7
8
9
10
11
12
13
-- 提取薪资单位
CREATE VIEW v_data_salary_unit AS
SELECT
*,
CASE
WHEN providesalary_text LIKE '%万/月' THEN 10000
WHEN providesalary_text LIKE '%千/月' THEN 1000
WHEN providesalary_text LIKE '%万/年' THEN 833
-- 这里省略了 ELSE NULL
END AS unit
FROM v_data_clean;
SELECT * FROM v_data_salary_unit;
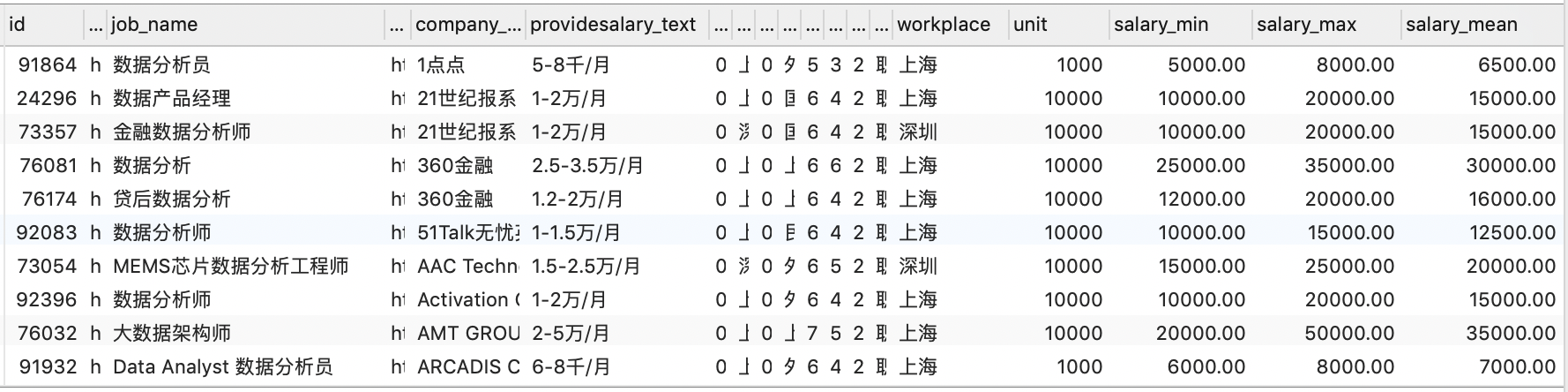
4.5.2 得到工资区间最小值、最大值与均值
首先,利用 SUBSTRING_INDEX(str, delim, count) 函数将薪资字段的数字范围部分切分出来,这里:
- 第一个参数
str代表要切分的字符串 - 第二个参数
delim代表切分标记(即以此作为切分点) - 第三个参数
count表示切分后选取第几段
例如:
SUBSTRING_INDEX('5-8-10', '-', 2)$\Longrightarrow$'8'SUBSTRING_INDEX('5-8千/月', '千/月', 1)$\Longrightarrow$'5-8'
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
-- 得到工资区间最小值、最大值与均值
CREATE VIEW v_data_salary_min_max_mean AS
WITH p AS
(SELECT
*,
CASE
WHEN unit = 1000 THEN
-- 注意:截取薪资最小值后,在乘以单位之前,需要先从字符串类型转换成数值类型
CAST(SUBSTRING_INDEX(SUBSTRING_INDEX(providesalary_text, '千/月', 1), '-', 1)
AS DECIMAL(10, 2)) * unit
WHEN unit = 10000 THEN
CAST(SUBSTRING_INDEX(SUBSTRING_INDEX(providesalary_text, '万/月', 1), '-', 1)
AS DECIMAL(10, 2)) * unit
WHEN unit = 833 THEN
CAST(SUBSTRING_INDEX(SUBSTRING_INDEX(providesalary_text, '万/年', 1), '-', 1)
AS DECIMAL(10, 2)) * unit
END AS salary_min,
CASE
WHEN unit = 1000 THEN
CAST(SUBSTRING_INDEX(SUBSTRING_INDEX(providesalary_text, '千/月', 1), '-', -1)
AS DECIMAL(10, 2)) * unit
WHEN unit = 10000 THEN
CAST(SUBSTRING_INDEX(SUBSTRING_INDEX(providesalary_text, '万/月', 1), '-', -1)
AS DECIMAL(10, 2)) * unit
WHEN unit = 833 THEN
CAST(SUBSTRING_INDEX(SUBSTRING_INDEX(providesalary_text, '万/年', 1), '-', -1)
AS DECIMAL(10, 2)) * unit
END AS salary_max
FROM v_data_salary_unit)
SELECT
*,
ROUND((salary_min + salary_max) / 2, 2) AS salary_mean
FROM p;
SELECT * FROM v_data_salary_min_max_mean;
4.5.3 按工作年限分组,求各组平均薪资
前面我们已经得到了各招聘岗位的最低薪资、最高薪资和平均薪资。现在,我们希望探寻工作年限与平均薪资之间的关系。我们可以按照工作年限分组,然后计算每组的平均薪资,并将结果按照工作年限升序显示:
1
2
3
4
5
6
SELECT
workyear AS '工作年限',
ROUND(AVG(salary_mean), 2) AS '平均薪资'
FROM v_data_salary_min_max_mean
GROUP BY workyear
ORDER BY workyear;
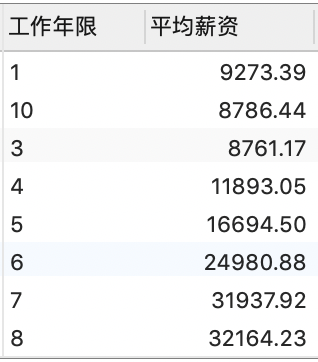
可以看到,虽然我们已经得到了按照工作年限分组后每组的平均薪资,但是排序结果出了点问题:工作年限为 ‘10’ 的组应该排在最后一名,但是现在排在第二名。这是因为这里工作年限的字段是字符串类型,而不是数值类型。
当然,我们可以将工作年限从字符串类型转换为整数类型再进行排序。或者,如果我们不希望对其进行类型转换,那么也可以这样做:
1
2
3
4
5
6
7
8
9
10
-- 按工作年限分组,求各组平均薪资,并将结果按照工作年限升序显示
CREATE VIEW v_data_workyear_salary AS
SELECT
workyear AS '工作年限',
ROUND(AVG(salary_mean), 2) AS '平均薪资'
FROM v_data_salary_min_max_mean
GROUP BY workyear
ORDER BY LENGTH(workyear), workyear;
SELECT * FROM v_data_workyear_salary;

可以看到,平均薪资基本上是随着工作年限的增长而增长的。但是,工作年限为 ‘10’ 的组的平均薪资只有 8786.44,而正常情况下该组平均薪资应该为各组最高。因此,考虑这组数据中可能存在异常值。
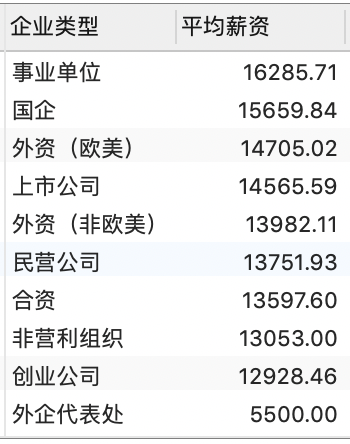
4.5.4 按企业类型分组,计算平均薪资
最后,我们来看一下企业类型和平均薪资的关系。与上面类似,只是这里我们按照企业类型进行分组:
1
2
3
4
5
6
7
8
9
10
-- 按企业类型分组,求各组平均薪资,并将结果按照薪资降序显示
CREATE VIEW v_data_companytype_salary AS
SELECT
companytype_text AS '企业类型',
ROUND(AVG(salary_mean), 2) AS '平均薪资'
FROM v_data_salary_min_max_mean
GROUP BY companytype_text
ORDER BY AVG(salary_mean) DESC;
SELECT * FROM v_data_companytype_salary;
4.6 岗位核心技能
在 skill_table 中预先准备好了 63 个待评估技能点:
1
SELECT * FROM skill_table;

然后,我们需要在招聘信息中找到出现频率最高的那些技能点,即核心技能点。
4.6.1 获取前 30 名高频技能点及其出现频数
我们知道,parse2_job_detail 字段包含该职位的详细信息,包括岗位职责、技能要求等。因此,可以通过在 parse2_job_detail 中检查 skill_table 中列出的各技能是否出现,出现则计为 1 次,然后统计各技能出现的频数即可。
1
2
3
4
5
6
7
8
9
10
11
12
13
-- 统计数据分析岗位中出现频率最高的前 30 个技能点
CREATE VIEW v_data_skill_quantity AS
SELECT
skill,
COUNT(*) AS quantity
FROM
skill_table AS st INNER JOIN v_data_clean AS v
ON v.parse2_job_detail LIKE CONCAT('%', st.skill, '%')
GROUP BY st.skill
ORDER BY quantity DESC
LIMIT 30;
SELECT * FROM v_data_skill_quantity;
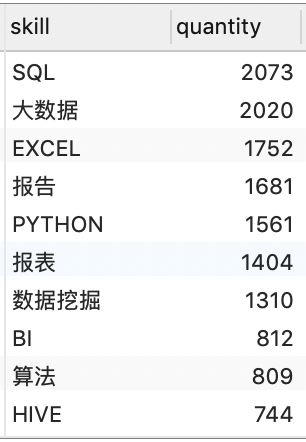
4.6.2 计算前 30 名高频技能点的频率
1
2
3
4
5
6
7
8
9
10
11
CREATE VIEW v_data_skill AS
SELECT
skill AS '技能点',
quantity AS '出现频数',
CONCAT(ROUND(quantity / total_quantity * 100, 2), '%') AS '出现频率'
FROM
v_data_skill_quantity AS f1,
(SELECT COUNT(*) AS total_quantity FROM v_data_clean) AS f2
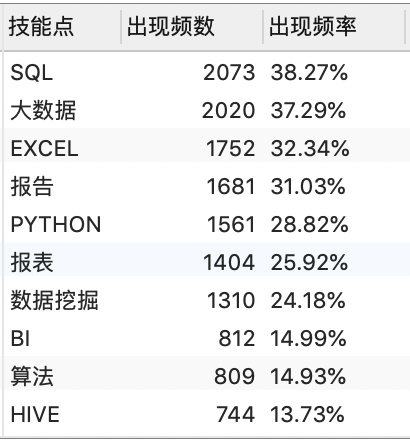
ORDER BY quantity DESC;
SELECT * FROM v_data_skill;
5. 以相同的方式分析 “游戏” 和 “运维” 方向
前面我们已经完成了对 “数据分析” 岗位的招聘情况分析。我们可以按照相同的方式分析其余两个课程方向的情况,即 “游戏” 和 “运维” 方向。两者的数据可以从表 game 和 operator 中获取。
同样,按照以下四个角度进行分析:
- 市场需求量
- 招聘企业类型分布
- 岗位薪资
- 岗位核心技能
之后可以将这两个方向的分析结果与 “数据分析岗位” 的结果进行对比。
需要注意的是,前面我们在数据清洗阶段过滤周边岗位时,采用的是比较简单粗暴的方式:选取 '%数据%' 作为关键字,将 78701 条记录直接过滤到 5417 条。这种方式可能会导致大量本来属于 “数据分析岗位” 的记录被丢弃。例如:可能在原本的 78701 条记录中有 30000 条属于 “数据分析岗位”,而我们通过关键字 '%数据%' 只选取了其中的 5417 条记录进行分析。
虽然,我们只是从整体样本中选取了一少部分比较准确的记录进行分析,但是对于岗位薪资、 就业类型而言,和对总体样本的分析结果相比应该差别不大,因为我们的过滤方式并不具备太大的特殊性。但是,对于市场需求量而言,二者的结果差异可能较大,因为我们忽略了大量本来属于 “数据分析岗位” 的记录,从而导致分析结果不准确。
但是,如前所述,对于这个问题并没有太好的解决方法,只能通过不断尝试调整增加或者减少关键字,观察过滤得到的结果是变得更加准确或者不准。 不过通常来说,这部分工作属于数据清洗,一般会由专门的数据处理工程师来完成。而作为数据分析师,我们的核心职责还是在分析上面。
6. 产出分析报告
6.1 结论
-
上海为数据分析师需求量最大的一线城市;
-
数据分析师的薪资很有竞争力;
-
民营企业对数据分析师有很大需求;
-
数据分析工程师的核心技能。
6.2 指标、数据说明
- 数据说明:
- 取数时间:2020年09月15日;
- 取数来源:51job 招聘网站通过查找 “数据分析”、“游戏”、“运维” 三个关键词获取的全部招聘数据。
- 数据清洗:
- 缺失数据处理:过滤任意字段为空的数据;
- 重复数据处理:同一公司发布的多个相同岗位招聘数据中,仅保留最新发布的岗位;
- 限定工作地点:过滤非北上广深地区的招聘数据;
- 二次检索条件:数据分析、游戏、运维招聘数据的职位名称需分别包含:“数据”、“游戏”、“运维” 关键字。
- 核心技能的判定条件:
- 任职要求中出现一个技能关键词,记该关键词频数加 1,获取频数最高的前 30 个技能关键词,标记为核心技能点。
6.3 上海为数据分析师需求量最大的一线城市
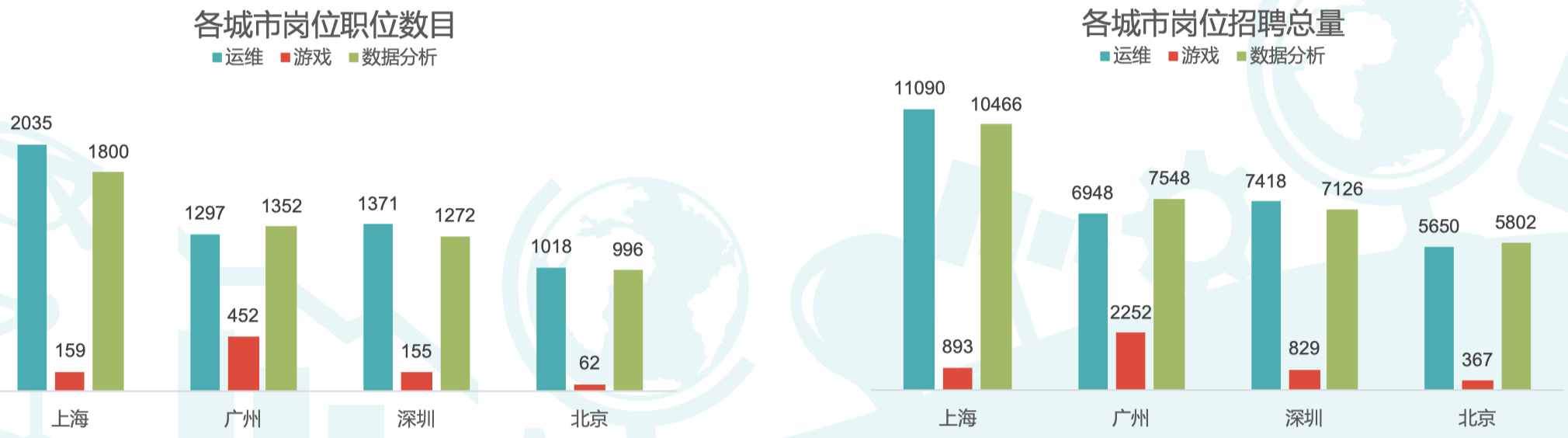
- 一线城市数据分析师岗位共计 5400 个,招聘人数共计 39000 人;
- 其中上海数据分析师岗位需求最多,共需求岗位 1800 个,招聘人数为 10000 人;
- 广州(岗位数 1352 个)、深圳(岗位数 1272 个)、北京(岗位数 996 个)需求紧随其后。
6.4 数据分析师的薪资很有竞争力
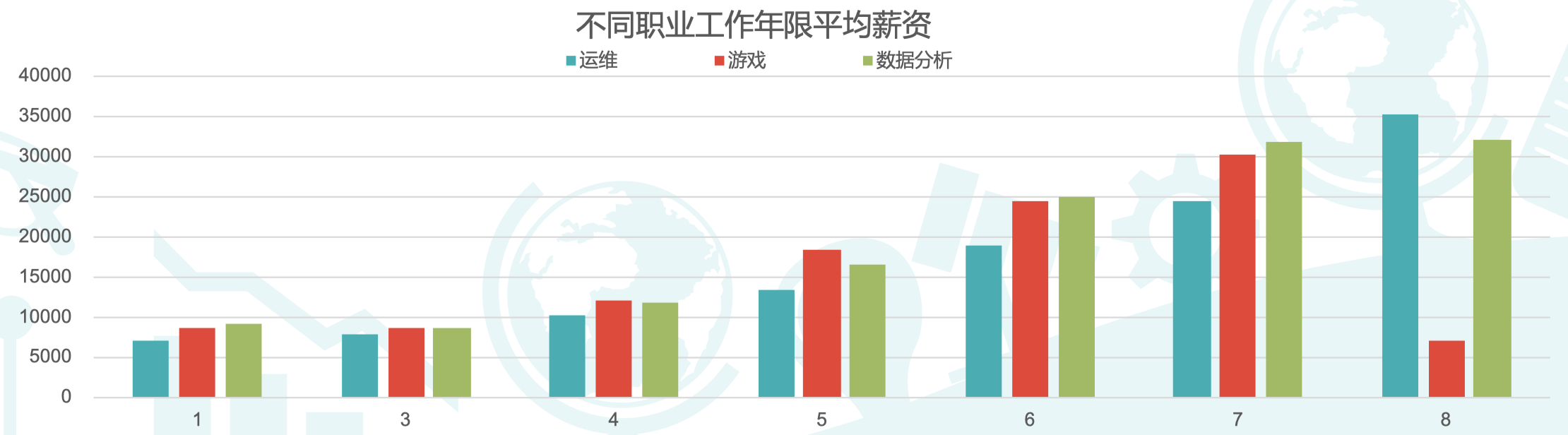
- 在与运维、游戏岗位做不同年限薪资对比中,我们能发现数据分析师的薪资水平在三者中处于较高的水平;
- 数据分析师在工作第 5 年薪资就能达到翻番,工作 7 年薪资能达到应届薪资的 3 倍。
6.5 民营企业对数据分析师有很大需求
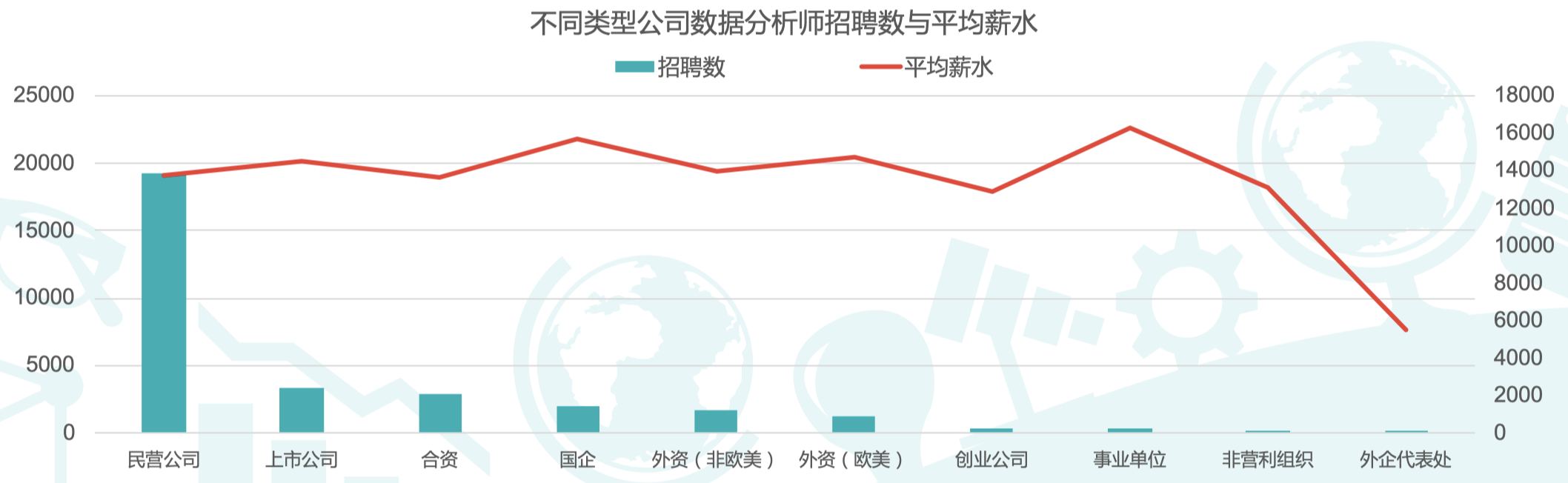
- 分析不同企业对数据分析师的岗位需求,可以看出民营公司对于数据分析师需求量最大;
- 从各类企业数据分析师的平均薪资水平来看,数据分析师的平均薪资在 1.3 万元左右的水平,其中,事业单位的数据分析师平均薪资最高,达 1.6 万元。
6.6 数据分析师需要哪些核心技能
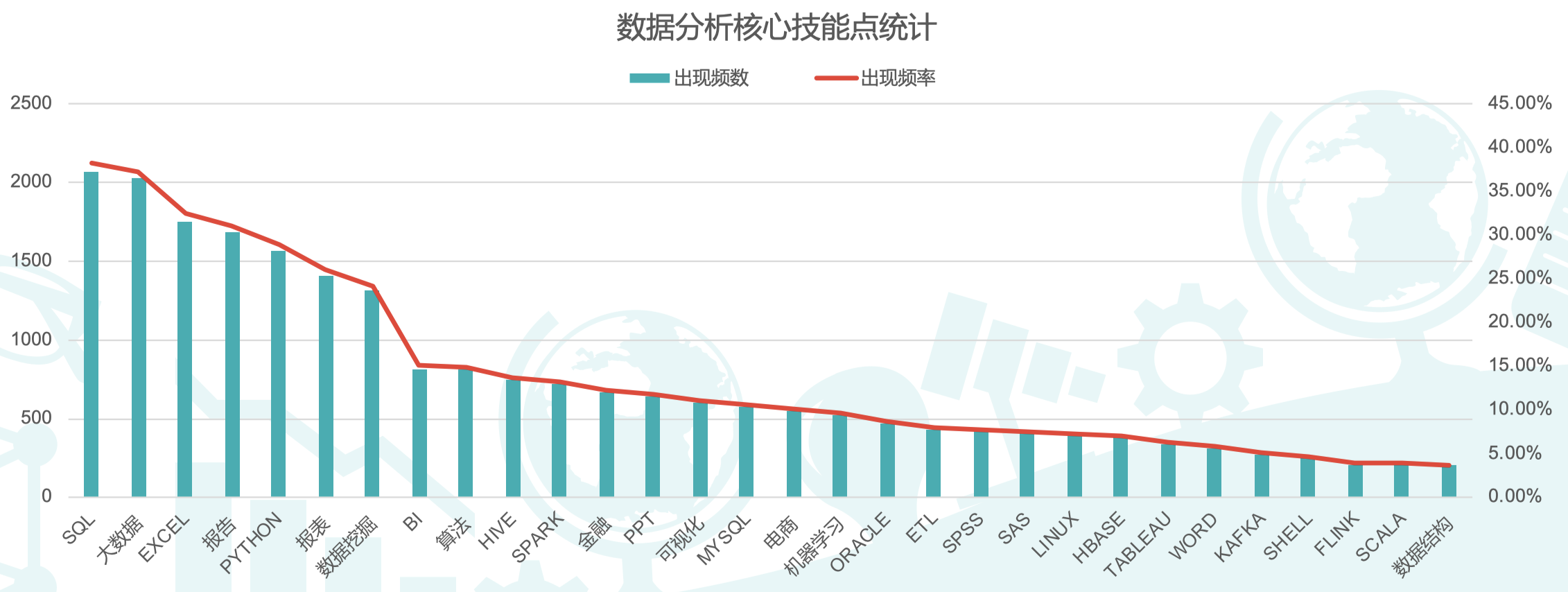
- SQL、大数据、EXCEL、报告撰写、Python语言等技能在数据分析岗位就业中普遍最为刚需;
- 从技能统计可以看出,金融与电商类的项目经验,在数据分析师工作中十分重要。
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。 欢迎转载,并请注明来自:YEY 的博客 同时保持文章内容的完整和以上声明信息!